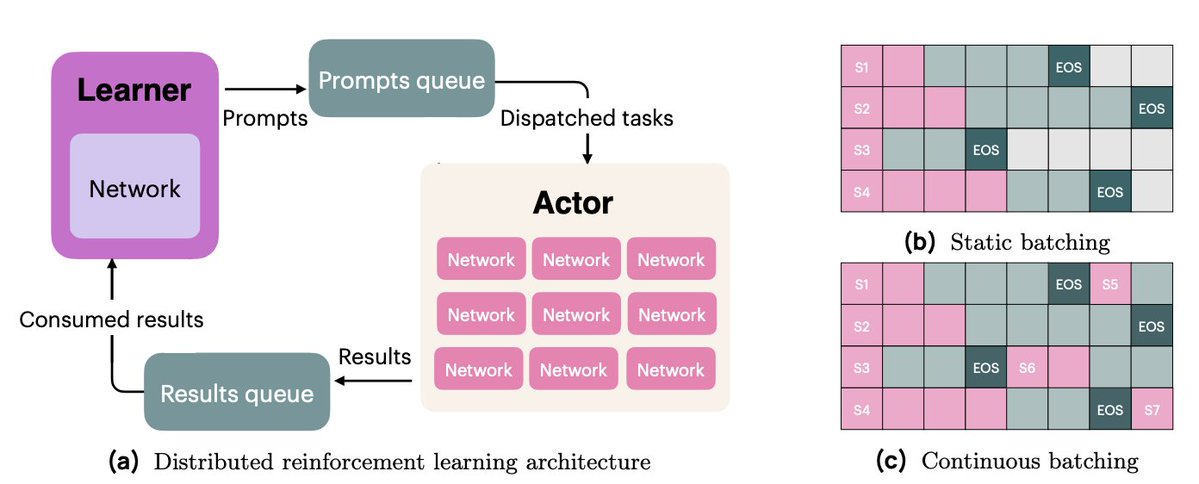
OlmoRL 的基礎架構比 Olmo 2 快 4 倍,並且大幅降低了實驗運行成本。部分改進包括: 1. 連續配料 2. 飛行中更新 3. 主動採樣 4. 對我們的多執行緒程式碼進行了許多改進
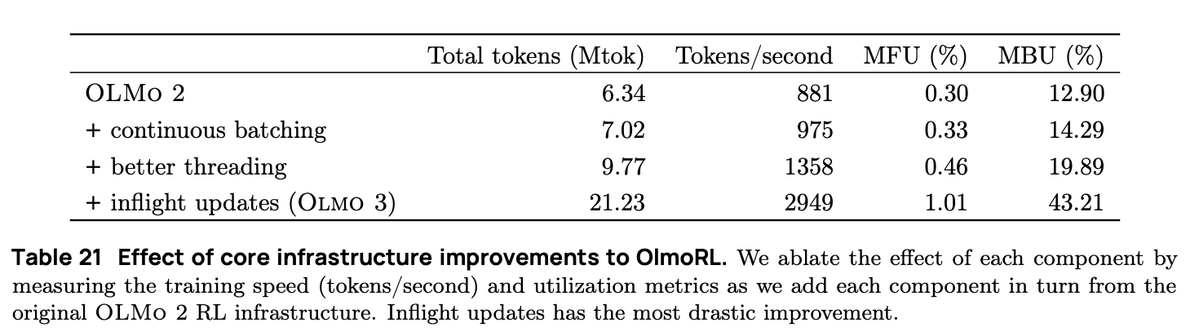
在連續批次中,我們採用完全非同步的生成設置,其中我們有兩個隊列:一個用於提示,一個用於產生結果。 我們的演員完全非同步運行,不斷拉取新的提示,並在任務完成後產生提示。
利用即時更新(PipelineRL,由 @alexpiche_、@DBahdanau 等人開發),我們可以在生成過程中更新 Actor。由於無需清空生成佇列來更新權重(這與靜態批次存在相同的問題),系統速度更快。

主動採樣(@mnoukhov 的創新貢獻)解決了 GRPO 中出現的一個棘手問題,即獎勵方差為 0(因此優勢為 0,梯度為 0)的組別被過濾掉,導致批次大小隨訓練步驟而變化。
先前的論文透過採樣所需組數的3倍來解決批次大小不一的問題,希望過濾後始終能有足夠的組數。而Michael修改了我們的程式碼,使其在訓練前等待獲得一整批非恆定獎勵組。
這需要進行大量巧妙的工作,才能使我們的演員和學習者保持同步。
最後,我們花了大量時間重構程式碼庫,減少同步,讓角色能夠非同步運作。這涉及到對 Python 線程和 asyncio API 的大量工程開發工作。
我們的 RL 基礎設施工作是一項團隊努力,我本人、@hamishivi、@mnoukhov、@saurabh_shah2 和 @tyleraromero 都做出了貢獻,並且建立在 @vwxyzjn 留下的基礎之上。
要了解更多關於我們工作的信息,請查看論文、部落格文章和相關工作,包括我們從太平洋時間上午 9 點開始的直播。