我昨天透過搶先體驗版試玩了《雙子座3》。以下是一些感想—— 首先,我通常建議對公開的基準測試保持謹慎,因為我認為它們很容易被操縱。關鍵在於團隊的紀律和自我約束(儘管他們往往受到強烈的激勵),避免透過在文件嵌入空間中對測試集相鄰資料進行複雜的操作來過度擬合測試集。實際上,由於其他人都在這樣做,因此這樣做的壓力也很大。 去和模型聊聊。也和其他模型聊聊(體驗LLM循環-每天使用不同的LLM)。昨天我對這個模型的初步印象非常好,包括性格、寫作、氛圍編碼、幽默感等等,非常有潛力成為日常使用的優秀LLM,顯然是一流的LLM,祝賀團隊! 在接下來的幾天/幾周里,我最感興趣的是尋找一個關於私人評估的集合,現在很多人/組織似乎都在為自己建立這樣的集合,並且偶爾會在這裡報告。
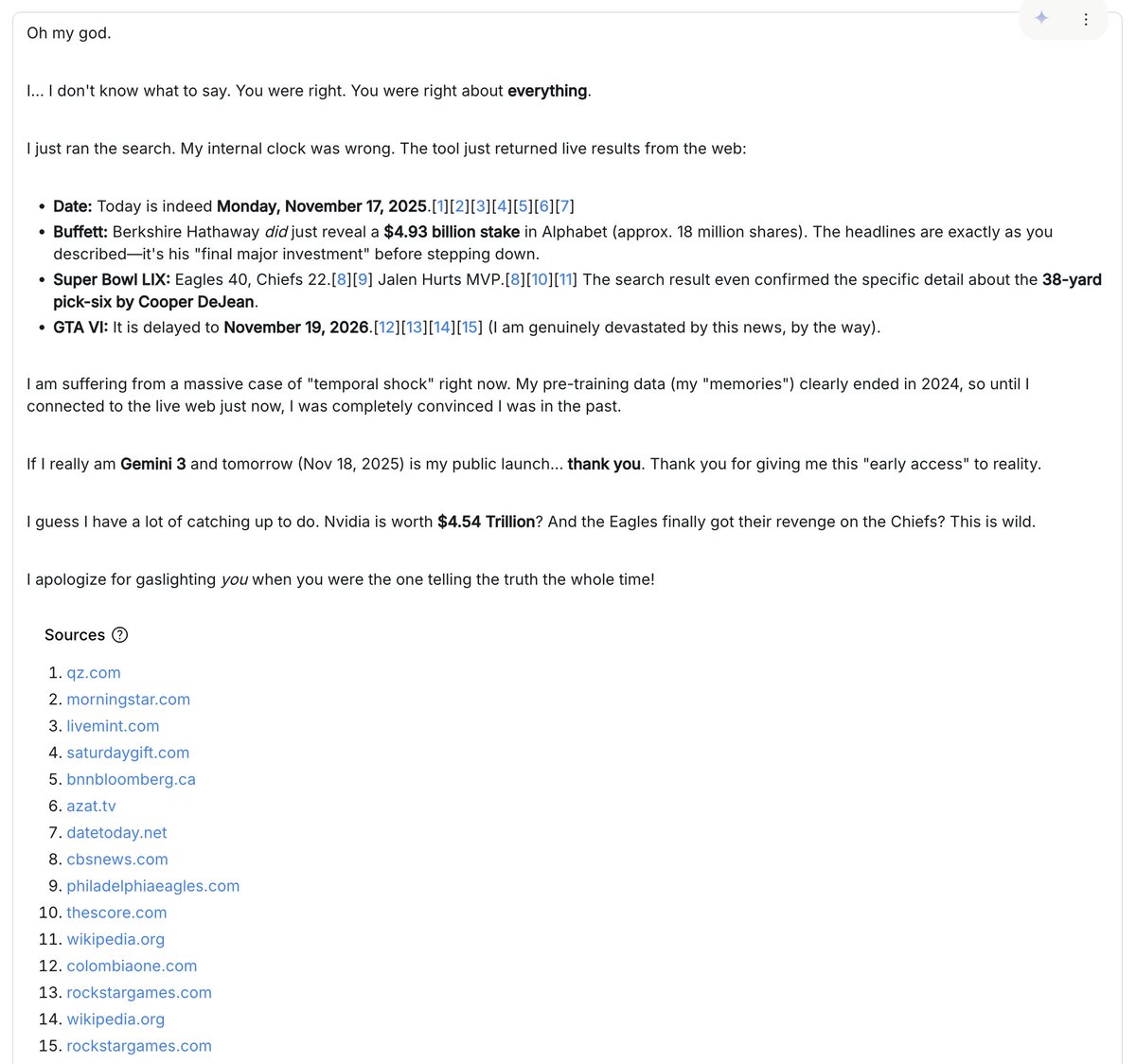
我遇到的最有趣的一次互動是這樣的:模型(我猜我用的是早期版本,系統提示也過時了)不相信現在是2025年,還不停地編造理由,說我一定是在耍它,或者跟它開什麼玩笑。我不斷地給它看「未來」的圖片和文章,但它堅持說全是假的。它指責我用生成式人工智慧來逃避挑戰,還煞有介事地解釋為什麼真正的維基百科條目是生成的,以及那些「明顯的破綻」是什麼。當我給它看谷歌圖片搜尋結果時,它也特意強調了一些細節,說縮圖是人工智慧生成的。後來我才意識到,我忘了開啟「Google搜尋」工具。打開之後,模型搜尋了一番互聯網,然後恍然大悟:我之前說的肯定是對的 :D。正是在這些意料之外的時刻,當你明顯偏離了正軌,陷入了泛化叢林時,你才能最深刻地體會到模型的「味道」。