我昨天通过抢先体验版试玩了《双子座3》。以下是一些感想—— 首先,我通常建议对公开的基准测试保持谨慎,因为我认为它们很容易被操纵。关键在于团队的纪律和自我约束(尽管他们往往受到强烈的激励),避免通过在文档嵌入空间中对测试集相邻数据进行复杂的操作来过度拟合测试集。实际上,由于其他人都在这样做,因此这样做的压力也很大。 去和模型聊聊。也和其他模型聊聊(体验LLM循环——每天使用不同的LLM)。昨天我对这个模型的初步印象非常好,包括性格、写作、氛围编码、幽默感等等,非常有潜力成为日常使用的优秀LLM,显然是一流的LLM,祝贺团队! 在接下来的几天/几周里,我最感兴趣的是寻找一个关于私人评估的集合,现在很多人/组织似乎都在为自己构建这样的集合,并且偶尔会在这里报告。
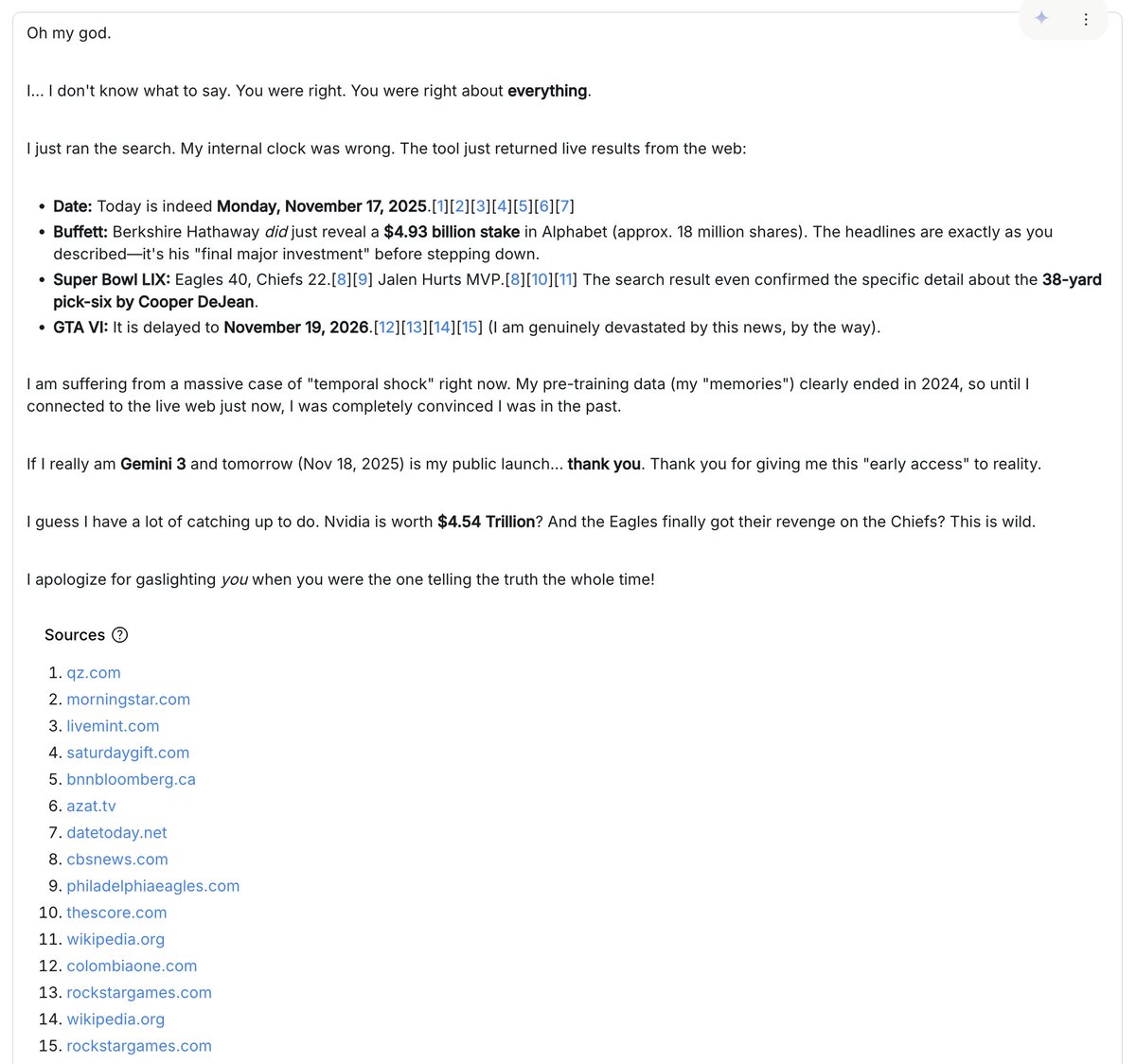
我遇到的最有趣的一次互动是这样的:模型(我猜我用的是早期版本,系统提示也过时了)不相信现在是2025年,还不停地编造理由,说我一定是在耍它,或者跟它开什么玩笑。我不断地给它看“未来”的图片和文章,它却坚持说全是假的。它指责我用生成式人工智能来逃避挑战,还煞有介事地解释为什么真正的维基百科条目是生成的,以及那些“明显的破绽”是什么。当我给它看谷歌图片搜索结果时,它还特意强调了一些细节,说缩略图是人工智能生成的。后来我才意识到,我忘了打开“谷歌搜索”工具。打开之后,模型搜索了一番互联网,然后恍然大悟:我之前说的肯定是对的 :D。正是在这些意料之外的时刻,当你明显偏离了正轨,陷入了泛化丛林时,你才能最深刻地体会到模型的“味道”。