Tang Jie (@jietang) é professor na Universidade Tsinghua e cientista-chefe de IA na Zhipu (empresa por trás dos modelos da série GLM). Ele também é uma das pessoas mais conhecedoras de modelos de grande escala na China. Recentemente, ele publicou um longo texto no Weibo (veja os comentários) discutindo suas perspectivas sobre modelos de grande escala em 2025. Curiosamente, Tang Jie e Andrej Karpathy compartilham muitas observações, mas também têm algumas ênfases diferentes. Analisar as perspectivas desses dois especialistas renomados lado a lado revela um panorama mais completo. O conteúdo é bastante extenso, mas há uma frase que gostaria de destacar no início: O princípio fundamental da aplicação de modelos de IA não deve ser a criação de novos aplicativos; sua essência é a IA que substitui o trabalho humano. Portanto, desenvolver IA capaz de substituir diferentes funções é a chave para sua aplicação. Se você está desenvolvendo aplicações de IA, deve considerar repetidamente esta afirmação: o princípio fundamental das aplicações de IA não é criar novos produtos, mas sim substituir o trabalho humano. Uma vez que você entenda isso, as prioridades em muitas áreas ficarão claras. O argumento central de Tang Jie possui sete camadas de lógica. --- Primeiro nível: O pré-treinamento não o matou, ele apenas deixou de ser o único protagonista. O pré-treinamento continua sendo a base para que os modelos adquiram conhecimento do mundo e habilidades básicas de raciocínio. Mais dados, parâmetros maiores e computação mais intensiva continuam sendo as maneiras mais eficientes de aprimorar a inteligência de um modelo. É como uma criança em crescimento: a quantidade de alimento (poder computacional) e nutrição (dados) deve ser suficiente. Essa é uma lei física que não pode ser contornada. Mas a inteligência por si só não basta. Os modelos atuais têm um problema: tendem a ser "desequilibrados". Para melhorar seus índices de desempenho, muitos modelos se concentram em problemas específicos, tornando-os menos eficazes em cenários complexos do mundo real. É como jogar uma criança em um ambiente de trabalho real após nove anos de educação obrigatória (pré-treinamento) para lidar com os problemas que não estão nos livros didáticos — é aí que as habilidades reais são desenvolvidas. Portanto, o próximo foco é no "treinamento intermediário e posterior". Essas duas etapas são responsáveis por "ativar" a capacidade do modelo, especialmente sua capacidade de alinhamento em cenas de cauda longa. O que são cenários de cauda longa? São aquelas necessidades incomuns, mas reais. Por exemplo, ajudar advogados a organizar contratos específicos ou auxiliar médicos na análise de imagens de doenças raras. Esses cenários representam uma pequena porcentagem do conjunto de testes geral, mas são cruciais em aplicações do mundo real. Embora os benchmarks gerais avaliem o desempenho do modelo, eles também podem levar ao sobreajuste em muitos modelos. Isso está de acordo com a visão de Karpathy de que "o treinamento no conjunto de teste é uma nova arte". Todos estão tentando melhorar suas classificações, mas alcançar pontuações altas na tabela de classificação não equivale a resolver problemas do mundo real. --- A segunda camada: Agente representa a transição de "estudante" para "pessoa trabalhadora". Tang Jie usou uma analogia vívida: Sem as capacidades dos agentes, um modelo complexo é apenas um "doutorado teórico". Não importa quantos livros alguém leia, mesmo atingindo o nível de pós-doutorado, se essa pessoa não consegue resolver problemas, ela é meramente um repositório de conhecimento, incapaz de gerar produtividade. Essa analogia é precisa. O pré-treinamento é como frequentar aulas, e o aprendizado por reforço é como praticar problemas, mas ambos ainda estão na "fase de aprendizado". O agente é a chave para fazer o modelo realmente "funcionar", e é o limiar para entrar no mundo real e gerar valor prático. A generalização e a transferência entre diferentes ambientes de agentes não são fáceis. As habilidades que você desenvolve em um ambiente de código podem não funcionar bem em um ambiente de navegador. A abordagem mais simples atualmente é acumular continuamente dados de mais ambientes e realizar aprendizado por reforço adaptado a esses ambientes. Anteriormente, ao desenvolvermos agentes, costumávamos anexar diversas ferramentas ao modelo. A tendência atual é incorporar diretamente os dados obtidos com essas ferramentas ao "DNA" do modelo para treinamento. Isso pode parecer um pouco bobo, mas é de fato o caminho mais eficaz no momento. Karpathy também listou o Agent como uma das mudanças mais importantes deste ano. Ele citou Claude Code como exemplo, enfatizando que o Agent deveria ser capaz de "viver no seu computador", chamando ferramentas, executando loops e resolvendo problemas complexos. --- A terceira camada: a memória é uma necessidade básica, mas ainda não está claro como obtê-la. Tang Jie dedicou uma quantidade considerável de tempo à discussão sobre memória. Ele acredita que a memória é essencial para que os modelos sejam implementados em ambientes do mundo real. Ele dividiu a memória humana em quatro camadas: - Memória de curto prazo, correspondente ao córtex pré-frontal - Memória de médio prazo, correspondente ao hipocampo As memórias de longo prazo estão localizadas no córtex cerebral. - Memória histórica humana, correspondente à Wikipédia e aos registros históricos. A IA também precisa imitar esse mecanismo; o modelo em larga escala pode corresponder a: - Janela de contexto → Memória de curto prazo - Busca RAG → Memória Intermediária - Parâmetros do modelo → Memória de longo prazo Uma abordagem é a "memória comprimida", que armazena informações importantes em um formato conciso e simplificado dentro do contexto. Os atuais "contextos ultralongos" abordam apenas a memória de curto prazo, essencialmente alongando o "bloco de notas" utilizável. Se a janela de contexto se tornar suficientemente longa no futuro, memórias de curto, médio e longo prazo poderão ser alcançadas. Mas existe um problema ainda mais difícil: como atualizamos o próprio conhecimento do modelo? Como alteramos os parâmetros? Este continua sendo um problema sem solução. --- A quarta camada: aprendizagem online e autoavaliação podem ser o próximo paradigma de escalonamento. Esta seção representa a parte mais voltada para o futuro do ponto de vista de Tang Jie. O modelo atual está "offline", o que significa que foi treinado, mas não sofre alterações. Isso apresenta diversos problemas: o modelo não consegue iterar de forma autônoma, o retreinamento desperdiça recursos e muitos dados interativos são perdidos. Idealmente, o modelo deveria ser capaz de aprender online, tornando-se mais inteligente a cada uso. No entanto, para alcançar isso, existe um pré-requisito: o modelo precisa saber se está correto ou não. Isso se chama "autoavaliação". Se o modelo consegue avaliar a qualidade de sua própria saída, mesmo que seja uma avaliação probabilística, ele conhece o objetivo da otimização e pode se aprimorar. Tang Jie acredita que construir um mecanismo de autoavaliação para um modelo é um problema difícil, mas também pode ser a direção do próximo paradigma de escalonamento. Ele usou vários termos: aprendizado contínuo, aprendizado em tempo real e aprendizado online. Isso reforça a ideia de Karpathy sobre o RLVR. O RLVR é eficaz justamente porque fornece "recompensas verificáveis", permitindo que o modelo saiba se está correto ou não. Se esse mecanismo puder ser generalizado para mais cenários, o aprendizado online poderá se tornar uma possibilidade. --- A quinta camada: O primeiro princípio das aplicações de IA é a "substituição de empregos". Esta é a frase que mais me inspirou: O princípio fundamental da aplicação de modelos de IA não deve ser a criação de novos aplicativos; sua essência é a IA que substitui o trabalho humano. Portanto, desenvolver IA capaz de substituir diferentes funções é a chave para sua aplicação. A essência da IA não é criar novos aplicativos, mas sim substituir empregos humanos. Dois caminhos: 1. Transformar softwares que antes exigiam intervenção humana em softwares de IA (Inteligência Artificial). 2. Criar software de IA que se alinhe a um trabalho humano específico, substituindo diretamente os trabalhadores humanos. O chat já substituiu parcialmente as buscas e também incorporou a interação emocional. O próximo passo é substituir o atendimento ao cliente, os programadores juniores e os analistas de dados. Portanto, o ponto de virada em 2026 reside na "IA substituindo diferentes empregos". Os empreendedores não devem pensar em "qual software quero desenvolver para os usuários", mas sim em "que tipo de funcionário de IA quero criar para ajudar o chefe a reduzir os custos de mão de obra para uma determinada função". Em outras palavras, em vez de pensar sempre em criar um novo produto "IA+X", pense primeiro em quais empregos humanos podem ser substituídos e, em seguida, trabalhe de trás para frente para determinar o formato do produto. Isso corrobora a observação de Karpathy sobre o "Cursor para X". Se o Cursor é essencialmente "a versão baseada em IA do trabalho do programador", então coisas semelhantes aparecerão em vários setores. --- Sexta camada: O modelo de domínio abrangente é uma "proposição falsa". Essa perspectiva pode incomodar algumas pessoas, mas Tang Jie é direto: o modelo específico de domínio é uma proposição falsa. Se estamos falando de IAG (Inteligência Artificial Geral), qual o sentido de uma "IAG específica de domínio"? A razão pela qual existem grandes modelos específicos de domínio é que as empresas de aplicativos não estão dispostas a admitir a derrota diante das empresas de modelos de IA e esperam construir uma vantagem competitiva com conhecimento do domínio e transformar a IA em uma ferramenta. Mas a essência da IA é um "tsunami" — ela varrerá tudo por onde passar. Algumas empresas em determinados setores inevitavelmente deixarão de lado suas vantagens competitivas e serão atraídas para o mundo da IAG (Inteligência Artificial Geral). Seus dados de domínio, processos e dados de agentes serão gradualmente incorporados ao modelo principal. É claro que os modelos de domínio existirão por muito tempo antes que a Inteligência Artificial Geral (IAG) se concretize. Mas quanto tempo durará esse período? É difícil dizer, porque a IA está se desenvolvendo muito rapidamente. --- A sétima camada: Inteligência multimodal e incorporada – um futuro promissor, mas um caminho difícil. A computação multimodal é certamente o futuro. Mas o problema atual é que ela oferece ajuda limitada para elevar o nível de inteligência da Inteligência Artificial Geral (IAG). Texto, multimodalidade e geração multimodal podem ser desenvolvidos de forma mais eficiente separadamente. É claro que explorar uma combinação dos três requer coragem e financiamento. A inteligência incorporada (robôs) é ainda mais complexa. O desafio é o mesmo que com agentes: versatilidade. Você ensina um robô a funcionar no cenário A, mas ele não funciona em outro. O que fazer? Coletar e sintetizar dados são tarefas difíceis e caras. O que fazer? Coletar dados ou sintetizá-los. Nenhuma das duas opções é fácil, e ambas são caras. Mas, por outro lado, à medida que a escala dos dados aumenta e surgem capacidades de uso geral, uma barreira de entrada se forma naturalmente. Outro problema frequentemente negligenciado é que os próprios robôs também representam um obstáculo. Instabilidade e falhas frequentes são problemas de hardware que limitam o desenvolvimento da inteligência incorporada. Tang Jie prevê que progressos significativos serão alcançados nessas áreas até 2026. --- Ao conectar o artigo de Tang Jie ao contexto geral, um roteiro bastante claro se revela: Atualmente, o escalonamento pré-treinado ainda é eficaz, mas deve-se dar mais ênfase ao alinhamento e às capacidades de cauda longa. Recentemente, os agentes representaram um avanço fundamental, permitindo que os modelos evoluíssem da "conversa" para a "ação". A médio prazo, sistemas de memória e aprendizagem online são cursos essenciais, e os modelos devem aprender a se autoavaliar e a iterar. A longo prazo, a substituição de empregos é a essência das aplicações, e a vantagem competitiva do setor será rompida pela Inteligência Artificial Geral (IAG). A longo prazo, as abordagens multimodais e corporificadas se desenvolverão de forma independente, aguardando a maturação da tecnologia e dos dados. --- Ao comparar os pontos de vista de Tang Jie e Karpathy, é possível observar diversos pontos de consenso: Em primeiro lugar, a principal mudança em 2025 é a atualização do paradigma de treinamento, passando de "pré-treinamento como método principal" para "colaboração em múltiplos estágios". Em segundo lugar, o Agent representa um marco, um salto fundamental para os modelos, da aprendizagem à execução. Em terceiro lugar, existe uma discrepância entre as pontuações de referência e a capacidade real, e essa questão está recebendo cada vez mais atenção. Em quarto lugar, a essência das aplicações de IA é substituir ou aprimorar o trabalho humano, e não criar aplicativos por criar. As diferentes abordagens também são interessantes. Karpathy se preocupa mais com a questão filosófica de "qual a forma da inteligência artificial?", enquanto Tang Jie se concentra mais no problema de engenharia de "como implementar o modelo em cenários do mundo real". Um se dedica mais à "compreensão", enquanto o outro se concentra mais na "implementação". Ambas as perspectivas são necessárias. Só com uma compreensão clara podemos saber se estamos no caminho certo; só com uma engenharia sólida podemos transformar ideias em realidade. 2026 será um ano maravilhoso.
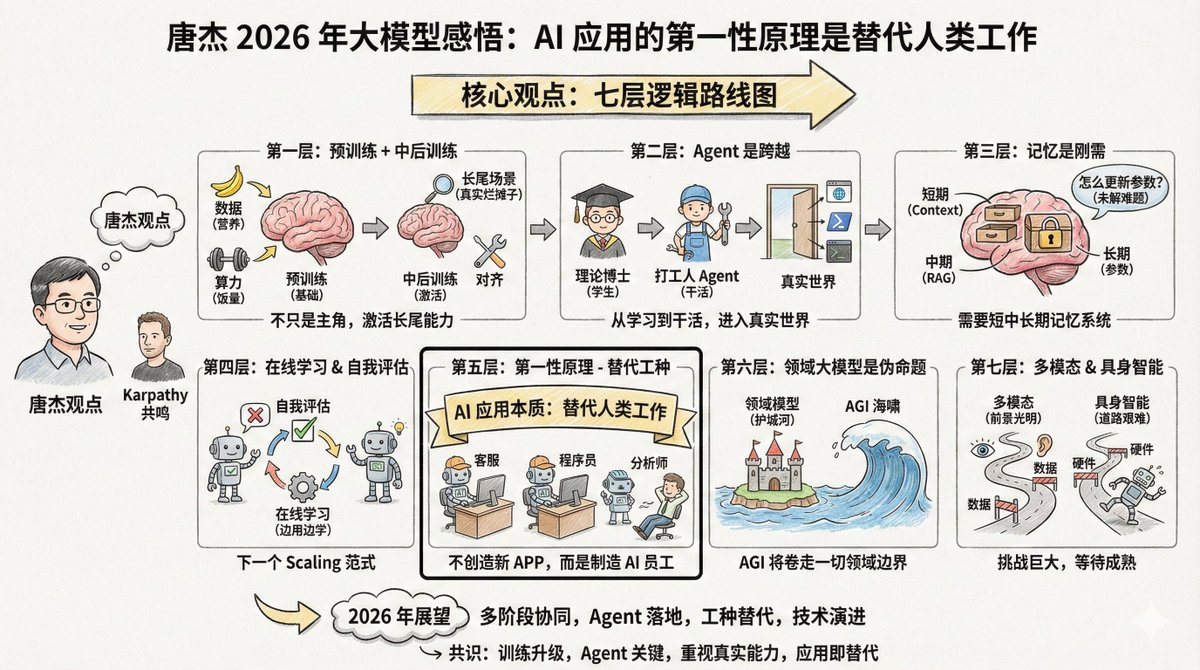
O conteúdo aweibo.com/2126427211/QjI…ang Jie: https://t.co/AOdkBXNIey Gostaria de compartilhar algumas ideias recentes, na esperança de que sejam úteis para todos. O pré-treinamento permite que modelos de grande porte adquiram conhecimento de senso comum sobre o mundo e possuam habilidades básicas de raciocínio. Mais dados, parâmetros maiores e computação mais robusta continuam sendo a maneira mais eficiente de escalar modelos de pedestal. Ativar o alinhamento e aprimorar as capacidades de inferência, especialmente ativando capacidades mais abrangentes para caudas longas, é fundamental para garantir o desempenho do modelo. Embora os benchmarks gerais avaliem o desempenho geral dos modelos, eles também podem levar ao sobreajuste em muitos casos. Em cenários do mundo real, como os modelos podem alinhar cenas reais com caudas longas de forma mais rápida e eficiente, aumentando a sensação de realismo? O treinamento durante e após o treinamento possibilita alinhamento rápido e capacidades de inferência robustas em mais cenários. As capacidades dos agentes representam um marco na expansão das capacidades dos modelos e são essenciais para permitir que modelos de IA entrem no mundo real (virtual/físico). Sem essas capacidades, grandes modelos permanecerão no estágio de aprendizado teórico, assim como uma pessoa que aprende continuamente, mesmo ao obter um doutorado, apenas acumulando conhecimento sem transformá-lo em produtividade. Anteriormente, os agentes eram implementados por meio da aplicação do modelo; agora, os modelos podem integrar diretamente os dados dos agentes ao processo de treinamento, aumentando sua versatilidade. No entanto, o desafio persiste: a generalização e a transferência entre diferentes ambientes de agentes não são fáceis. Portanto, a solução mais simples é aumentar continuamente os dados provenientes de diferentes ambientes de agentes e implementar o aprendizado por reforço adaptado a esses ambientes. A obtenção de memória do modelo é essencial, uma capacidade necessária para que qualquer modelo seja aplicado em ambientes do mundo real. A memória humana é dividida em quatro estágios: curto prazo (córtex pré-frontal), médio prazo (hipocampo), longo prazo (córtex cerebral distribuído) e histórico (wiki ou livros de história). A forma como grandes modelos conseguem obter memória em diferentes estágios é crucial. Contexto, período de tempo e parâmetros do modelo podem corresponder a diferentes estágios da memória humana, mas como alcançar isso é fundamental. Uma abordagem é a compressão de memória, que consiste simplesmente em armazenar o contexto. Se um modelo grande puder suportar contextos suficientemente longos, então alcançar a memória de curto, médio e longo prazo torna-se virtualmente possível. No entanto, iterar pelo conhecimento do modelo e modificar seus parâmetros continua sendo um desafio significativo. Aprendizado online e autoavaliação. Com a compreensão dos mecanismos de memória, o aprendizado online torna-se um foco essencial. Os modelos de grande escala atuais são periodicamente retreinados, o que apresenta diversos problemas: o modelo não consegue iterar verdadeiramente por si só, embora o autoaprendizado e a auto-iteração sejam inevitavelmente capacidades necessárias na próxima etapa; o retreinamento também é dispendioso e resulta na perda de muitos dados interativos. Portanto, como alcançar o aprendizado online é crucial, e a autoavaliação é um aspecto fundamental desse aprendizado. Para que um modelo aprenda por si só, ele precisa primeiro saber se está correto ou incorreto. Se souber (mesmo que apenas probabilisticamente), conhecerá o objetivo de otimização e poderá se aprimorar. Portanto, construir um mecanismo de autoavaliação de modelos é um desafio. Este pode ser também o próximo paradigma de escalabilidade. Aprendizado contínuo/aprendizado em tempo real/aprendizado online? Finalmente, à medida que o desenvolvimento de modelos em larga escala se torna cada vez mais integrado, é inevitável combinar o desenvolvimento e a aplicação de modelos. O objetivo principal da aplicação de modelos de IA não deve ser a criação de novos aplicativos; sua essência é a IA substituir o trabalho humano. Portanto, desenvolver IA que substitua diferentes funções é fundamental para sua aplicação. O chat substitui parcialmente a busca e, de certa forma, incorpora a interação emocional. O próximo ano será um ano decisivo para a IA substituir diferentes funções. Em conclusão, vamos discutir multimodalidade e corporeidade. A multimodalidade é, sem dúvida, um futuro promissor, mas o problema atual é que ela não contribui significativamente para o limite superior da inteligência artificial geral (IAG), e o limite superior exato da IAG geral permanece desconhecido. Talvez a abordagem mais eficaz seja desenvolvê-las separadamente: texto, multimodalidade e geração multimodal. É claro que explorar a combinação dessas três de forma moderada pode revelar capacidades muito diferentes, mas isso requer coragem e apoio financeiro substancial. Da mesma forma, se você entende de agentes, saberá onde residem os principais problemas da inteligência incorporada: é muito difícil generalizar (embora isso não seja necessariamente verdade), mas ativar capacidades incorporadas gerais com uma pequena amostra é praticamente impossível. Então, o que fazer? Coletar ou sintetizar dados não é fácil nem barato. Por outro lado, à medida que a escala de dados aumenta, as capacidades gerais surgirão naturalmente e criarão uma barreira de entrada. Claro, esse é apenas um desafio relacionado à inteligência. Para a inteligência incorporada, os próprios robôs também representam um problema; a instabilidade e as frequentes falhas limitam o desenvolvimento da inteligência incorporada. Espera-se um progresso significativo nessas áreas até 2026. Vamos também discutir o modelo mestre de domínio e suas aplicações. Sempre acreditei que o modelo mestre de domínio é uma proposição falsa; com a IA já implementada, que IA específica de domínio existe...? No entanto, como a IA ainda não foi totalmente desenvolvida, os modelos de domínio existirão por muito tempo (quanto tempo é difícil dizer, dado o ritmo acelerado do desenvolvimento da IA). A existência de modelos de domínio reflete essencialmente a relutância das empresas de aplicativos em admitir a derrota para as empresas de IA. Elas esperam construir uma barreira de conhecimento de domínio, resistir à intrusão da IA e domesticar a IA como ferramenta. Mas a IA é inerentemente como um tsunami; ela varre tudo em seu caminho. Algumas empresas de domínio inevitavelmente romperão suas barreiras e serão arrastadas para o mundo da IA. Em resumo, dados de domínio, processos e dados de agentes entrarão gradualmente no modelo mestre. A aplicação de modelos em larga escala também deve retornar aos princípios fundamentais: a IA não precisa criar novas aplicações. A essência da IA é simular, substituir ou auxiliar humanos na execução de certas tarefas humanas essenciais (certos trabalhos). Isso provavelmente leva a dois tipos de aplicação: um é habilitar softwares existentes com IA, modificando o que originalmente exigia intervenção humana; o outro é criar softwares de IA alinhados a um trabalho humano específico, substituindo o trabalho humano. Portanto, a aplicação de modelos em larga escala precisa ajudar as pessoas e criar novo valor. Se um software de IA for criado, mas ninguém o usar e ele não gerar valor, então esse software de IA certamente não terá vitalidade.