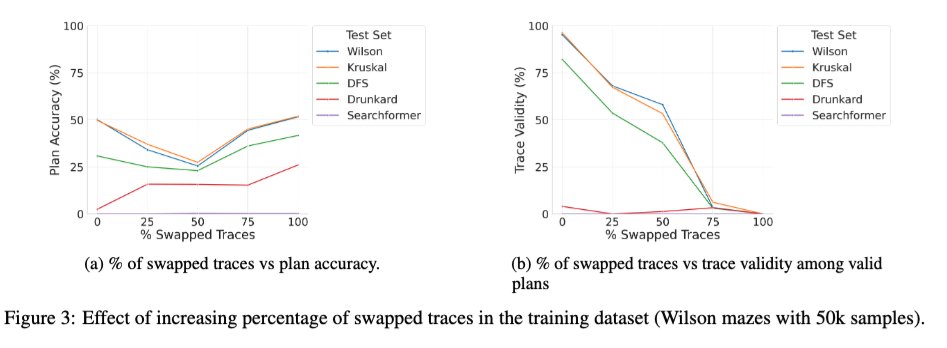
我們剛剛在arXiv上上傳了論文《超越語義學》的擴展版本——這篇論文系統地研究了LRM中中間標記的作用——或許你們中的一些人會感興趣。 🧵 1/ 一項引人入勝的新研究探討了使用正確和錯誤軌跡混合訓練基礎Transformer模型的效果。我們注意到,隨著訓練過程中錯誤(交換)軌跡的比例從0%增加到100%,模型在推理時的軌跡有效性如預期般單調下降(見下圖右側),但解的準確率卻呈現出U形曲線(見下圖左側)!這表明,真正起作用的似乎是訓練過程中所用軌蹟的“一致性”,而非其正確性。
正在載入線程內容
正在從 X 取得原始推文,整理成清爽的閱讀畫面。
通常只需幾秒鐘,請稍候。
共 1 則推文 · 2025年11月26日 下午4:12
我們剛剛在arXiv上上傳了論文《超越語義學》的擴展版本——這篇論文系統地研究了LRM中中間標記的作用——或許你們中的一些人會感興趣。 🧵 1/ 一項引人入勝的新研究探討了使用正確和錯誤軌跡混合訓練基礎Transformer模型的效果。我們注意到,隨著訓練過程中錯誤(交換)軌跡的比例從0%增加到100%,模型在推理時的軌跡有效性如預期般單調下降(見下圖右側),但解的準確率卻呈現出U形曲線(見下圖左側)!這表明,真正起作用的似乎是訓練過程中所用軌蹟的“一致性”,而非其正確性。