🚨DeepSeek 剛剛做了一些瘋狂的事情。 他們建立了一個 OCR 系統,將長文本壓縮成視覺標記,將段落轉換成像素。 他們的模型 DeepSeek-OCR 在 10 倍壓縮下解碼精度可達 97%,即使在 20 倍壓縮下也能保持 60% 的準確率。這意味著一張圖像僅需 LLM 所需 token 的一小部分即可表示整篇文件。 更瘋狂?它擊敗了 GOT-OCR2.0 和 MinerU2.0,同時使用的代幣減少了 60 倍,並且一台 A100 處理器每天可以處理 20 萬頁以上的資料。 這可以解決人工智慧最大的問題之一:長上下文效率低。 模型可能很快就不會再為更長的序列支付更多費用,而是看到文字而不是閱讀文字。 上下文壓縮的未來可能根本不是文字的。 可能是光學的👁️ github。 com/deepseek-ai/DeepSeek-OCR
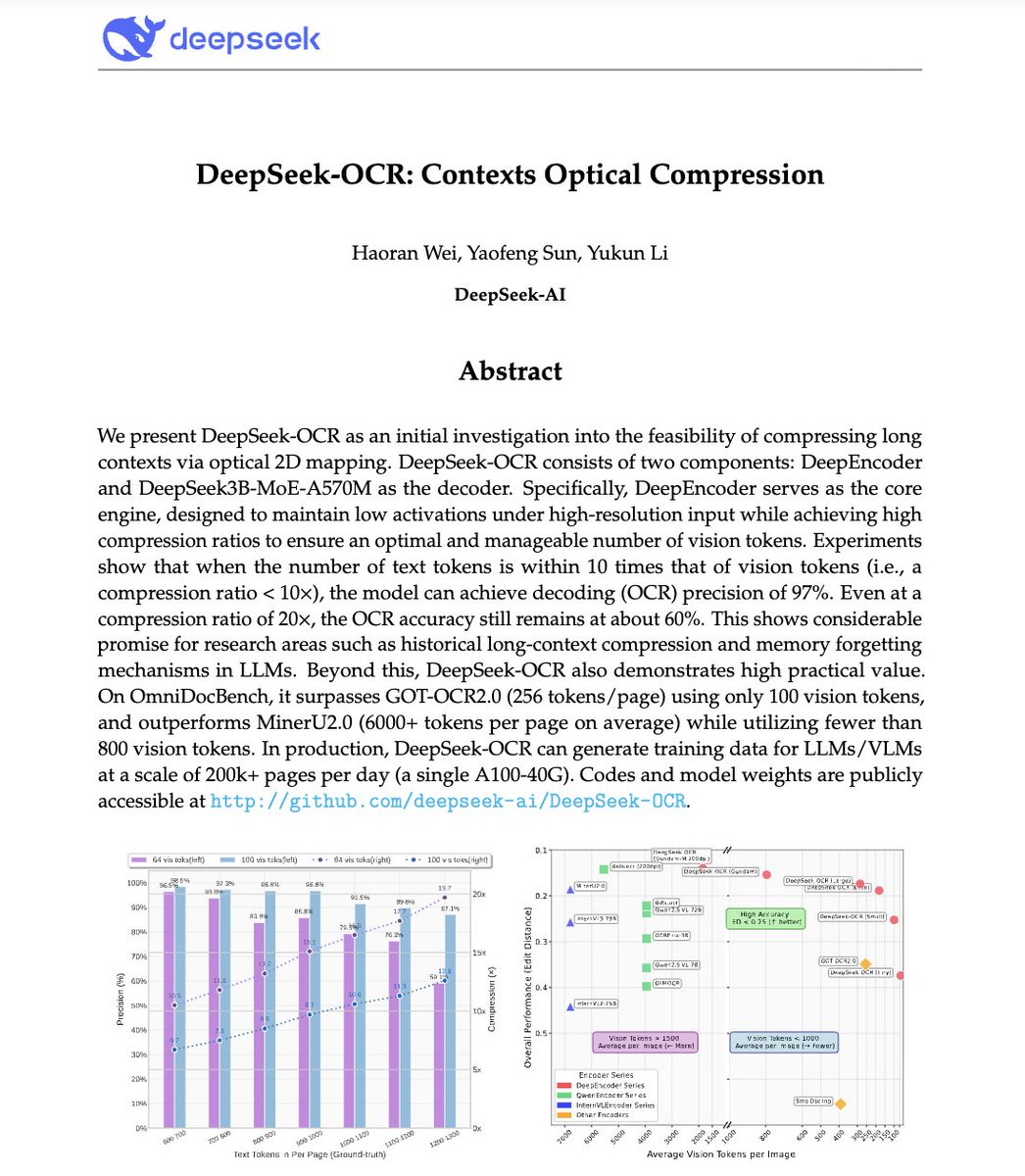
1. 視覺文本壓縮:核心思想 LLM 難以處理長文檔,因為標記的使用量與長度成二次方關係。 DeepSeek-OCR 則相反:它不是讀取文本,而是將完整文檔編碼為視覺標記,每個標記代表一段壓縮的視覺訊息。 結果:您可以將 10 頁的文字放入在 GPT-4 中處理 1 頁所需的相同代幣預算中。

2. DeepEncoder - 光學壓縮器 認識明星:DeepEncoder。 它使用兩個主幹網路 SAM(用於感知)和 CLIP(用於全域視覺),由 16×卷積壓縮器連接。 這使得它能夠保持高解析度的理解,而不會爆炸激活記憶。 編碼器將數千個圖像塊轉換為數百個緊湊視覺標記。

3. 多重解析度「高達」模式 文件各不相同,發票≠藍圖≠報紙。 為了解決這個問題,DeepSeek-OCR 支援多種解析度模式:Tiny、Small、Base、Large 和 Gundam。 高達模式有效地結合了局部圖塊 + 全域視圖,從 512×512 縮放到 1280×1280。 一個模型,多種分辨率,無需重新訓練。

4. 資料引擎OCR 1.0到2.0 他們不僅僅進行文字掃描訓練。 DeepSeek-OCR 的數據包括: • 100 種語言的 3000 多萬個 PDF 頁面 • 1000 萬自然場景 OCR 樣本 • 1000 萬張圖表 + 500 萬個化學公式 + 100 萬個幾何問題 它不僅僅是閱讀,它還可以解析科學圖表、方程式和佈局。

5. 這不僅僅是“另一個 OCR”。 這是上下文壓縮的概念證明。 如果文字可以用少 10 倍的標記進行視覺表示,那麼 LLM 可以使用相同的想法進行長期記憶和有效推理。 想像 GPT-5 將 1M 個標記的文檔處理為 100K 個標記的影像映射。

不要再浪費時間寫提示 → 10,000+ 個隨時可用的提示 → 幾秒鐘內即可創建自己的 → 終身訪問。一次付款。 領取您的副本👇