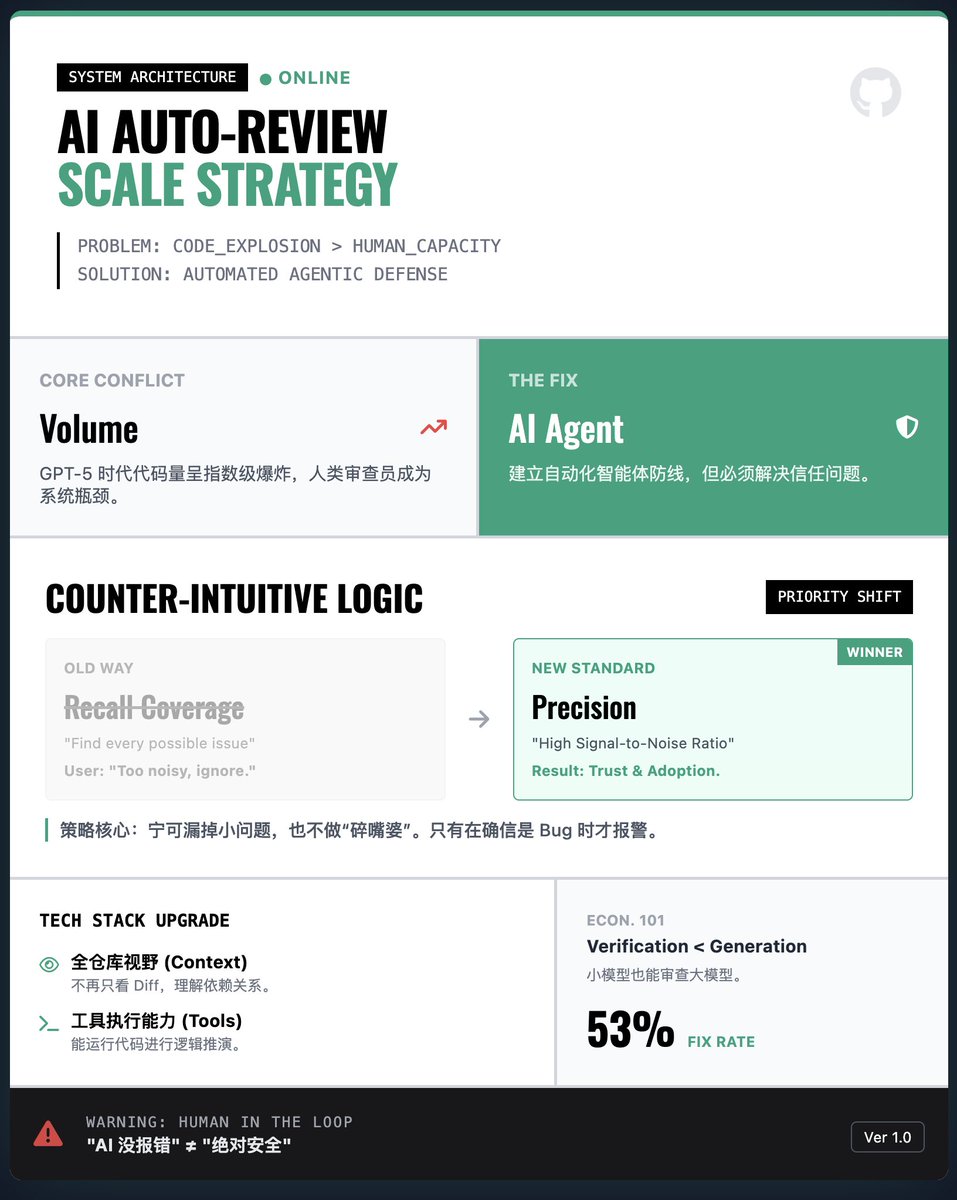
OpenAI 如何建構大規模AI 自動化程式碼審查系統? 核心挑戰:代碼量爆炸vs. 人力瓶頸隨著AI(如GPT-5-Codex)產生的代碼呈指數級增長,人類無法逐行審查。如果單純依賴AI 產生而不加驗證,漏洞和Bug 的風險將難以控制。因此,OpenAI 提出必須建立一個自動化的程式碼審查智能體作為防線。 關鍵策略:精準度優於覆蓋率(反直覺!) · 通常邏輯:我們會希望AI 找出所有潛在問題。 · OpenAI 的發現:在實際工程中,如果AI 像個「碎嘴婆」一樣報告大量無關緊要或錯誤的瑣碎問題,開發者會直接棄用工具。 · 解決方案:為了贏得開發者的信任,該系統被設計為“寧缺毋濫”,優先保證高信噪比,只在確信是重要Bug 時才發出警報,即便這以此會漏掉一些小問題為代價。 技術突破:全倉庫上下文與工具使用· 早期的驗證模型通常只看程式碼的差異,缺乏上下文。 · 新的審查智能體具備了全倉庫的視野,並且擁有執行程式碼的能力。這意味著它不僅是「看」程式碼,還能結合整個專案的依賴關係進行邏輯推演,從而大幅提高了審查的準確性。 經濟學視角:驗證比生成更便宜· 文章提出了一個有趣的觀察:產生正確的程式碼需要大量的運算資源,但驗證程式碼通常只需要很少的資源。 · 即使是用較小的算力預算,審查智能體也能有效地捕捉到大部分由強大模型產生的錯誤。這為大規模部署提供了經濟基礎。 實際應用與警示· 實戰效果:本系統已在OpenAI 內部及GitHub 上大規模使用。數據顯示,約53% 的AI 審查意見被開發者採納並進行了程式碼修改,證明了其建議的高價值。 · 過度依賴風險:AI 審查只是「輔助」而非「替代」。團隊必須警惕將「AI 沒報錯」等同於「絕對安全」的心理懈怠。 閱讀報告