Common Corpus는 이러한 유형의 프로젝트에 사용할 수 있는 최대 규모의 데이터셋(1950년 이전의 약 9천억 개의 토큰)을 보유하고 있다는 점을 다시 한번 알려드립니다.
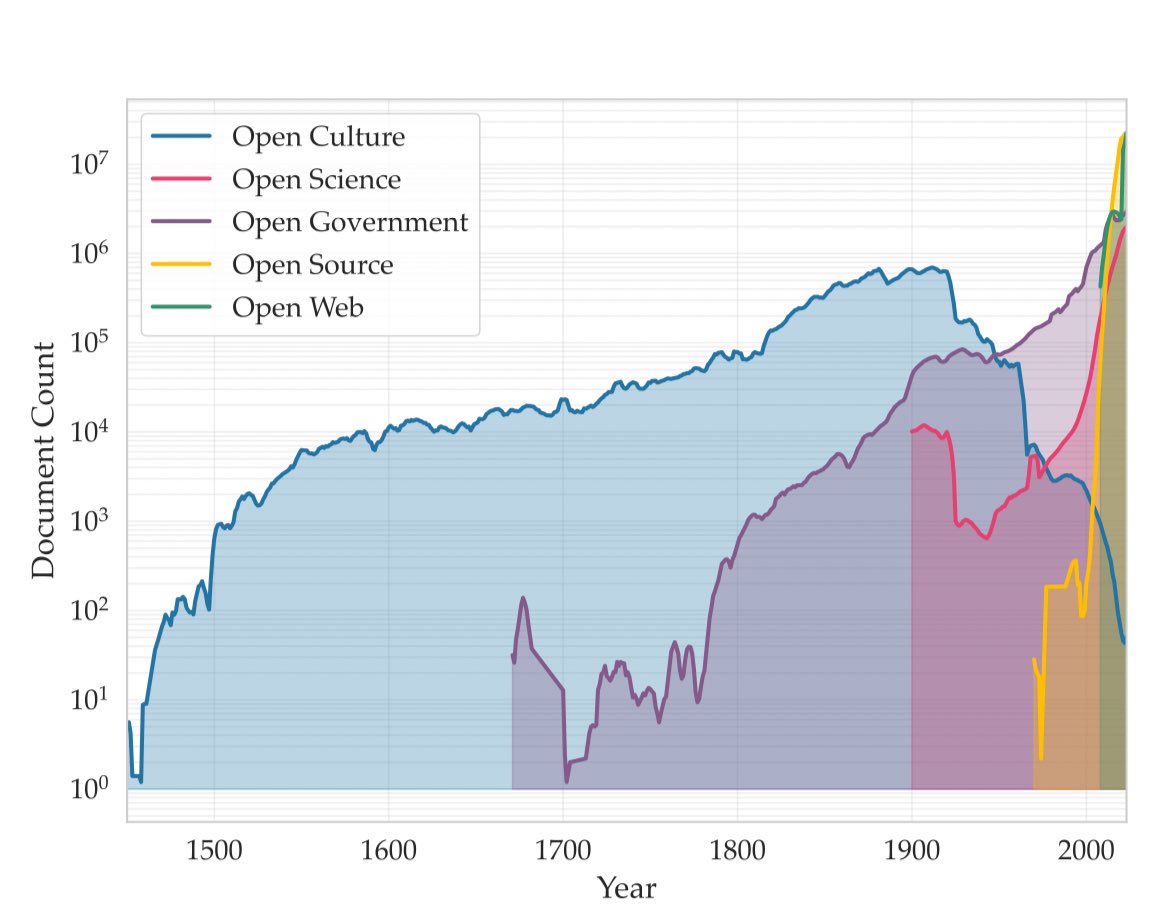
하지만 이제 저는 시간 고정 모델을 위한 합성 환경 접근 방식에 더 관심이 있습니다. 로마 시대의 추론 모델도 충분히 가능성이 있을 수 있습니다.
스레드를 불러오는 중
깔끔한 읽기 화면을 위해 X에서 원본 트윗을 가져오고 있어요.
보통 몇 초면 완료되니 잠시만 기다려 주세요.
트윗 2개 · 2025. 12. 12. 오후 5:35
Common Corpus는 이러한 유형의 프로젝트에 사용할 수 있는 최대 규모의 데이터셋(1950년 이전의 약 9천억 개의 토큰)을 보유하고 있다는 점을 다시 한번 알려드립니다.
하지만 이제 저는 시간 고정 모델을 위한 합성 환경 접근 방식에 더 관심이 있습니다. 로마 시대의 추론 모델도 충분히 가능성이 있을 수 있습니다.