正在載入線程內容
正在從 X 取得原始推文,整理成清爽的閱讀畫面。
通常只需幾秒鐘,請稍候。
共 1 則推文 · 2025年11月25日 下午3:41
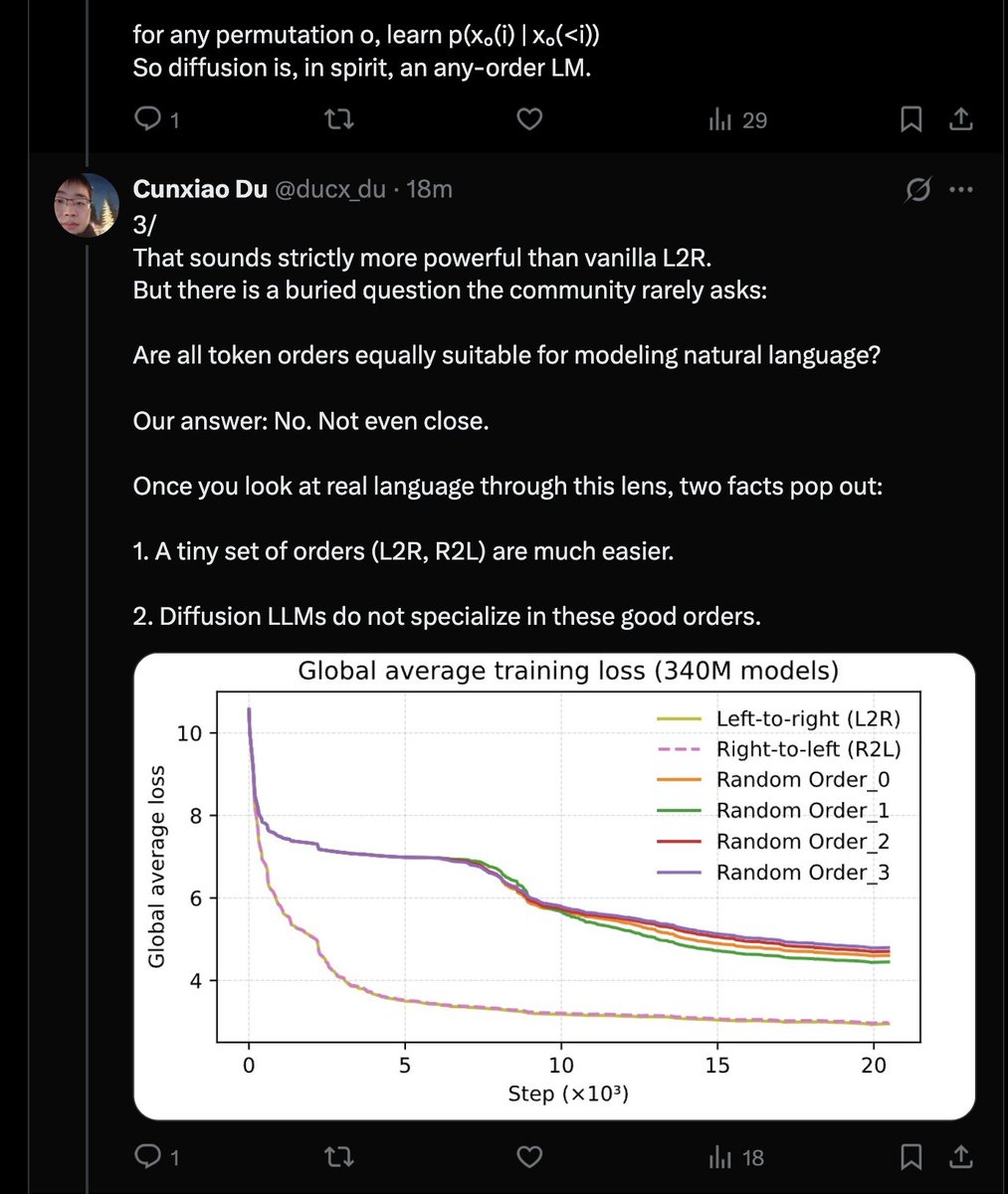
極具感染力的敘述。 預設情況下,擴散模型毫無意義,因為語言是馬可夫的,而 L2R 或 R2L 順序明顯更優。看來訓練 DLLM 的唯一合理方法是使用對數和損失。