很高兴发布新的代码库:nanochat!(这是我写过的最疯狂的代码库之一)。与我之前类似的代码库 nanoGPT(仅涵盖预训练)不同,nanochat 是一个极简的、从零开始的全栈训练/推理流程,它是基于一个单一的、依赖最少的代码库构建的简单 ChatGPT 克隆版本。你启动一个云 GPU 盒,运行一个脚本,只需 4 小时后,你就可以在类似 ChatGPT 的 Web UI 中与你自己的 LLM 对话。它大约有 8,000 行代码,在我看来相当简洁,用于:- 使用新的 Rust 实现训练标记器 - 在 FineWeb 上预训练 Transformer LLM,评估多个指标的 CORE 分数 - 使用 SmolTalk 的用户助手对话、多项选择题和工具使用进行中期训练。 - SFT,在世界知识多项选择题(ARC-E/C、MMLU)、数学(GSM8K)、代码(HumanEval)上评估聊天模型 - 可选使用“GRPO”在 GSM8K 上对模型进行强化学习 - 在具有键值缓存的引擎中高效推理模型,使用简单的预填充/解码、工具(轻量级沙箱中的 Python 解释器),通过 CLI 或类似 ChatGPT 的 WebUI 与其对话。 - 编写一份 Markdown 报告卡,总结并游戏化整个过程。即使成本低至约 100 美元(在 8XH100 节点上约 4 小时),您也可以训练一个小型 ChatGPT 克隆模型,您可以与之对话,它可以编写故事/诗歌,回答简单的问题。大约 12 小时超过了 GPT-2 的核心指标。随着成本进一步增加到约 1000 美元(约 41.6 小时的训练),它很快就会变得更加连贯,可以解决简单的数学/代码问题并参加多项选择题测试。例如,一个训练了24小时的深度为30的模型(这大约相当于GPT-3 Small 125M和GPT-3的千分之一的FLOPs)在MMLU上可以达到40秒,在ARC-Easy上可以达到70秒,在GSM8K上可以达到20秒,等等。我的目标是将完整的“强基线”堆栈整合到一个内聚、精简、可读、可破解、最大程度可分叉的仓库中。nanochat将是LLM101n的顶点项目(目前仍在开发中)。我认为它也有潜力发展成为一个研究工具或基准,类似于之前的nanoGPT。它远未完成、调整或优化(实际上我认为可能有很多唾手可得的成果),但我认为它的整体框架已经足够完善,可以上传到GitHub,在那里它的各个部分都可以进行改进。回复中提供了 repo 链接和 nanochat speedrun 的详细演练。

GitHub repo:hgithub.com/karpathy/nanoc…更详细、更专业的演练:https://t.co/YmHaZfNjcJ WebUI 中 100 美元github.com/karpathy/nanoc… :) 更大的模型(例如 12 小时深度 26 或 24 小时深度 30)很快就会变得更加连贯。

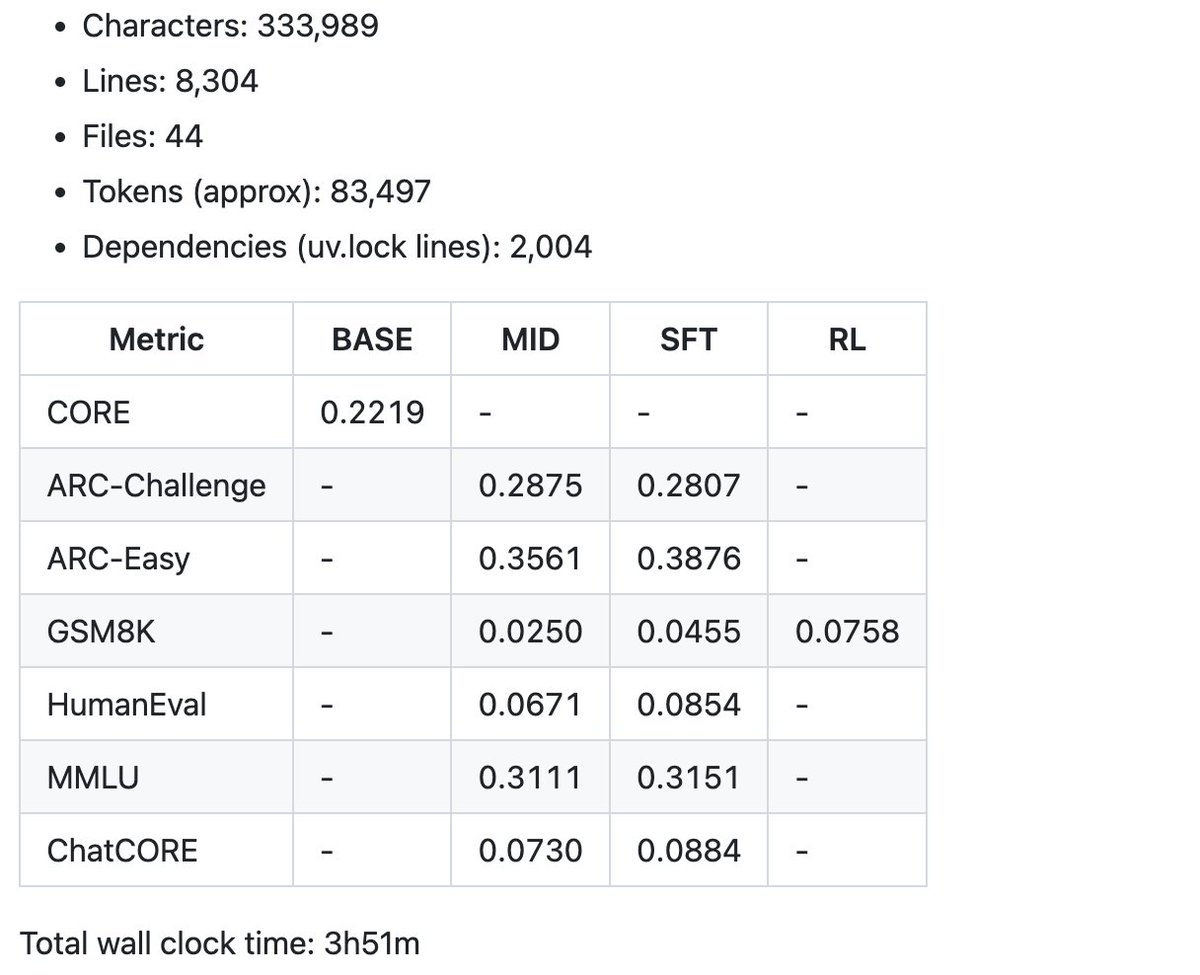
首先,在报告卡中,我们先来看看这次 100 美元速通产生的一些总结指标示例。目前的代码库略超过 8000 行,但我尽量保持代码简洁,并添加了充足的注释。接下来是有趣的部分——调优和爬坡。