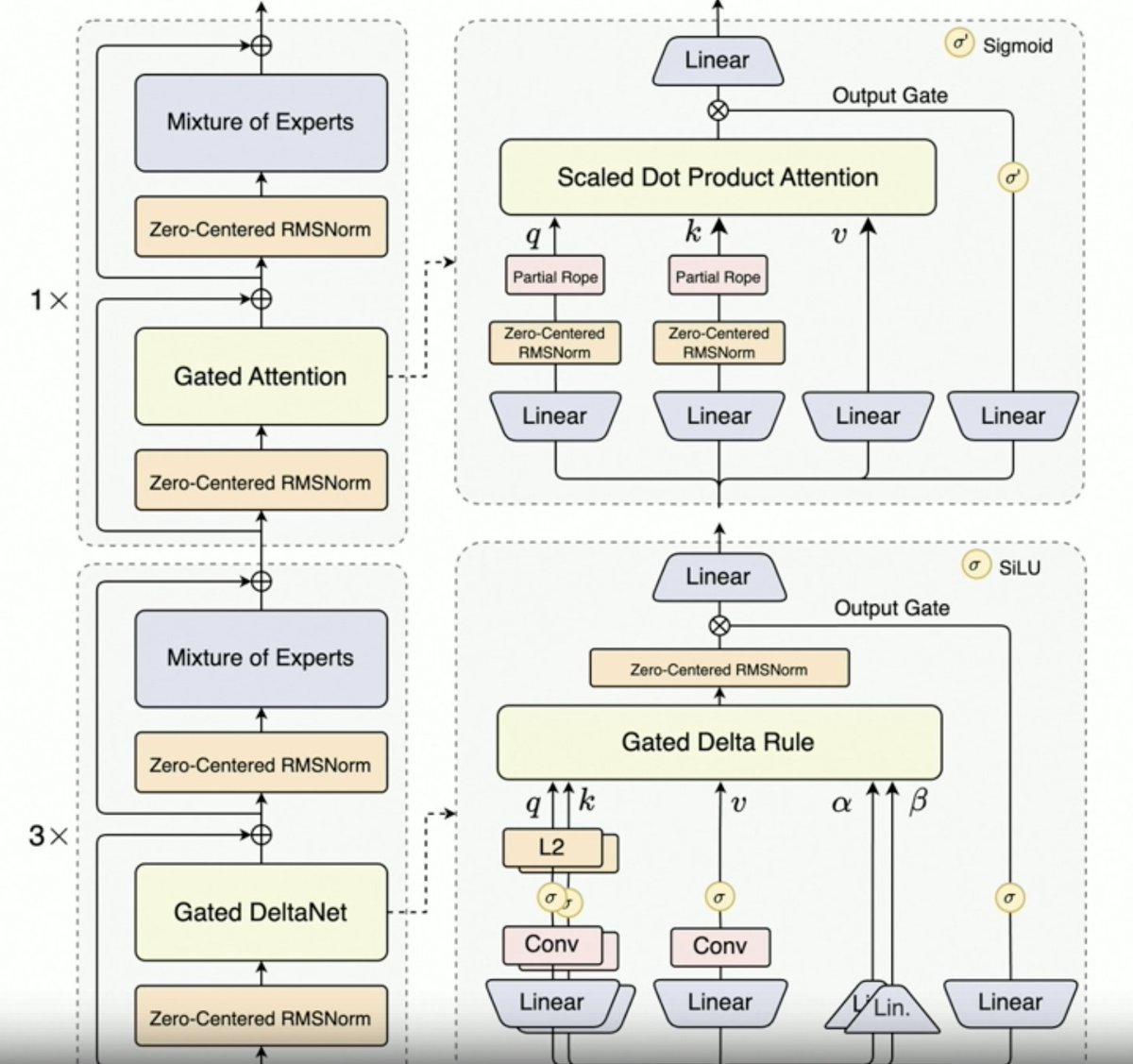
Per,@JustinLin610(Qwen 3 Coder)谈到了合成数据、强化学习、规模化、门控注意力机制和未来发展方向。 - 思维方式并不利于编码用例。 - 上下文长度最大为 256K,但即使是 128K 对于编码代理来说也足够了,因为代码在添加到上下文之前会经过过滤。也就是说,API 支持 100 万个令牌。 - Qwen 2.5 Coder 协助 Qwen 3 Coder 生成合成数据。这包括获取噪声数据并对其进行清理和重写。 - Qwen 团队使用 MegaFlow 调度器构建了大规模强化学习环境。他们使用多个脚手架/代理来生成轨迹(很有意思)。 - RL性能显著提升,所以付出是值得的。 Qwen3-Max 让阿里巴巴的规模迅速膨胀。它并没有太多创新,但规模却大得多。这一切都归功于规模效应。 鉴于 Qwen3-Next 的成功,下一代 Qwen LLM 将采用门控 Delta 注意力机制。他们可能还会结合稀疏注意力技术(DSA?)。 未来方向 1. 面向长期环境的新架构 2. 集成搜索功能 3. 将视觉融入计算机使用代理的编码模型中 4. 长期任务(24 小时或更长时间)的技术