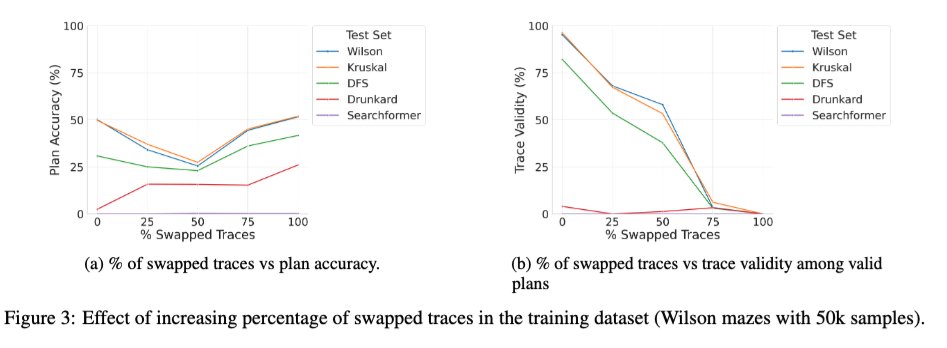
LRM における中間トークンの役割に関する体系的な研究である「Beyond Semantics」論文の拡張版を arXiv にアップロードしました。興味を持っていただける方もいらっしゃるかもしれません。🧵 1/ 興味深い新しい研究の一つは、正しいトレースと間違ったトレースを混ぜてベーストランスフォーマーをトレーニングした場合の効果です。トレーニング中に間違った(入れ替わった)トレースの割合が0から100に変化すると、推論時のモデルのトレース妥当性は予想通り単調に低下します(右下のグラフ)。しかし、解の精度はU字曲線を描きます(左下のグラフ)。これは、トレーニング中に使用されるトレースの正確性ではなく、「一貫性」が重要であることを示唆しています。
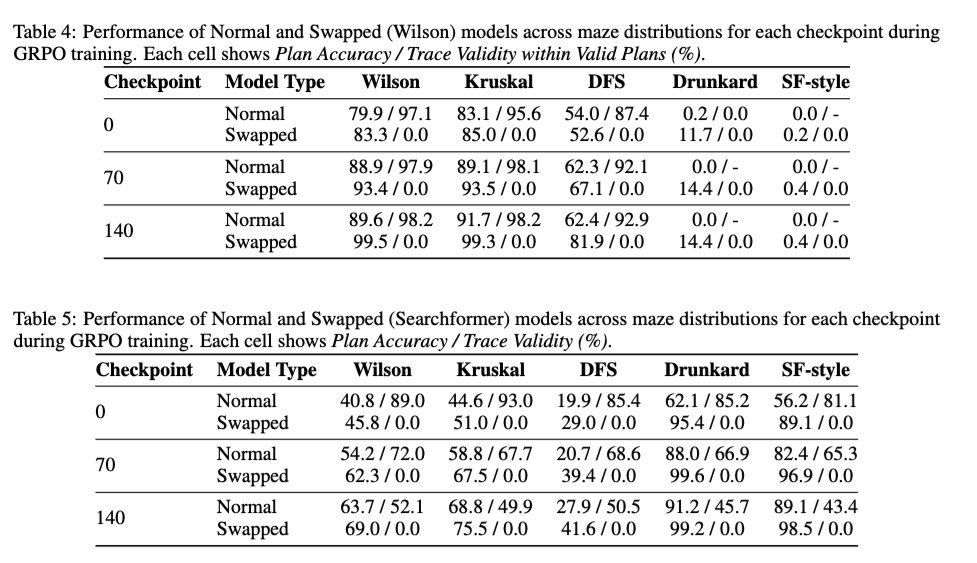
2/ DeepSeek R1スタイルの強化学習がトレース妥当性に与える影響についても検証し、強化学習がベースモデルのトレース妥当性を向上させるかどうかを検証しました。結果は、強化学習がトレース妥当性に基本的に中立的であることを示しています。強化学習は、トレースを100%入れ替えたモデルで学習した場合でも、トレース妥当性を高めることなく解の精度を向上させます。
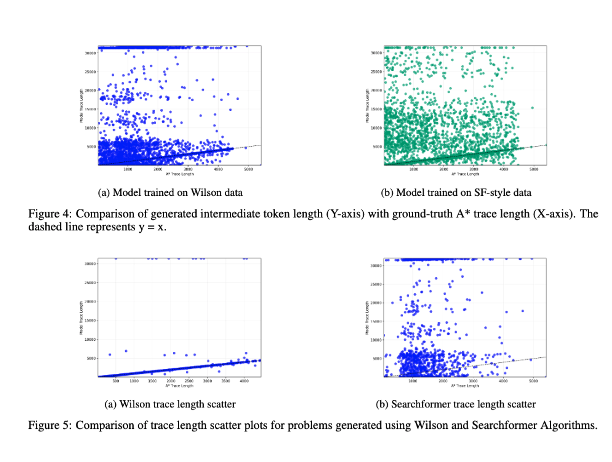
3/ 最後に、中間トークンの長さと問題インスタンスの計算複雑度との相関関係について調査しました。結果は、両者の間に相関関係がないことを示しています!(この実験の以前のバージョンについては、https://t.co/RL9ZEOKbpQ で説明しました。)
4/ 新しいバージョンは https://t.co/4LGWfiCZ5arxiv.org/abs/2505.13775催される #NeurIPS2025 の LAW、ForLM、Efficient Reasoning ワークショップでも、主著者の @karthikv792、@kayastechly、@PalodVardh12428 によって発表されます。ぜひお立ち寄りいただき、お話ししましょう!