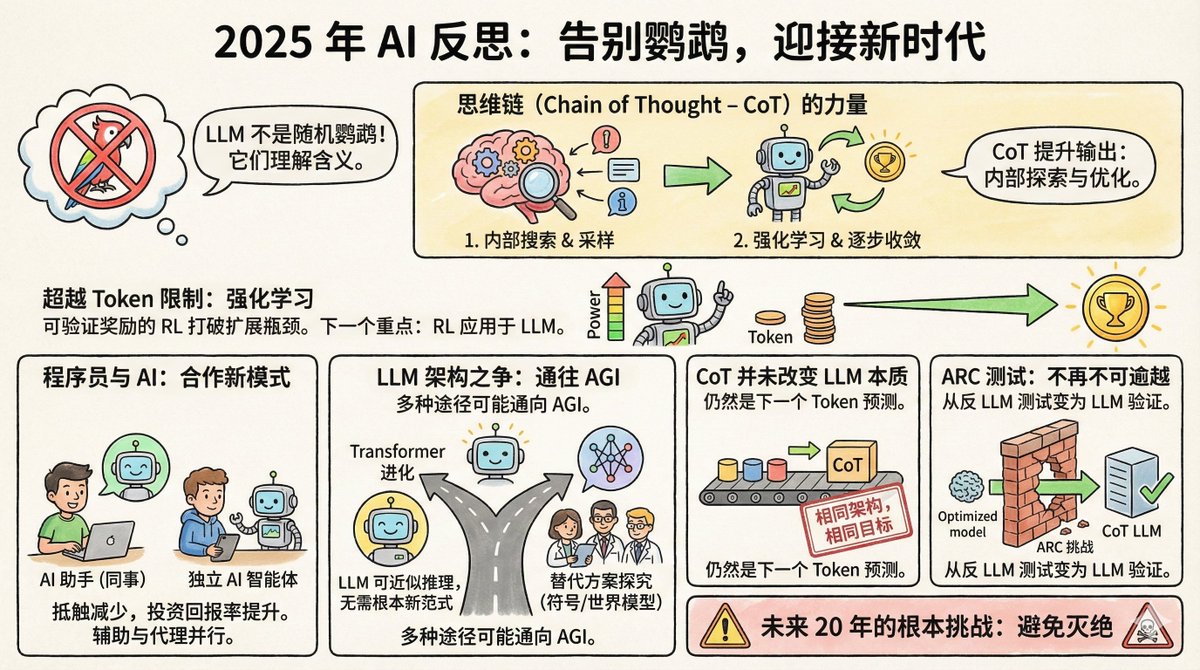
Salvatore Sanfilippo, the creator of Redis, recently published a year-end reflection on AI, outlining eight key points. First, some background: Salvatore isn't in the AI field; he's a legend in the programming world. In 2009, he created Redis, a database now one of the world's most popular caching systems. He retired from Redis in 2020 to pursue his own projects. He returned to Redis at the end of 2024, while also becoming a heavy user of AI tools; Claude is his coding partner. This identity is quite interesting—he is both a tech expert and an ordinary user of AI, giving him a more down-to-earth perspective than pure AI researchers. First, the claim about random parrots is finally being disbelieved. In 2021, Google researchers Timnit Gebru and others published a paper that nicknamed large language models "random parrots." This means that these models are simply piecing together words probabilistically, without understanding the meaning of the question or knowing what they are saying. The analogy is vivid and widely used. But Salvatore says that by 2025, almost no one will use it anymore. Why? Because there's too much evidence. LLM models outperform the vast majority of humans in bar exams, medical exams, and math competitions. More importantly, researchers, through reverse engineering these models, have discovered that they do indeed contain internal representations of concepts, not simply word collages. Geoffrey Hinton put it most bluntly: to accurately predict the next word, you must understand the sentence. Understanding is not a substitute for prediction, but a necessary condition for making good predictions. Of course, whether LLM truly understands it is a philosophical debate. But in practical terms, that debate is over. II. The Mind Chain is an Underrated Breakthrough The thought process chain is about having the model write down its thought process before answering. It seems simple, but the underlying mechanism is quite profound. Salvatore believes it did two things: First, it allows the model to sample its internal representations before answering. In simpler terms, it retrieves relevant concepts and information into the context of the question and then answers based on that information. This is somewhat like someone outlining their exam on scratch paper beforehand. Second, by incorporating reinforcement learning, the model learns how to guide its thinking step by step toward the correct answer. The output of each token changes the model's state, and reinforcement learning helps it find the path that converges to the good answer. It's nothing mysterious, but the effects are amazing. Third, the bottleneck of computing power expansion has been broken. There used to be a consensus in the AI community: the improvement of model capabilities depends on the amount of training data, but the amount of text produced by humans is limited, so expansion will eventually hit a wall. But now, with reinforcement learning that offers verifiable rewards, things have changed. What are verifiable rewards? For some tasks, such as optimizing program speed or proving mathematical theorems, the model can judge the quality of the results itself. A faster program is better, and a correct proof is correct; no human annotation is needed. This means that the model can continuously improve itself on these types of tasks, generating an almost infinite amount of training signals. Salvatore believes this will be the direction of the next major breakthrough in AI. Remember AlphaGo's 37th move? Nobody understood it at the time, but it was later proven to be a divine move. Salvatore believes that LLM might follow a similar path in certain fields. IV. The programmers' attitudes have changed. A year ago, the programmer community was divided into two camps: one thought AI-assisted programming was a magic weapon, and the other thought it was just a toy. Now, the skeptics have largely switched sides. The reason is simple: the return on investment has exceeded a critical point. The model may indeed make mistakes, but the time it saves far outweighs the cost of correcting those mistakes. Interestingly, programmers' approaches to AI fall into two camps: one treats LLM as a "colleague," primarily using it through web-based, conversational interfaces. Salvatore himself belongs to this camp, using web-based versions like Gemini and Claude to collaborate as if chatting with a knowledgeable person. Another school of thought views LLM as an "independent and autonomous coding intelligence," allowing it to write code, run tests, and fix bugs on its own, while humans are mainly responsible for review. These two uses are based on different philosophies: Do you treat AI as an assistant or as an executor? V. The Transformer might be the way forward. Some prominent AI scientists have begun exploring architectures beyond Transformer, forming companies to research explicit symbolic representations or world models. Salvatore holds an open but cautious view on this. He believes that LLM is essentially an approximation of discrete reasoning in a differentiable space, and it is not impossible to achieve AGI without a fundamentally new paradigm. Moreover, AGI can be implemented independently through a variety of completely different architectures. In other words, all roads lead to Rome. The Transformer may not be the only path, but it's not necessarily a dead end either. VI. The mindset chain does not change the essence of LLM. Some people have changed their tune. They used to say that LLM was a random parrot, but now they acknowledge that LLM has the ability, but they also say that the mind chain fundamentally changes the nature of LLM, so the previous criticisms are still valid. Salvatore said directly: They are lying. The architecture remains the same; it's still a Transformer. The training objective remains the same: predicting the next token. CoT is also generated token by token, which is no different from generating other content. You can't claim that the model "has become something else" just because it's become more powerful, in order to excuse your incorrect judgment. That's a rather blunt statement, but it's logically sound. Scientific judgments should be based on mechanisms, and definitions shouldn't be changed simply because the outcome has changed. Another example that illustrates this point well is the ARC test. VII. ARC testing has shifted from being anti-LLM to being LLM-friendly. ARC is a test designed by François Chollet in 2019 specifically to measure abstract reasoning ability. Its design aims to resist memory retrieval and brute-force searches, requiring genuine reasoning to solve. At the time, many people believed that LLM would never pass this test. This was because it requires the ability to generalize rules from a very small number of samples and apply them to new situations, which is precisely what the random parrot cannot do. The result? By the end of 2024, OpenAI's o3 achieved an accuracy of 75.7% on ARC-AGI-1. In 2025, even on the more difficult ARC-AGI-2, top models achieved over 50% accuracy. This reversal is quite ironic. The test was originally designed to prove that LLM is ineffective. However, it has ironically become evidence proving that LLM is effective. VIII. Fundamental Challenges for the Next 20 Years The last point is just one sentence: The fundamental challenge for AI in the next 20 years is to avoid extinction. He didn't elaborate, just that one sentence. But you know what he's saying. When AI truly becomes powerful enough, "how to ensure it doesn't cause major problems" will no longer be science fiction. Salvatore is neither a fervent believer in AI nor a skeptic. He is someone who understands the technology and uses AI in practice. His perspective is not purely academic, nor purely commercial hype, but rather the calm observation of a seasoned engineer. His core judgment is that LLMs are far more powerful than many people are willing to admit, reinforcement learning is opening up new possibilities, and our understanding of these systems is still far from complete. This is probably the true state of AI development in 2025: capabilities are accelerating, controversies are decreasing, but uncertainty remains enormous.