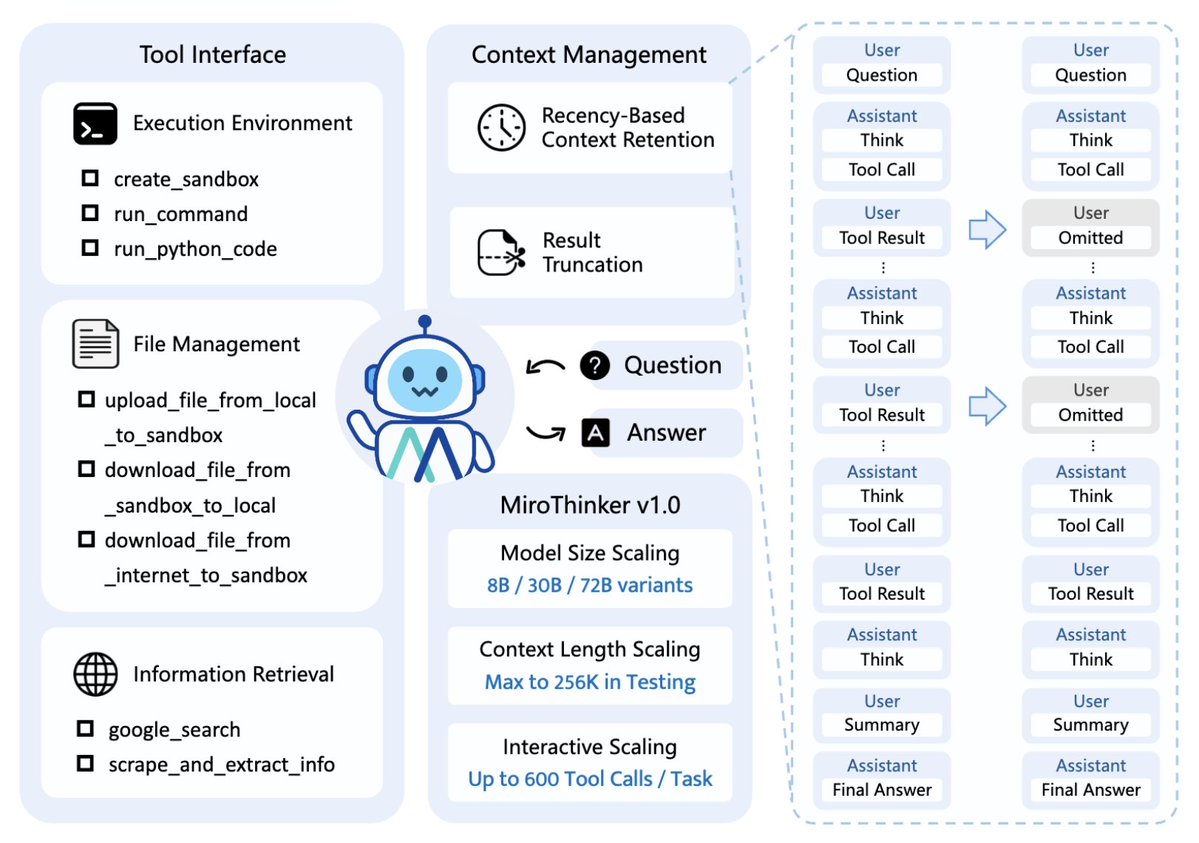
MiroMind 팀은 완전히 새로운 오픈소스 bAgent 모델인 MiroThinker v1.0을 출시했습니다. 가장 큰 혁신은 "대화형 스케일링"이라는 새로운 개념을 도입한 데 있습니다. 스케일링 법칙의 병목 현상을 극복하고 AI가 스스로 진화할 수 있도록 합니다. 이 개념은 "모델 크기가 클수록 성능이 더 좋다"는 기존의 선형적 성장 패턴에서 벗어나, "모델과 환경 간의 상호작용의 깊이와 빈도"가 지능적 성장의 핵심 요소라는 점을 강조합니다. MiroThinker는 외부 도구(예: 검색 엔진, Linux 샌드박스, 음성 인식 등)와의 다양한 상호작용과 추론을 지원하여 사용자가 도구를 유연하게 사용하여 정보를 얻고 작업을 완료할 수 있도록 합니다. - 256K 맥락: 엄청난 양의 정보(수십만 개의 단어)를 기억할 수 있습니다. - 최대 600개의 도구 호출을 동시에 실행할 수 있습니다. AI는 검색, 코드 실행, 계산, 번역 등의 외부 도구를 지속적으로 활용할 수 있습니다. - 복잡한 추론과 장시간 걸리는 작업에도 대응할 수 있어야 합니다. 단순히 질문에 답하는 것이 아니라 단계별로 생각하고, 정보를 조사하고, 해결책을 비교할 수 있어야 합니다. "딥 인터랙션 스케일링"이란 무엇인가요? 성능 ∝ 모델-환경 상호 작용 깊이 × 반사 주파수 다시 말해서: - 모델은 지식을 수동적으로 흡수하지 않고 환경과 적극적으로 상호 작용합니다. - 시행착오와 반성을 통해 모델은 정책 공간에서 '진화'할 수 있습니다. AI가 "행동"을 많이 할수록 오류를 수정하고 추론의 질을 향상시킬 수 있습니다. 인간이 복잡한 것을 진정으로 배울 수 있는 것은 반복적인 시행착오와 실습을 통해서만 가능합니다. 🧩 예를 들어: 사람이 요리하는 법을 배우는 것과 마찬가지로, 단순히 요리법을 보는 것만으로는 충분하지 않습니다. 직접 시도하고, 실패하고, 고치고, 다시 시도해야 합니다. AI에게 여러 차례의 환경 상호작용과 피드백 교정은 지능적 진화의 진정한 원동력입니다. 각 상호작용은 "학습"의 기회가 되며, 지능은 점점 더 강력해집니다. 따라서 MiroThinker는 "컨텍스트 길이"와 "상호작용 라운드 수"를 모두 한계까지 끌어올려 진정한 "사고 루프"를 형성합니다.
여러 국제 평가에서 GPT-5 고급 버전에 근접하거나 이를 초과하는 점수: 복잡한 웹 페이지를 이해하는 BrowseComp 테스트에서 47.1%의 성적을 거두어 OpenAI의 DeepResearch(51.5%)에 근접했습니다. 인간 궁극적 추론 테스트(HLE)에서 GPT-5-high보다 우수한 성과를 보였습니다. DeepSeek-v3.2보다 중국어 작업에서 약 7.7퍼센트 포인트 더 나은 성능을 보였습니다.

완전히 오픈 소스이며 재현 가능합니다. MiroThinker v1.0의 모든 핵심 리소스는 오픈 소스입니다. 여기에는 다음이 포함됩니다. - 모델 가중치 - 추론 및 상xiaohu.ai/c/a066c4/mirot… 인프라 - 평github.com/MiroMindAI/Mir… 자세한 소개: https://t.co/wpST53dHtd GitHub: https://t.co/KQZr8sTcby