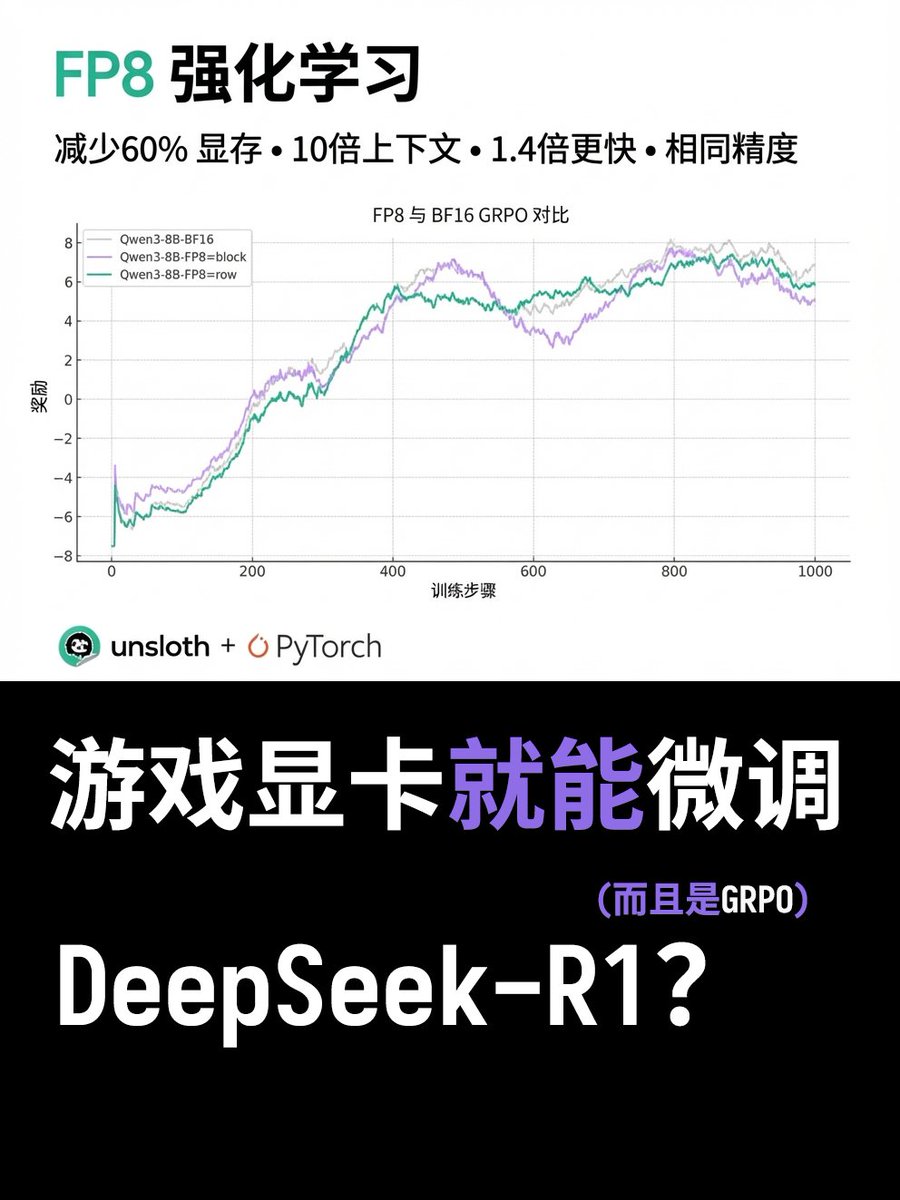
遊戲卡也能FP8 GRPO了? Unsloth 剛發了個新教程,用極少的顯存就能嘗試DeepSeek-R1 的FP8 GRPO 微調! 他們與PyTorch 合作,使FP8 RL 推理速度提高了1.4 倍。然後微調的顯存減少60%,上下文長度延長了12 倍. 現在就能在unsloth 框架使用. 這個直接能普及FP8精確度的強化學習,讓FP8 GRPO 現在可以在消費級GPU(如RTX 40、50 等)上實現。測試資料是,想要Qwen3-1.7B 的FP8 GRPO, 現在只需5GB 顯存就能運作。 教學地址: