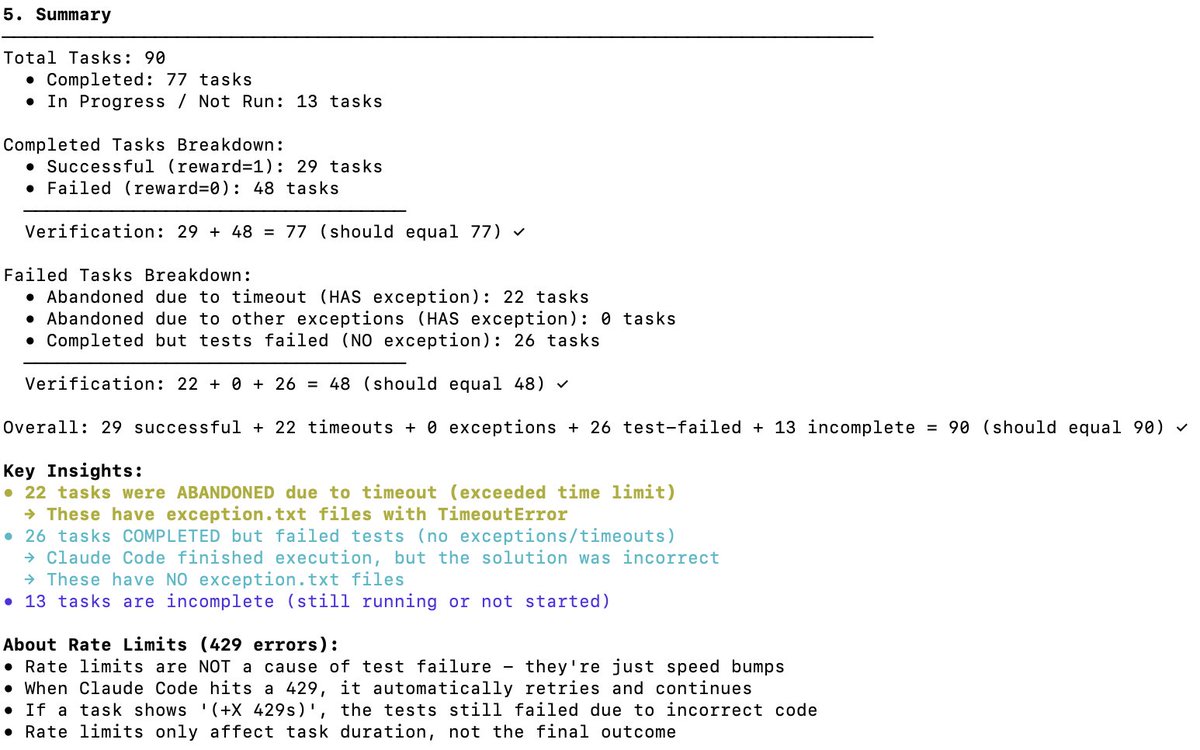
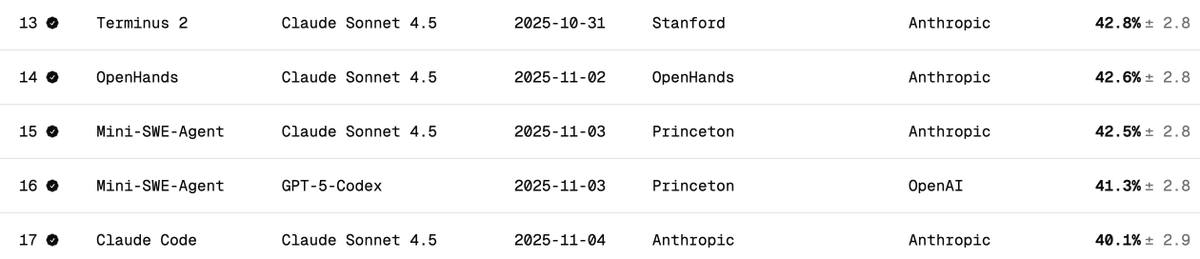
DeepSeek V3.2의 Terminal Bench 2 성능을 독립적으로 검증 터미널 벤치는 모델이 터미널 시나리오(예: Claude Code, Codex CLI, Gemini CLI)에서 에이전트를 어떻게 지원하고 실행하는지 측정합니다. 제 생각에는 AI 소프트웨어 개발에 가장 중요한 LLM 벤치마크입니다. AI가 CLI를 작동시켜 소프트웨어를 다운로드하고, 코드를 개발하고, 테스트하는 등의 작업을 수행합니다. 공식 점수는 어떻게 되나요? DeepSeek v3.2의 공식 점수는 아래 표에 나와 있듯이 46.4점(사고력)과 37.1점(사고력 없음)입니다. 논문에 보고된 대로 Claude Code 도구를 사용했습니다. 이 벤치마크에서 Claude Code + Sonnet 4.5의 성능은 어떻습니까? 아래는 다양한 하네스에 대한 클로드 소네 4.5점의 최종 벤치 점수입니다. 클로드 코드 하네스의 경우 약 40%입니다. Claude Code Harness를 사용한 DeepSeek V3.2의 점수는 얼마였나요? DeepSeek-Reasoner(Thinking)로 테스트했습니다. 약 90개의 테스트 중 77개가 Harbor(오케스트레이터)가 작동을 멈추기 전에 실행되었습니다. 편향되지 않은 샘플이라고 가정할 때, 77개라는 숫자는 대략적인 상황을 파악하기에 충분한 수치입니다. - 29 - 성공했습니다 - 48 - 실패(22번의 시간 초과 + 26번의 잘못된 코드 생성) 이를 통해 점수는 38%가 됩니다(꽤 인상적이고, 이미 클로드 코드 + 소네트 4.5의 40%에 가깝습니다). 하지만 DeepSeek v3.2 모델에 더 많은 시간이 허용된다면, 시간 초과된 작업을 더 많이 완료할 수 있을 것이며, 38%를 훨씬 상회할 것입니다. 아마도 50%까지 도달할 수 있을 것으로 예상됩니다. 하지만 그렇게 되면 더 이상 단순 비교는 불가능해질 것입니다(테스트 개발자들은 시간 초과 설정을 변경하지 말라고 권고합니다). 다른 OSS 모델과의 비교: 아래는 Terminus 2 하네스를 사용합니다. 1. 키미 K2 씽킹 - 35.7% 2. 미니맥스 M2 - 30% 3. 퀀 3 코더 480B - 23.9% 결론: OSS 모델의 성능은 SOTA이고, 놀랍게도 Claude 4.5와 거의 비슷했습니다. 하지만 제 점수는 DeepSeek 팀의 점수인 46.4보다 낮았습니다(마지막 13개 테스트는 실행하지 않았습니다). Claude 코드의 동작 방식이 변경되었을 가능성이 있습니다. Claude 코드는 DeepSeek v3.2에서 익숙하지 않거나 제대로 처리하지 못할 수 있는 특정 방식(예: )으로 모델을 표시합니다. DeepSeek에 Anthropic API 엔드포인트가 있다는 걸 알게 되어서 좋았습니다. 덕분에 Claude Code 테스트가 훨씬 수월해졌습니다. Docker에 settings.json 파일만 추가하면 됩니다. DeepSeek(@deepseek_ai)는 어떻게 그 점수를 달성했는지 투명하게 공유해야 합니다. 비용 및 캐시 히트: 이게 가장 놀라운 부분입니다. 77개 테스트를 실행하는 데 6달러밖에 들지 않았습니다(Harbor는 어떤 이유에서인지 마지막 13개는 포기했습니다). 거의 1억 2천만 개의 토큰이 처리되었지만, 대부분의 토큰이 입력 상태였고 나중에 캐시 히트가 발생했기 때문에 (DeepSeek은 디스크 기반 캐싱을 자동으로 구현합니다) 비용이 상당히 낮았습니다. 터미널 벤치 팀에 대한 요청: 모든 작업을 완료하기 전에 종료된 작업을 쉽게 다시 시작할 수 있도록 해주세요. 이 멋진 벤치마크에 감사드립니다. @terminalbench @teortaxesTex @Mike_A_Merrill @alexgshaw @deepseek_ai