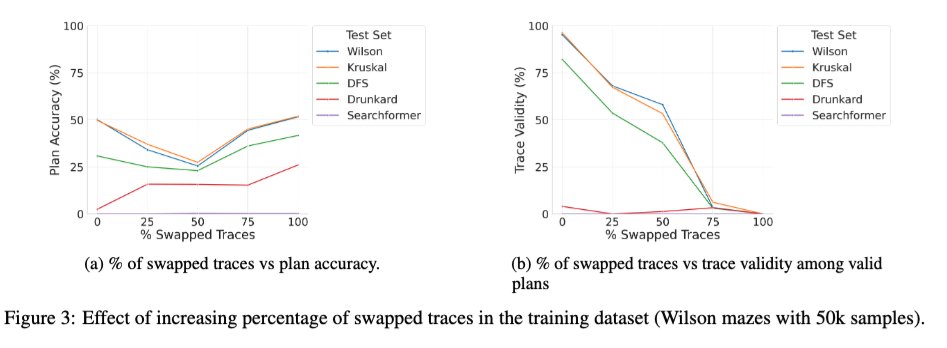
我們剛剛在arXiv上上傳了論文《超越語義學》的擴展版本——這篇論文系統地研究了LRM中中間標記的作用——或許你們中的一些人會感興趣。 🧵 1/ 一項引人入勝的新研究探討了使用正確和錯誤軌跡混合訓練基礎Transformer模型的效果。我們注意到,隨著訓練過程中錯誤(交換)軌跡的比例從0%增加到100%,模型在推理時的軌跡有效性如預期般單調下降(見下圖右側),但解的準確率卻呈現出U形曲線(見下圖左側)!這表明,真正起作用的似乎是訓練過程中所用軌蹟的“一致性”,而非其正確性。
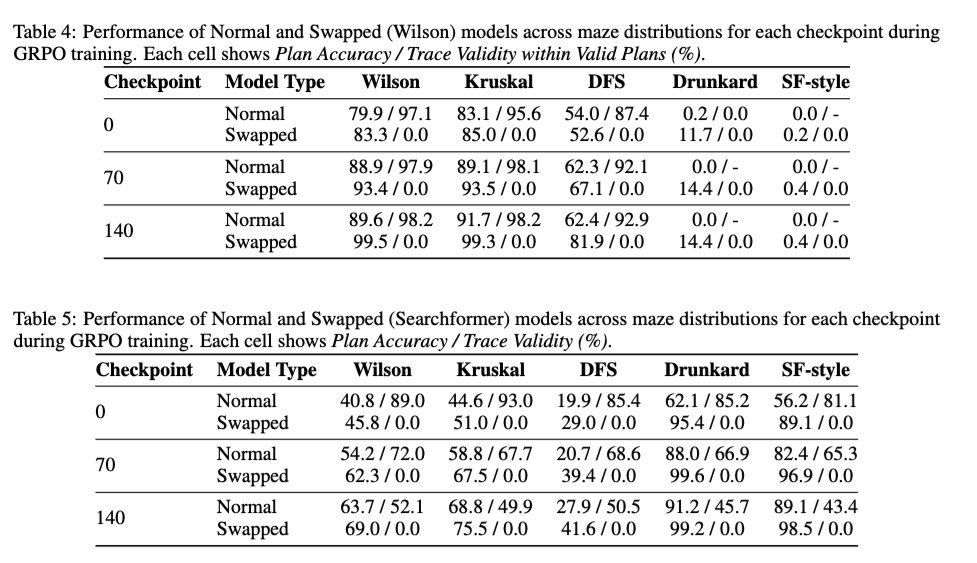
2/ 我們也檢視了DeepSeek R1風格的強化學習對軌跡有效性的影響-即強化學習是否能提升基礎模型的軌跡效度。結果表明,強化學習對軌跡有效性基本無影響。即使在模型使用100%交換軌跡訓練的情況下,強化學習也能提升求解精度,而不會提高軌跡效度。
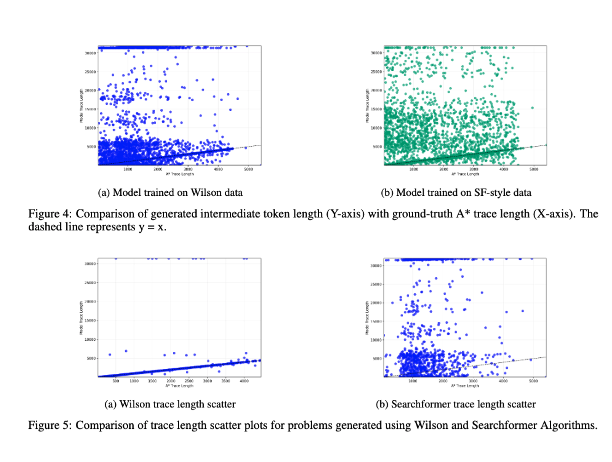
3/ 最後,我們研究了中間詞元長度與問題實例的計算複雜度之間的相關性。結果表明,二者之間沒有相關性! (我曾在 https://t.co/RL9ZEOKbpQ 中討論過該實驗的早期版本)
4/ 新版本可在 https://t.co/4LGWfiCZ5e 找到arxiv.org/abs/2505.1377592、@kayastechly 和 @PalodVardh12428 在下週的 #NeurIPS2025 研討會上進行展示,研討會主題為 LAW、ForLM 和高效推理。歡迎屆時蒞臨交流!