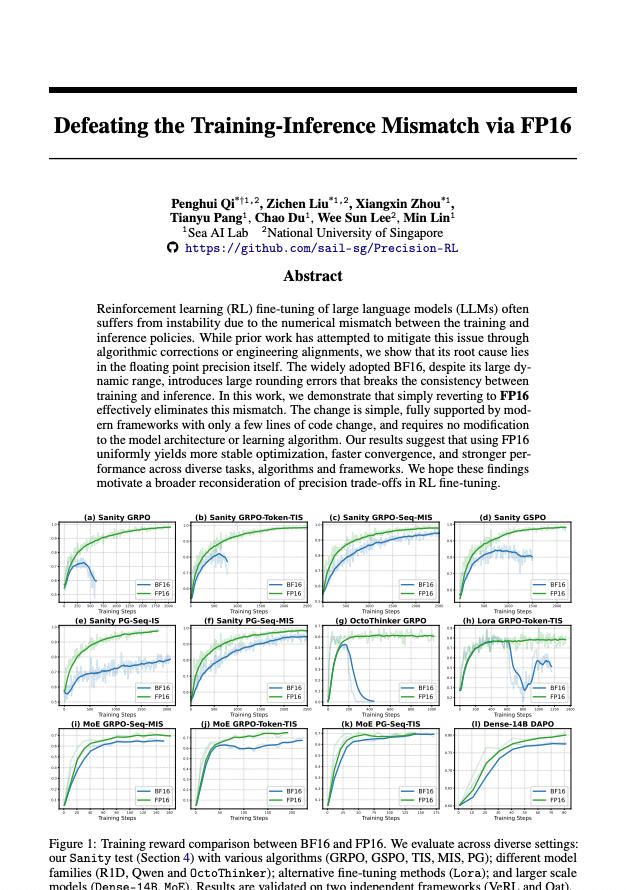
#8 - 透過 FP16 克服訓練-推理不匹配問題 連結 - https://t.co/rFKo8w36nc 延續第 6 章和第 7 章的主題,請將此章視為arxiv.org/abs/2510.26788過重要性採樣技巧或大量的工程設計來更好地對齊卷積核,從而解決訓練-推理不匹配的問題。這些方法在一定程度上有所幫助,但是: >需要額外的計算成本(額外的前向傳遞) >但這並不能真正解決你優化了一個版本卻部署了另一個版本的問題。 仍然可能不穩定 所以這篇論文的論點是:真正的罪魁禍首是BF16。使用FP16。 我在推特上用這個主題做了好幾個表情包,玩得不亦樂乎。
#9 - 二階優化在LLM的應用潛力:基於全高斯-牛頓法的研究 連結 - https://t.co/wlkpXHz4sf 該論文表明,如果使用實際的高斯-牛頓曲率而不是大家使用的簡化近似值,則可以顯著加快 LLM 的訓練速arxiv.org/abs/2510.09378驟減少了約 5.4 倍;與 μ 子相比,減少了約 16 倍。 他們既沒有對這一說法做出理論上的保證,也沒有進行大規模測試(只有 1.5 億個參數)。
