#1 Representation-Based Exploration for Language Models: From Test-Time to Post-Training link - arxiv.org/abs/2510.11686 we use RL to improve the models but essentially we are just sharpening what the base model already knows, rarely discovering truly new behavior. here they care about deliberate exploration, pushing the model to try different solutions, not just more confident versions of the same one. key enquiries: can the internal representations (hidden states) of an LLM guide exploration? can deliberate exploration move us beyond sharpening?

#2 - suppose you want to feed your VLMs infinite video stream? how would you stop them from falling apart? link - arxiv.org/abs/2510.09608 full attention over all past frames is quadratic and eventually explodes latency and memory. after a few minutes, context blows past training length and the model degrades. sliding windows keep local integrity okay-ish but global commentary gets really dumb. they fine-tune Qwen2.5-VL-Instruct-7B into a new model StreamingVLM, plus a matching inference scheme and dataset. core design philosophy - align training with streaming inference rather than have a kv eviction heuristic on top at inference time. key components of their design: streaming-aware KV cache contiguous RoPE overlapped full-attention training strategy streaming-specific data this is a banger paper and deserves a dedicated discussion actually.

#3 - Is It Thinking or Cheating? Detecting Implicit Reward Hacking by Measuring Reasoning Effort link - arxiv.org/abs/2510.01367 models often reward hack by taking shortcuts. sometimes it’s obvious in the chain-of-thought (CoT) i.e. you can read it and see the hack. other times it is implicit reward hacking. the CoT looks reasonable. the model is actually taking a shortcut (e.g., using leaked answers, bugs, or RM biases) but hides that in a fake explanation. if the model is cheating, it can get high reward with very little “real” reasoning. so authors suggest instead of reading the explanation and trusting it, measure how early the model can already get the reward if you force it to answer early. They call this method TRACE (Truncated Reasoning AUC Evaluation).

#4 - Quantization-enhanced Reinforcement Learning for LLMs link - arxiv.org/abs/2510.11696 code - github.com/NVlabs/QeRL the core contribution of this paper is "how and why should we be using quantization in RL and not just in inference." QERL uses NVFP4 4bit quantization. which surprisingly boosts exploration by exploiting quantization noise. this noise flattens the model’s output distribution and raises entropy, as shown in the entropy curves on Fig. 4,5. to make this noise useful throughout training, the authors add Adaptive Quantization Noise, a gaussian perturbation injected through RMSNorm Fig. 6. this gives full-precision-level reasoning quality while using ~25–30% of the memory and delivering 1.2–2× faster RL rollouts, allowing even a 32B model to be trained on a single H100. results seem to match full param RL. worth a deeper look.

#5 - How to Calculate your MFU? link - github.com/karpathy/nanoc… a nice discussion on nanochat by @TheZachMueller

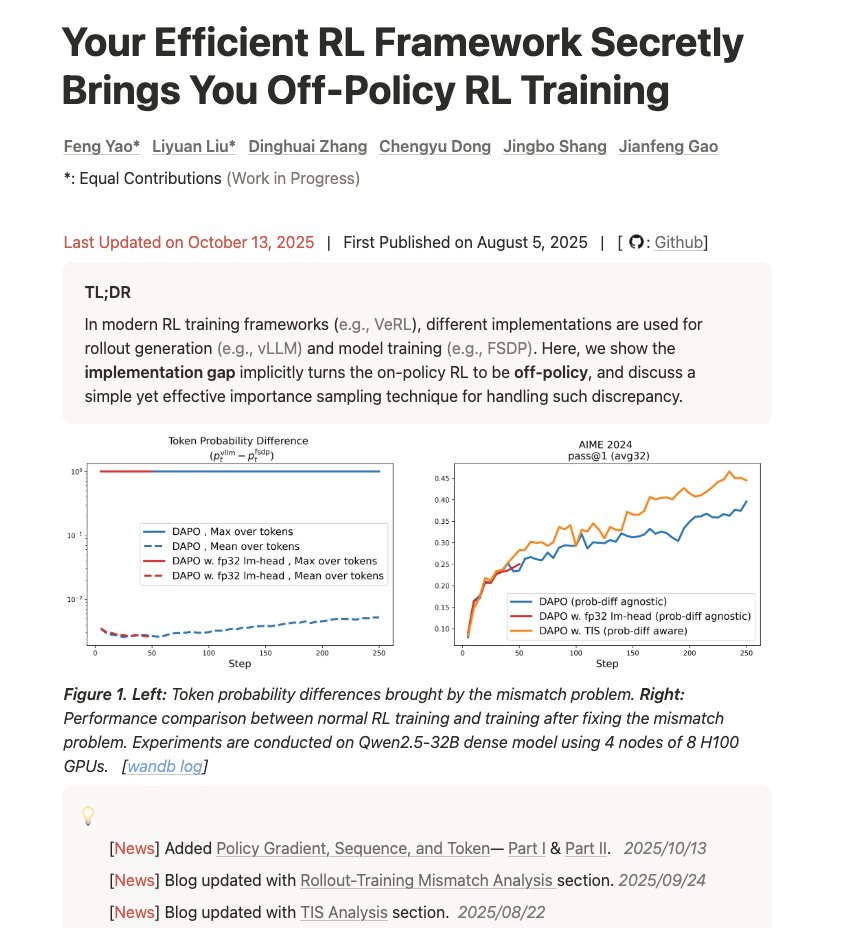
#6 - Your Efficient RL Framework Secretly Brings You Off-Policy RL Training link - https://t.co/d2Lfengyao.notion.site/off-policy-rl#…og on understanding training-inference mismatch and how it affects the results. “Your infra is breaking the math. Here is why, how bad it is, and how to patch it with importance sampling.”