实际上,我认为我训练出了第一个历史语言学习模型(LLM):我们的OCR校正模型Ocronos在1950年之前进行了完整的预训练,可以作为基础模型使用。它主要使用来自《美国纪事报》(Chronicle America)的报纸数据。
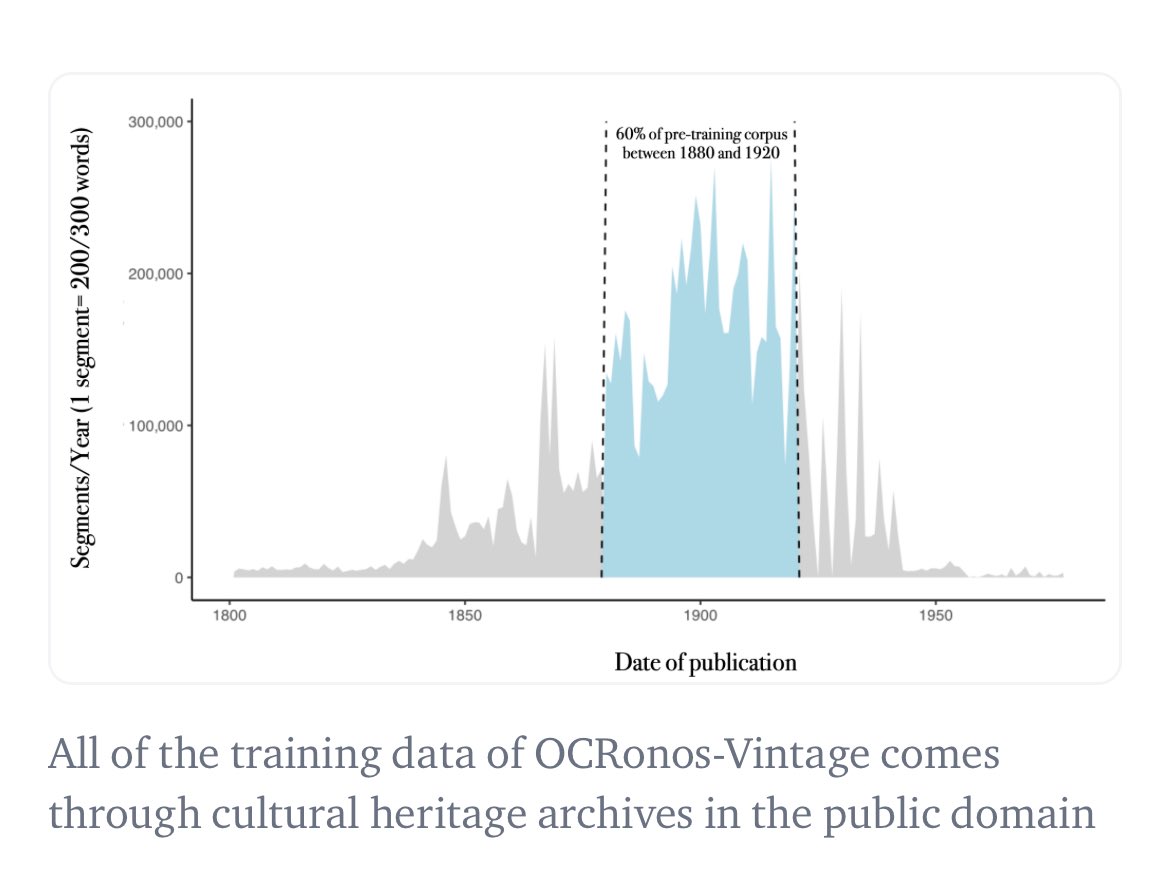
这是一个基于历史背景的世代模型(模型完全不知道特朗普是谁,并回溯到20世纪初)。我发现这个模型在HF上仍然很受欢迎。https://t.co/1ye5VEGerd

Ted Underwood等人还训练了一个GPT-1914模型,它很可能仍然是迄今为止规模最大的历史模型(近8亿像素)。https://t.co/wSA1WCmz2D
