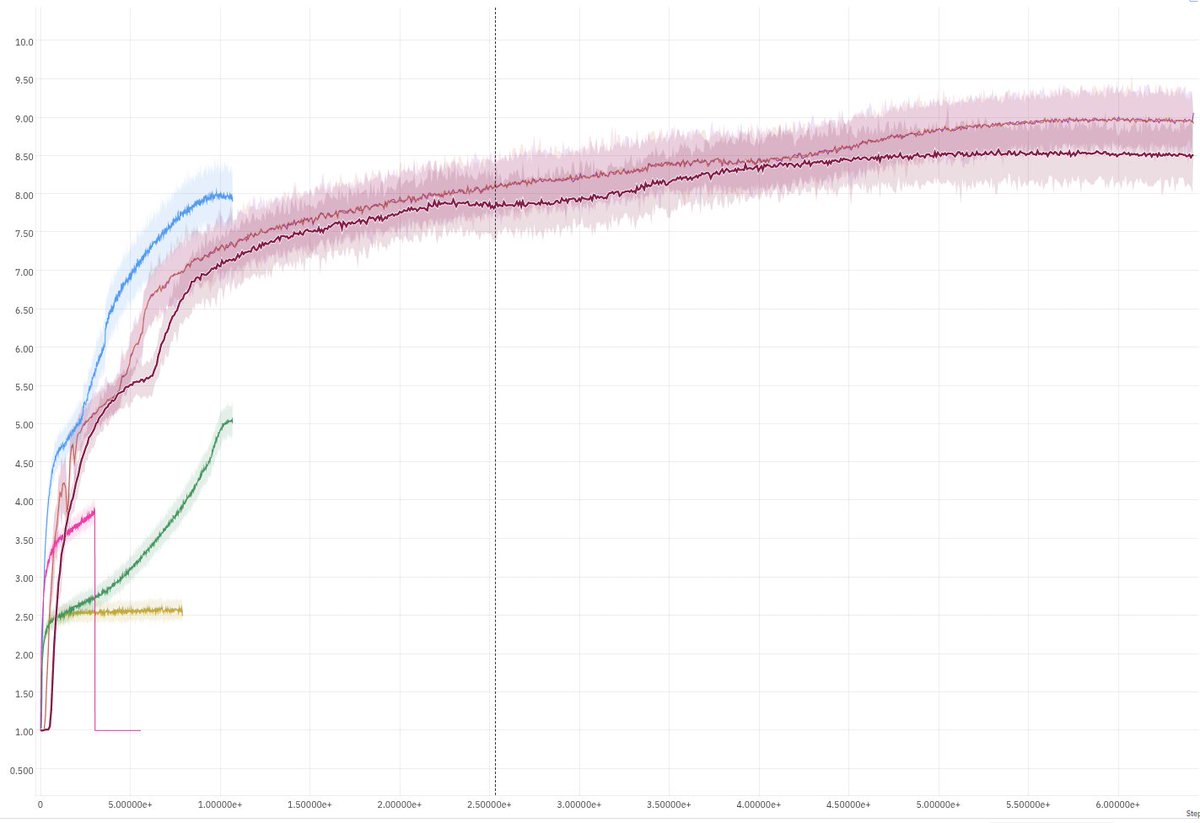
我們在最難的強化學習任務-神經多目標優化3(Neural MMO 3)上取得了明顯的SOTA(最先進水準),訓練步數達到6,500億(每次運行超過1PB的觀測資料)。計算浮點運算次數和參數均達到匹配水準。 問題在於:為了讓它發揮作用,我需要在性能上與 cuDNN LSTM 競爭。而這個網路需要多個卷積核。
正在載入線程內容
正在從 X 取得原始推文,整理成清爽的閱讀畫面。
通常只需幾秒鐘,請稍候。
共 1 則推文 · 2025年11月25日 凌晨2:03
我們在最難的強化學習任務-神經多目標優化3(Neural MMO 3)上取得了明顯的SOTA(最先進水準),訓練步數達到6,500億(每次運行超過1PB的觀測資料)。計算浮點運算次數和參數均達到匹配水準。 問題在於:為了讓它發揮作用,我需要在性能上與 cuDNN LSTM 競爭。而這個網路需要多個卷積核。