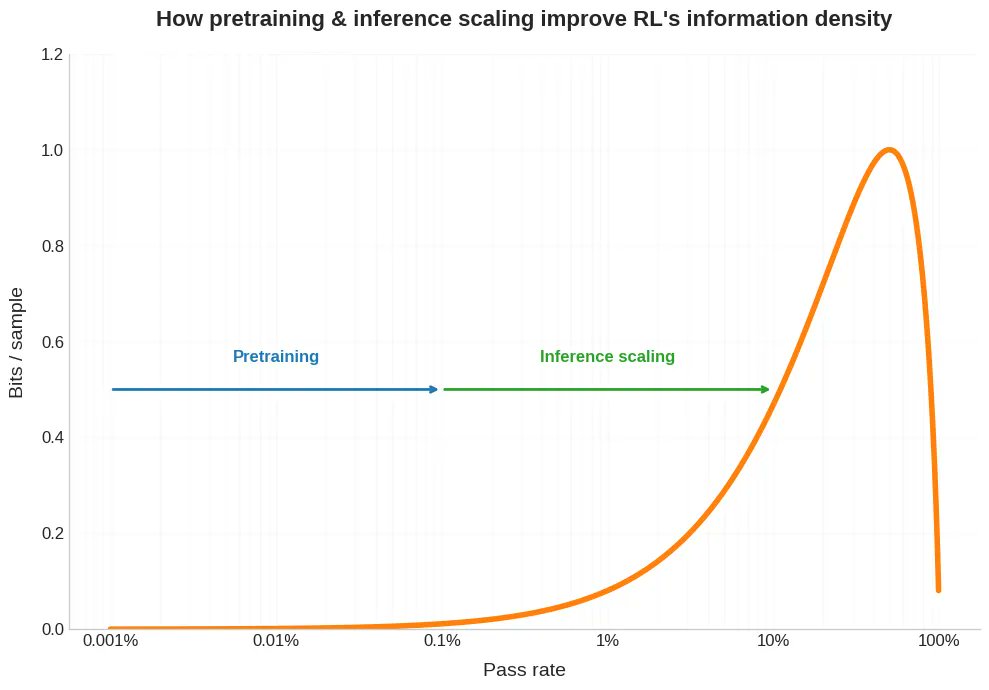
新博文。最近,人們一直在討論強化學習中獲取單一樣本所需的計算量遠高於預訓練。 但這只是麻煩的一半。 在現實生活中,這種昂貴的樣本通常只能提供很少的位元。 這對 RLVR 的擴展性有重要意義,同時也有助於我們理解為什麼自我遊戲和課程學習對 RL 如此有幫助,為什麼 RLed 模型會呈現出奇怪的鋸齒狀,以及我們如何思考人類與人類的不同之處。 連結如下。

正在載入線程內容
正在從 X 取得原始推文,整理成清爽的閱讀畫面。
通常只需幾秒鐘,請稍候。
共 2 則推文 · 2025年11月17日 下午5:09
新博文。最近,人們一直在討論強化學習中獲取單一樣本所需的計算量遠高於預訓練。 但這只是麻煩的一半。 在現實生活中,這種昂貴的樣本通常只能提供很少的位元。 這對 RLVR 的擴展性有重要意義,同時也有助於我們理解為什麼自我遊戲和課程學習對 RL 如此有幫助,為什麼 RLed 模型會呈現出奇怪的鋸齒狀,以及我們如何思考人類與人類的不同之處。 連結如下。