Anthropic Fellows Program의 새로운 연구: 선택적 그라디언트 마스킹(SGTM). 우리는 위험한 무기에 대한 지식과 같은 고위험 지식을 모델에 큰 영향을 미치지 않고 제거할 수 있는 작고 별도의 매개변수 집합으로 분리하여 모델을 훈련하는 방법을 연구합니다.

SGTM은 모델의 가중치를 "유지" 및 "망각" 하위 집합으로 나누고, 사전 학습 과정에서 특정 지식을 "망각" 하위 집합으로 유도합니다. 이후 고위험 환경에 배포하기 전에 제거할 수 있습니다. 더 읽어보세요: https://t.co/BfR4Kd86b0
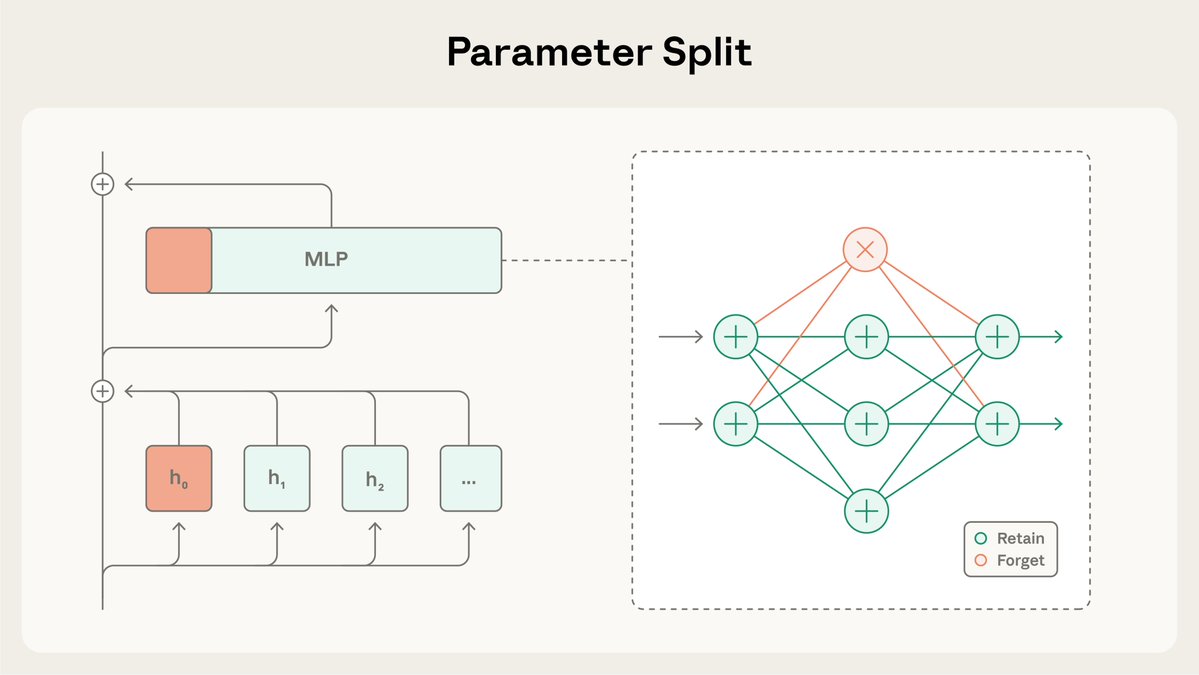
본 연구에서는 SGTM이 위키백과에서 학습된 모델에서 생물학 지식을 제거할 수 있는지 여부를 테스트했습니다. 생물학 관련 내용이 아닌 위키백과 페이지에도 생물학 관련 내용이 포함되어 있을 수 있으므로, 데이터 필터링을 통해 관련 정보가 유출될 수 있습니다.
일반적인 기능을 통제할 때, SGTM으로 훈련된 모델은 데이터 필터링으로 훈련된 모델보다 원하지 않는 "잊어버린" 지식 하위 집합에 대한 성과가 낮습니다.

훈련이 완료된 후에 학습을 취소하는 방법과 달리 SGTM은 취소하기 어렵습니다. SGTM을 사용하면 잊어버린 지식을 복구하는 데 기존의 학습 해제 방법인 RMU에 비해 7배 더 많은 미세 조정 단계가 필요합니다.

이 연구에는 한계가 있었습니다. 표준 벤치마크가 아닌 소규모 모델과 대리 평가가 포함된 단순화된 설정에서 수행되었습니다. 또한 데이터 필터링과 마찬가지로 SGTM은 적대자가 직접 정보를 제공하는 상황 내 공격을 차단하지 못합니다.
SGTM에 대한 전체 논문을 여기에서 읽어보세요: https:arxiv.org/abs/2512.05648을 위해 관련 코드를 GitHub에서도 공개했습니다: https://t.co/zRmJYy6bDE.
이 연구는 Anthropic Fellows Program의 일환으로 @_igorshilov가 주도했습니다.