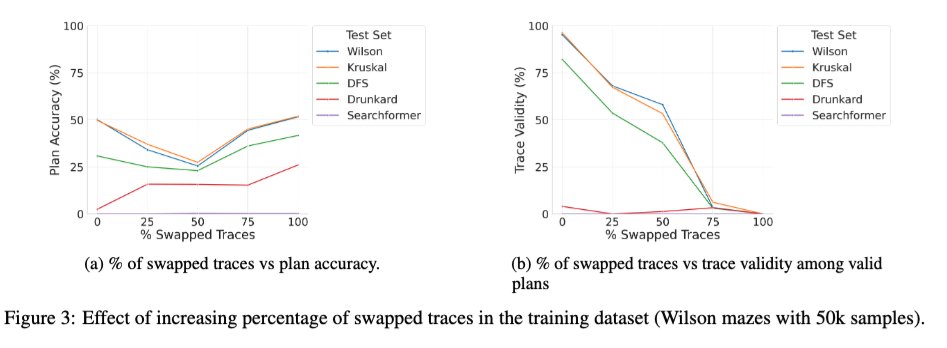
We just uploaded an expanded version of the "Beyond Semantics" paper--our systematic study of the role of intermediate tokens in LRMs--to arXiv, and it may be of interest to some of you. 🧵 1/ One intriguing new study is the effect of training the base transformer with a mix of correct and incorrect traces. We notice that as the % of incorrect (swapped) traces during training goes from 0 to 100, the trace validity of the models at inference time falls down monotonically (plot on right below) as expected, but the solution accuracy exhibits a U-curve (plot on left)! This suggests that what seems to matter is the "consistency" of the traces used during training rather than their correctness.