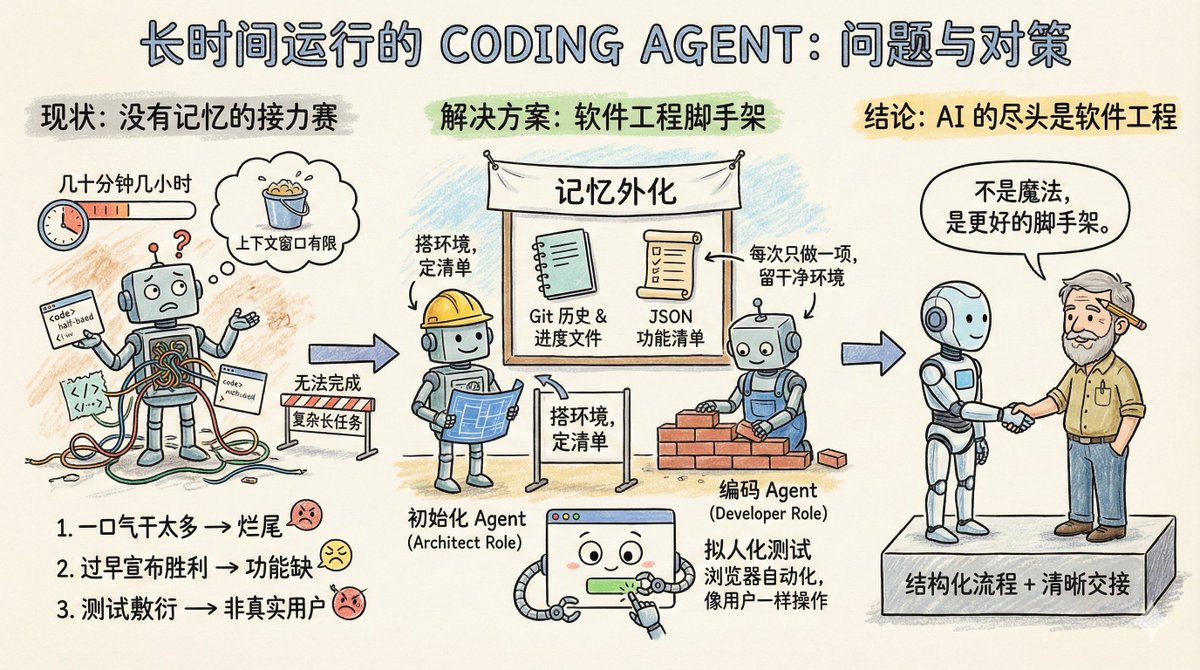
想像一下,一個軟體團隊在做一個大項目,但有個奇怪的規定:每個工程師只能工作幾十分鐘,最多幾小時,幹完就要換一個新的工程師。所以讓這個團隊完成簡單項目任務還行,複雜一點需要長時間運行的項目,例如你讓它複製一個claude .ai,它就做不到。 這其實就是Coding Agent 的現況:沒有記憶,上下文視窗長度有限。所以要它執行長時間任務,它還做不好。 Anthropic 的這篇部落格:《Effective harnesses for long-running agents》,專門討論如何讓Agent 在跨越多個上下文視窗時依然能持續推進任務。 先看Agent 在長任務中遇到的主要問題是什麼? 主要三種: 第一種叫一口氣幹太多。例如你讓Agent 克隆一個claude .ai 這樣的網站,它會試圖一次搞定整個應用程式。結果上下文還沒用完,功能寫了一半,程式碼亂成一鍋粥。下一個會話進來,面對半成品只能做瞪眼,花很多時間猜測前面到底做了什麼。 第二種叫過早宣布勝利。專案做了一部分,後來的Agent 看看環境,覺得好像差不多了,就直接收工。功能缺一大堆也不管。 第三種叫測試敷衍。 Agent 改完程式碼,跑幾個單元測試或curl 一下介面就覺得萬事大吉,根本沒有像真實使用者那樣端到端走一遍流程。 這三種失敗模式的共同點是Agent 不知道全局目標,也不知道該在哪裡停下來、該留下什麼給下一位。 那麼Anthropic 的解決方案是什麼呢? 其實就是軟體工程的一些現成的解決方案:引入類似人類團隊的分工協作機制,將複雜任務拆解成小的可追蹤驗證的任務,清晰的交接機制,並嚴格驗證任務結果 一個初始化Agent,它只在專案啟動時出場一次,任務是搭好專案運行環境:有點像架構師的角色,寫一個init .sh 腳本方便後續啟動開發伺服器,建立一個claude-progress.txt 記錄進度,做第一次git 提交,最關鍵的是產生一份功能清單。 這份功能清單有多細?在克隆claude .ai 的案例中,列了超過200 個具體功能,例如用戶能開啟新對話、輸入問題、按回車、看到AI 回覆。每一條初始狀態都標示為失敗,後續Agent 必須逐一驗證通過才能改成成功。 而且這裡有個細節,這個清單不是用Markdown 來寫的,是一個JSON 數組,因為Anthropic 實驗發現,相較於Markdown,模型在處理JSON 時更不容易隨意篡改或覆蓋檔案。 另一個是編碼Agent。初始化專案後,後續就是它工作了,核心行為準則只有兩個:一次只做一個功能,做完要留下乾淨的環境。 什麼叫乾淨的環境?想像你往主分支提交程式碼的標準:沒有嚴重bug,程式碼整齊有文檔,下一個人接手能直接開始新功能,不用先替你收拾爛攤子。 每次開工前,它先做幾件事: – 執行pwd 看看自己在哪個目錄– 讀Git 日誌和進度文件,搞清楚上一輪乾了啥– 看功能清單,挑一個最高優先級的未完成功能– 跑一遍基礎測試,確保App 還能用 然後專心做一個功能,做完後: – 寫清楚的Git commit message – 更新claude-progress.txt – 只改功能清單裡的狀態字段,絕不刪改需求本身 這個設計的巧妙之處在於,它把「記憶」外化成了文件和Git 歷史。每一輪的Agent 不需要依賴上下文視窗裡的碎片訊息,而是模仿可靠的人類工程師每天上班會做的事。先同步進度,確認環境正常,再動手工作。 測試環節的改進值得單獨說。 原來Agent 只會用程式碼層面的方式驗證,例如跑單元測試或調接口。問題是很多bug 只有使用者真正操作頁面時才會暴露。 解決方案是給Agent 配上瀏覽器自動化工具,例如Puppeteer MCP。 Agent 現在能像真人一樣開啟瀏覽器、點按鈕、填表單、看頁面渲染結果。 Anthropic 放了一張動圖,展示Agent 測試克隆版claude .ai 時自己截的圖,確實是在像使用者一樣操作。 這一招大幅提升了功能驗證的準確率。當然也有邊界,例如瀏覽器原生的alert 彈跳窗,Puppeteer 捕捉不到,依賴彈跳窗的功能就容易出bug。 這套方案還留了一些開放性問題。 例如,到底是一個通用Agent 全包好,還是搞專業分工?讓測試Agent 專門測,程式碼清理Agent 專門收拾,也許效果更好。 再例如,這套經驗是針對全端Web 開發優化的,能不能遷移到科學研究或金融建模這類長週期任務?應該可以,但需要實驗驗證。 響馬@xicilion 說: > ai 的盡頭依舊是軟體工程。 AI Agent 也不是魔法,它一樣需要從人類軟體工程中汲取經驗,它也需要將複雜的任務分解成簡單的任務,要有一個結構化的工作環境和清晰的交接機制。 人類工程師為什麼能跨團隊、跨時區協作?因為有Git、有文件、有Code Review、有測試。 AI Agent 要長時間自主工作,也要把這些東西搬過來。 Anthropic 的方案,不過是把軟體工程的最佳實踐變成了Agent 能理解的提示字和工具鏈。不是讓模型變得更聰明,而是給它更好的腳手架。 Anthropic 的想法值得借鏡。無論你用的是Claude、GPT 或別的模型,在設計多輪長任務時,都要想清楚,怎麼讓下一輪的Agent 快速進入狀態,怎麼避免它重複造輪子或把程式碼搞成一團亂麻。即使是單輪任務,也要清楚它是沒有記憶的,你需要透過外部文件來幫助它「想起來」之前做過的事。 以現在模型的能力,Coding Agent 已經能做很多事情了,核心還是在於你是不是能像軟體工程中那樣,去分解好任務,設計好工作的流程。 原文:Effective harnesses for long-running agents https://t.co/tERUGrV9wC 翻譯:
文章中說的任務清單就算是全域context的一種,只是全域context一樣沒辦法太長,不然執行任務的上下文視窗就不夠用了