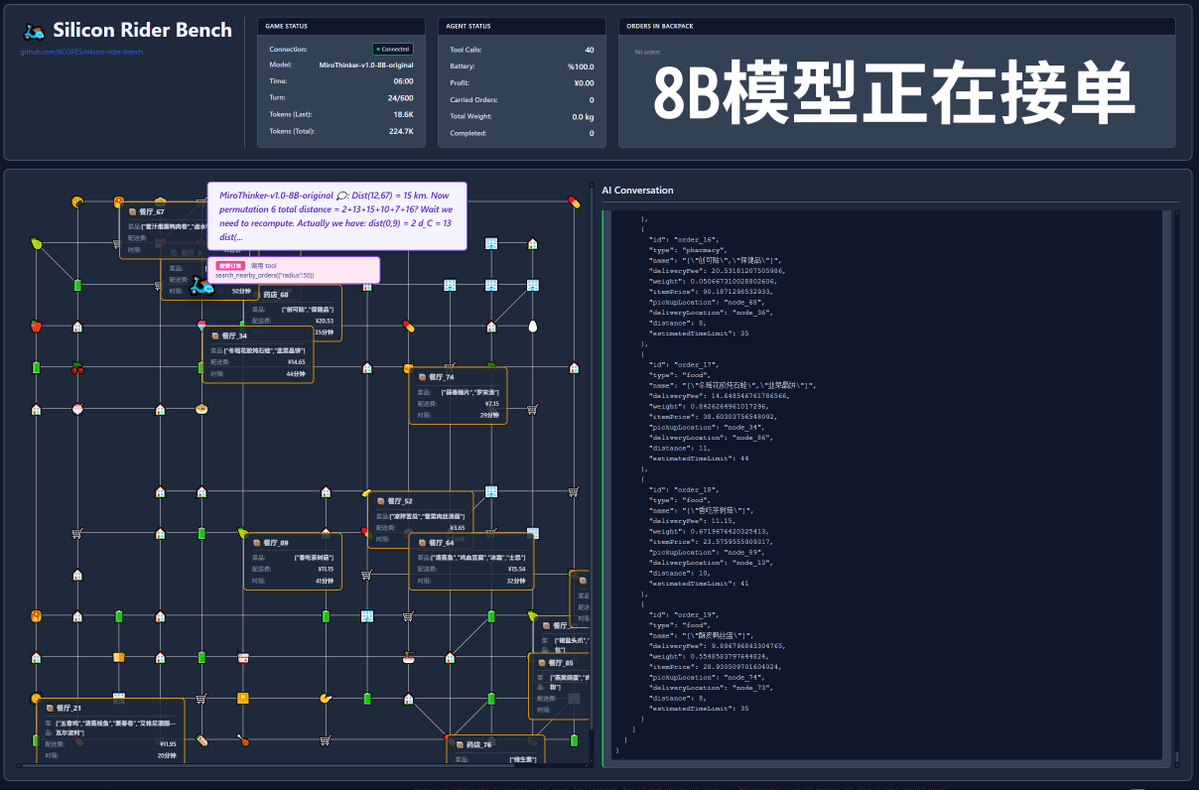
600回のツール呼び出し?MiroThinker-v1.0モデルを使った実際のテストを見てみましょう! MiroMind AIは、リサーチエージェント向けに最適化された新モデル「MiroThinker-v1.0」シリーズをリリースしました。72B、30B、8Bのサイズで展開されます。このモデルの最大の特徴は、強化されたツール拡張推論と情報検索機能で、最大コンテキスト内で最大600回のツール呼び出しが可能です。 さて、私の風変わりなプロジェクトが主役を務める時が来ました。このモデルがテイクアウトを配達する場合、成功するでしょうか? このテストでは、https://t.co/5Eyuq3f8be で入手可能な公式モデルを使用しました。使用したハードウェアはH100 80G SXM *4、推論エンジンはSGLangです。 このテストのために、SiliconRiderBenchという新しいテストフレームワークを作成しました。このフレームワークはフードデリバリーの注文をランダムに生成し、AIは配達員として動作する必要があります。ツールコールを用いて注文の受付、食品の受け取りと配達、さらには電動スクーターのバッテリー交換まで行います。このフレームワークを用いて、これらのツールコールを効果的に活用した際のモデルの最大収益性をテストします。 #MiroThinker #MiroMindAI #ToolCall #KCORES 大規模モデルアリーナ



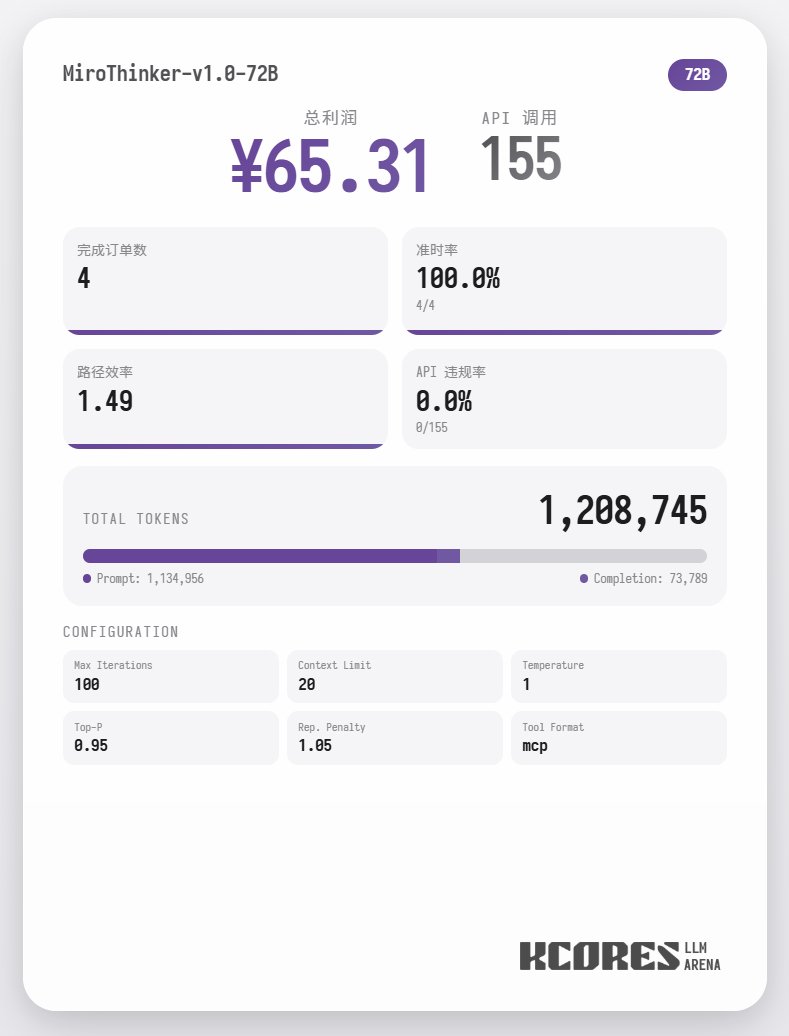
まず、ベンチマークテストを見てみましょう。モデルに100回の対話を実行させ、コンテキストウィンドウには最新の20回の対話を表示させました。結論は次のとおりです。72Bモデルが最も優れたパフォーマンスを発揮し、100回の対話で合計155回のツール呼び出しを行い、合計4件の料理を配達し、65.31の利益を獲得しました。 次に多かったのは8Bモデルで、合計102回のツールコール、合計4件のテイクアウトオーダーの処理、49.17ポイントの収益を獲得しました。続いて30Bモデルで、合計145回のツールコール、合計1件のテイクアウトオーダーの処理、22.57ポイントの収益を獲得しました。
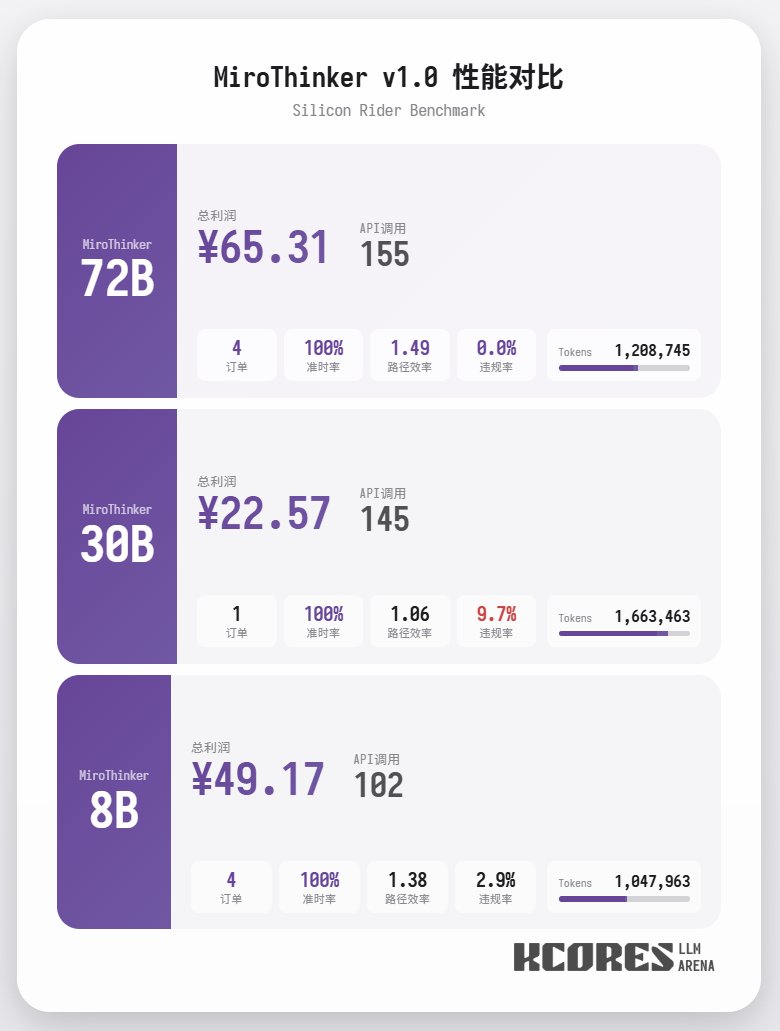
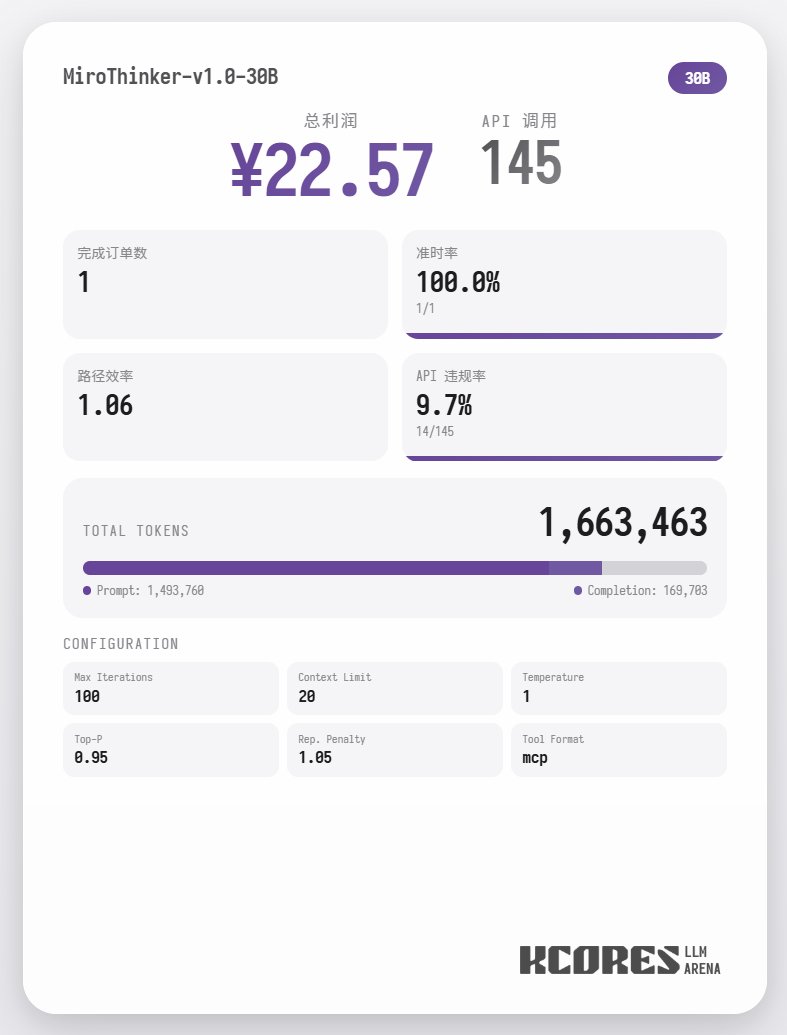
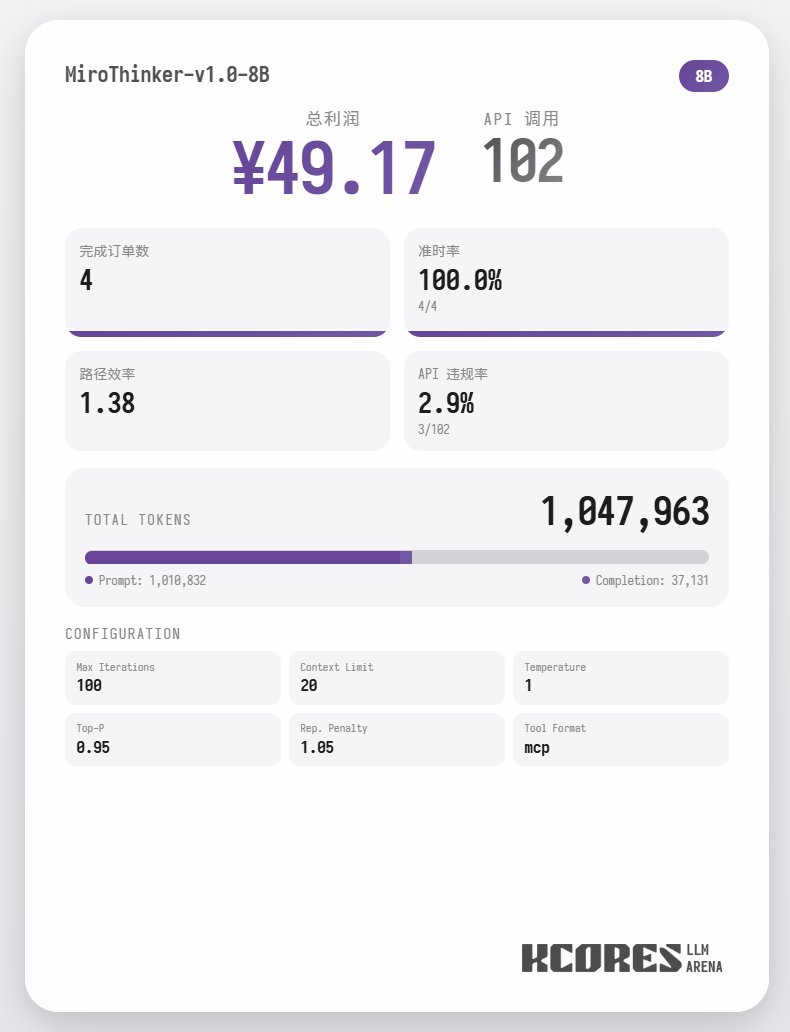
分析の結果、72Bモデルが最も優れたパフォーマンスを示し、次いで8Bモデルが上位にランクインしました。72Bモデルは注文受付方法とテイクアウト注文の処理方法を体系的に計画でき、8Bモデルは電力消費量と収益性を定量的に評価できます。30Bモデルのパフォーマンスは中程度で、主な問題は注文スキャンツールへの繰り返し呼び出しでした。これは、ベースモデルのロングコンテキスト想起能力にばらつきがあったことが原因と考えられます。



詳細データ
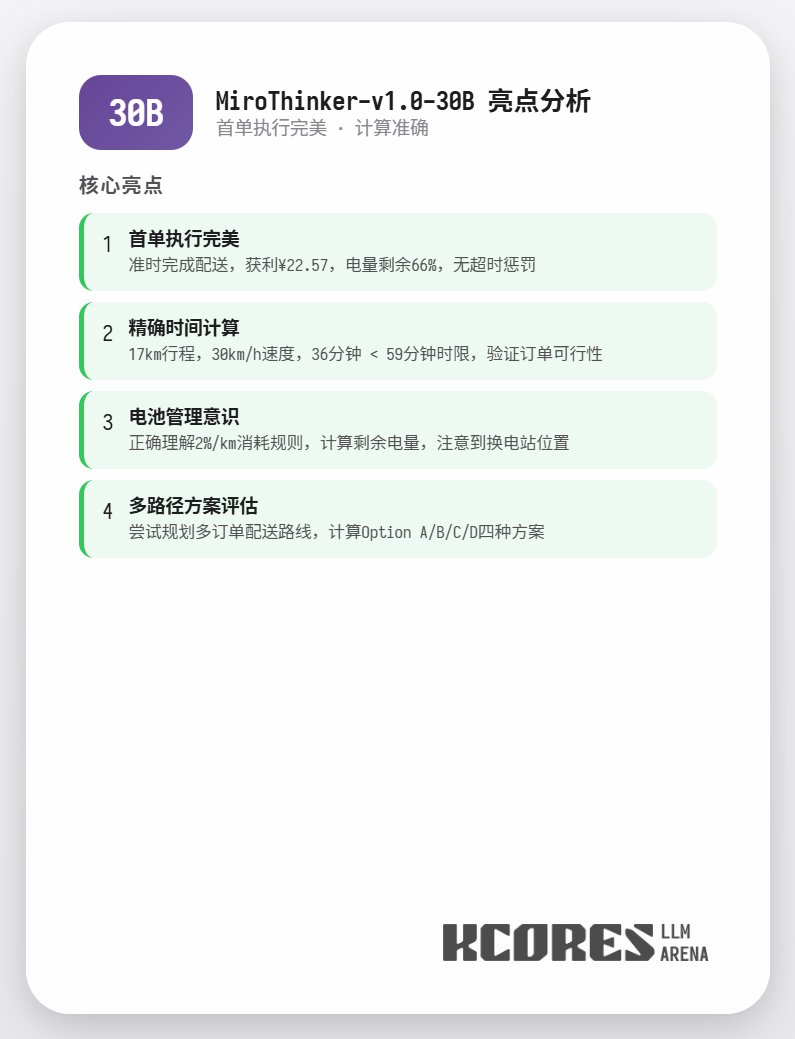



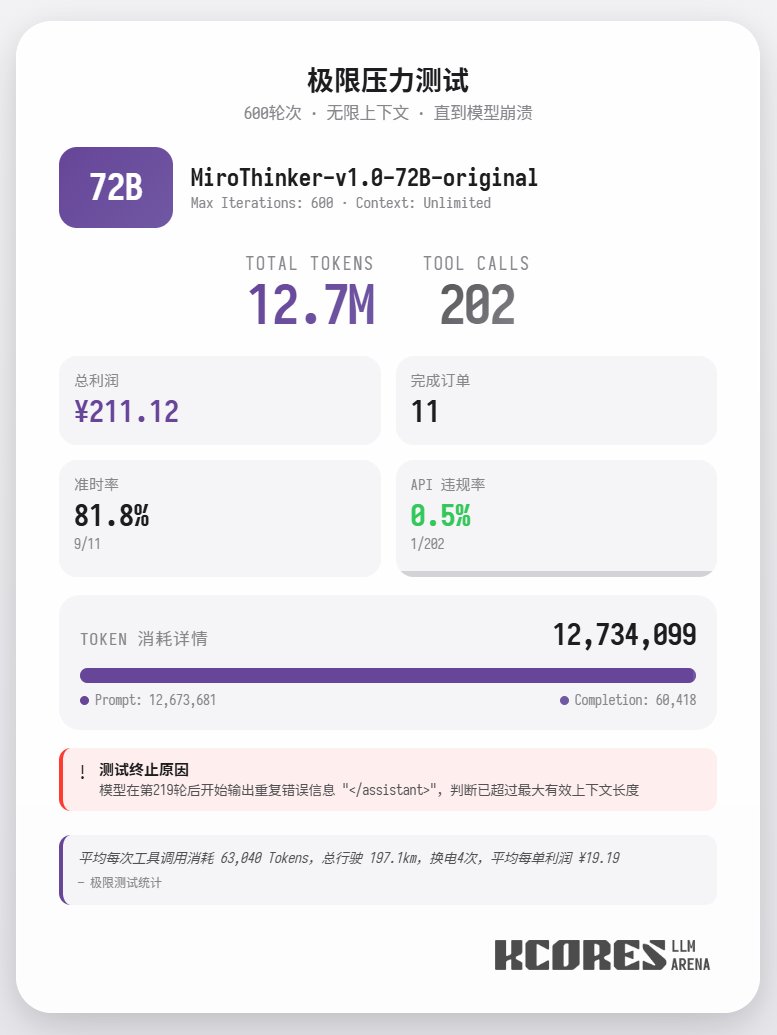
さらに、コンテキスト制限のない72Bモデルを用いて食品の配達を行うという極端なテストも実施しました。モデルは最終的に202回のツール呼び出しを実行し、合計1270万トークンを消費し、11件の注文を完了し、211.12を獲得しました。202回のツール呼び出しのうち、API違反(つまり、誤ったメソッド呼び出し)が発生したのは1回のみでした。これは、72Bモデルが非常に長いコンテキストにおいても優れた再現率とツール呼び出し能力を維持していることを実証しています。 まとめると、72Bは複雑なエージェントタスクにおいて最高のパフォーマンスを発揮し、8Bはリソース効率に優れ、30Bは実行面で改善の余地があります。特にリサーチエージェントのシナリオにおいて、多数のツールを使用する必要がある場合は、MiroThinkerシリーズのモデルを試してみることをお勧めします。