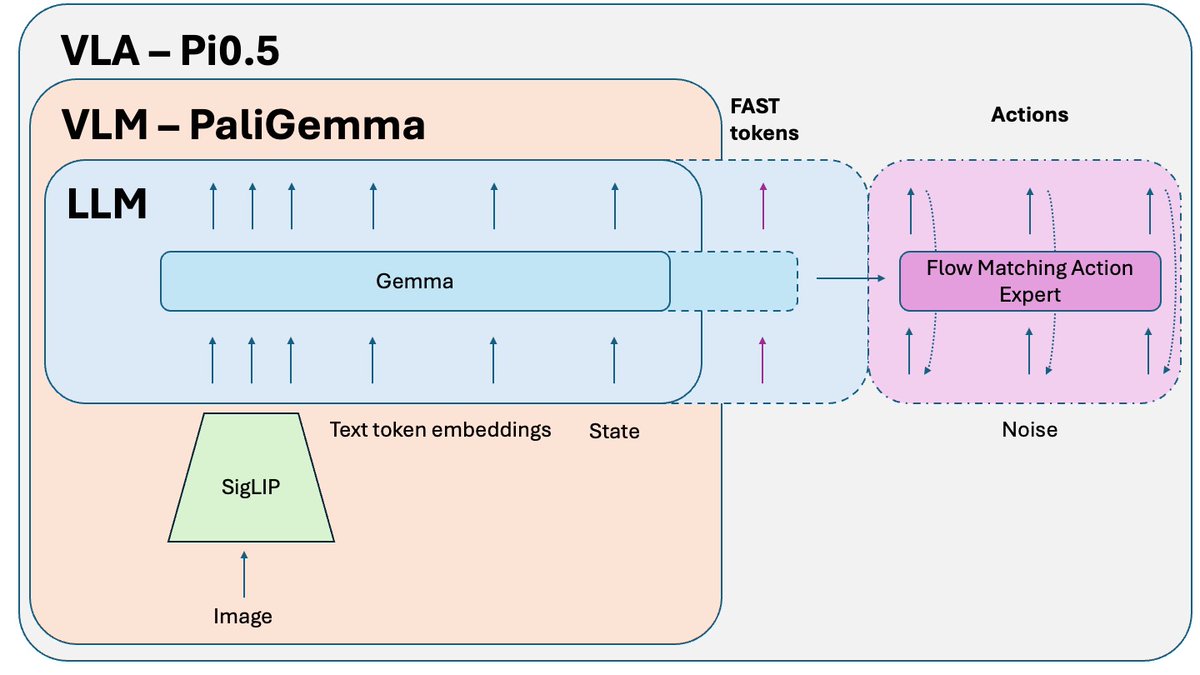
O Pi0.5 da @physical_int é uma das melhores soluções de robótica de código aberto do momento 🤖 É uma versão atualizada do Pi0. E os avanços mais recentes do Raspberry Pi são construídos sobre ela. Vamos discutir como funciona:
O que mudou em relação ao Pi0? - Tokenização FAST - havia uma versão FAST opcional no Pi0, mas para o Pi0.5, ela é uma parte essencial do treinamento. - Sistema 2 - seguindo o artigo Hi Robot, o Pi 0.5 utiliza sua parte VLM como um sistema de raciocínio de alto nível (Sistema 2) para raciocinar e planejar tarefas complexas. - Melhoria na receita de treino e alguns pequenos ajustes.
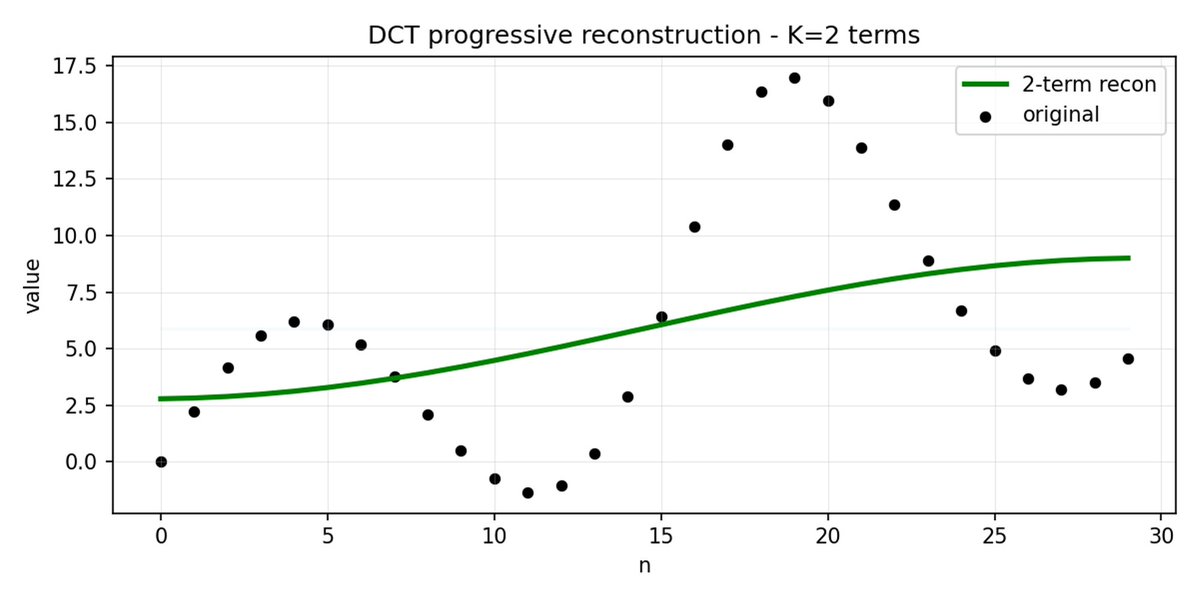
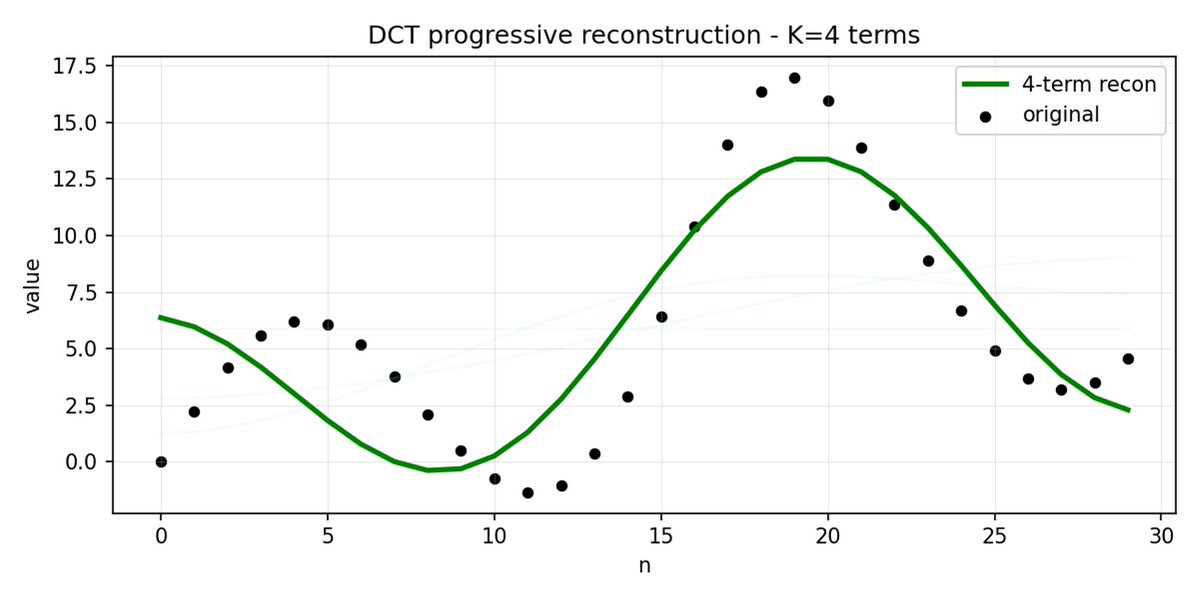
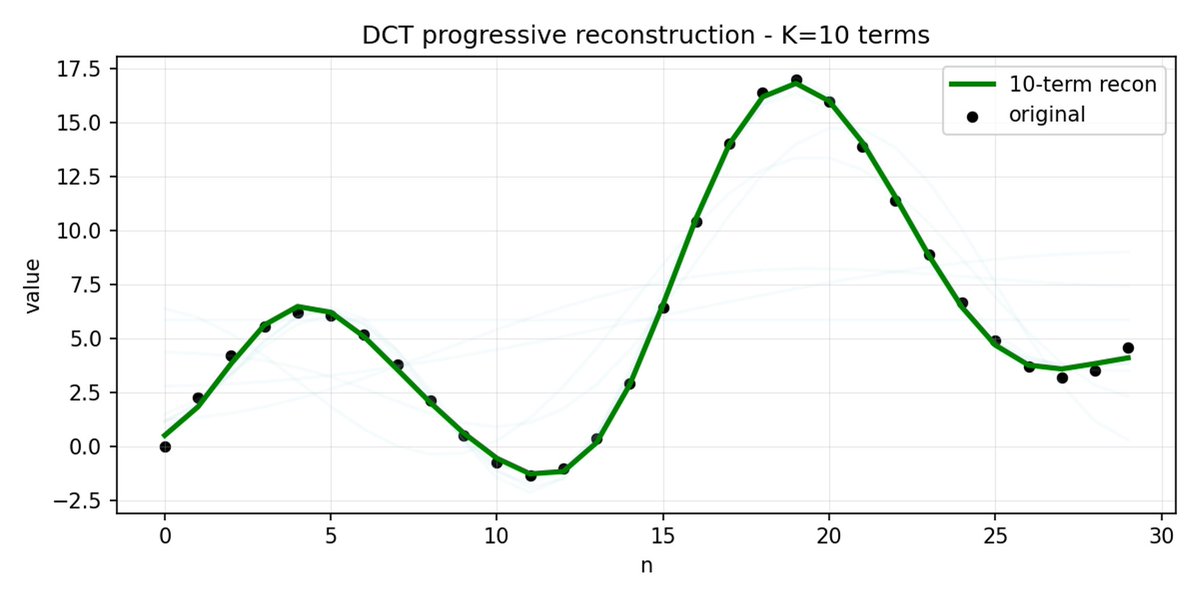
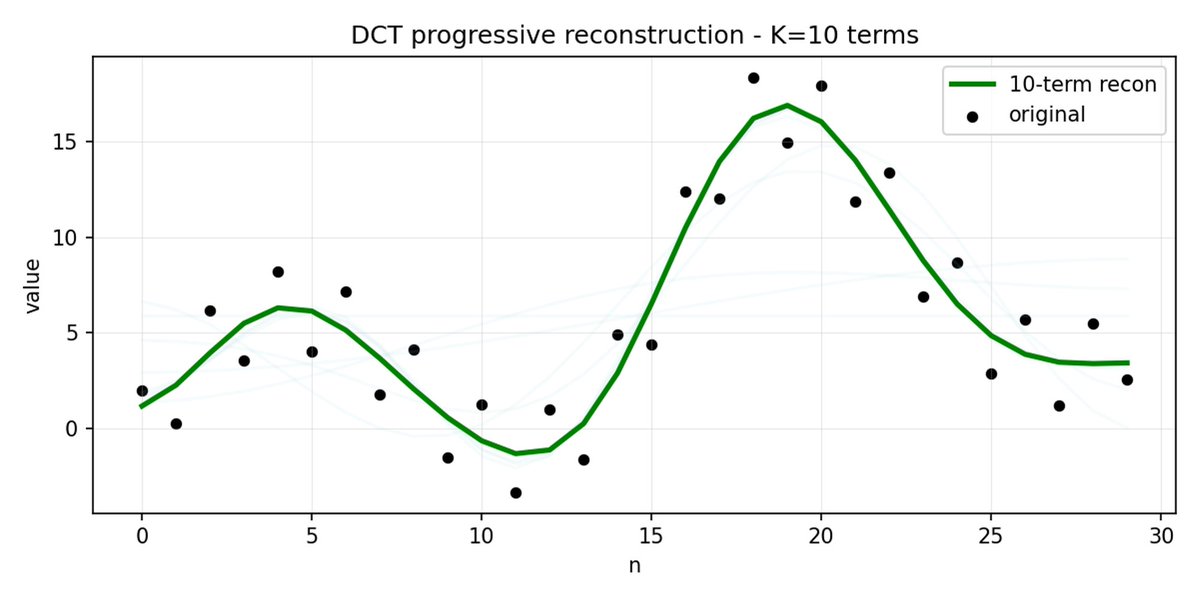
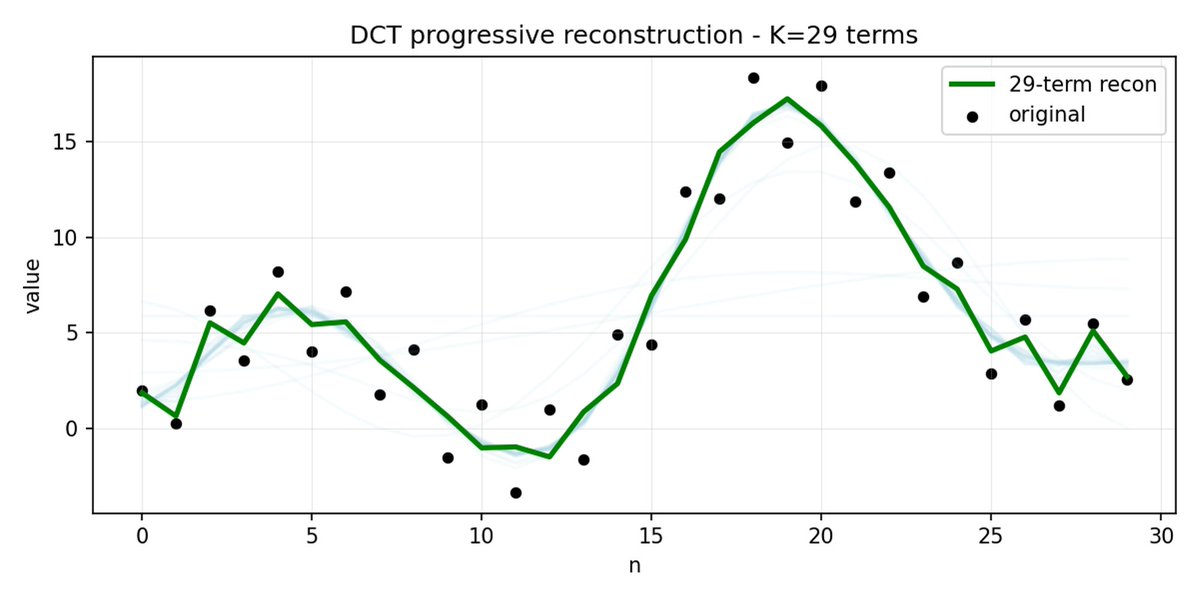
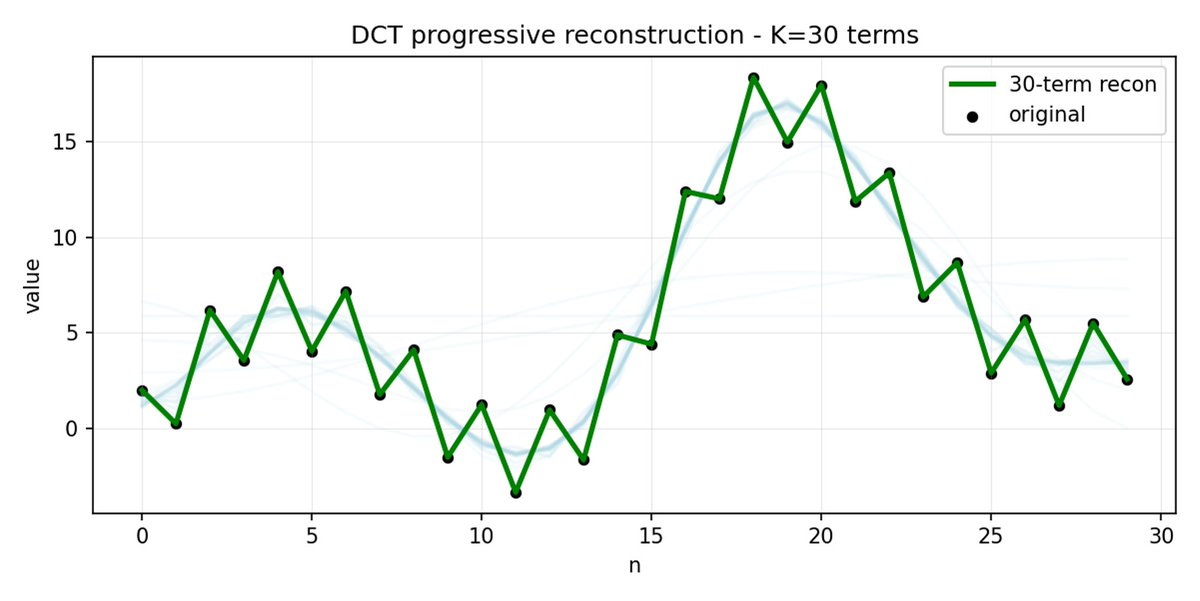
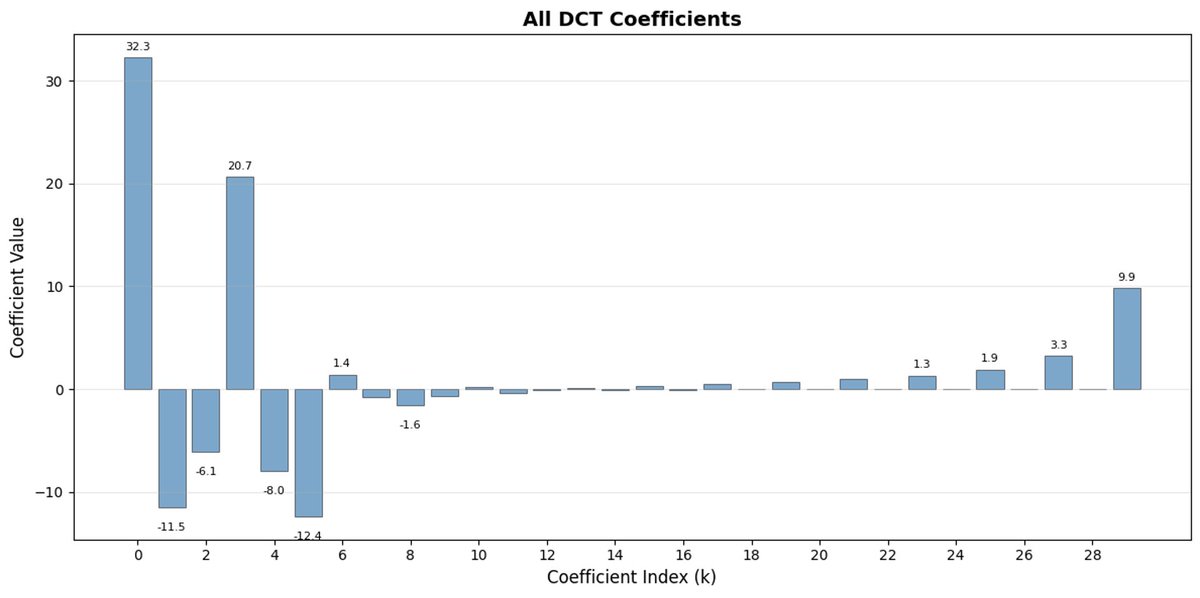
FAST é uma abordagem de tokenização que permite comprimir sequências de ações em tokens discretos com alta densidade de informação, utilizando DCT (Transformada Discreta de Cosseno) e BPE (Codificação de Pares de Bytes). A DCT é o mesmo algoritmo usado para compressão de imagens em JPEG. Representa o sinal como uma soma de funções cosseno com diferentes frequências. Os primeiros componentes capturam a tendência geral e a forma do sinal, enquanto os componentes restantes capturam detalhes cada vez mais precisos. O JPEG progressivo envia primeiro os componentes de baixa frequência, e a imagem fica desfocada inicialmente, tornando-se mais nítida à medida que mais componentes são adicionados.



O FAST faz o mesmo para blocos de ação. Em vez de prever 30 valores de ação correlacionados, você prevê uma representação mais curta e significativa. Muitas vezes, você pode manter apenas alguns coeficientes principais (que contêm a maior parte da energia do sinal original) e ainda assim reconstruir a trajetória muito bem.
A codificação de pares de bytes (BPE, do inglês Byte Pair Encoding) é a abordagem de tokenização mais popular usada em LLMs (Learning Learning Machines). Ele busca os pares de tokens mais comuns e os mescla em tokens únicos. Quando aplicado sobre a DCT quantizada, muitos coeficientes 0 de componentes de alta frequência, bem como movimentos combinados comuns de diferentes articulações, são fundidos em tokens únicos, o que leva a uma forte compressão.
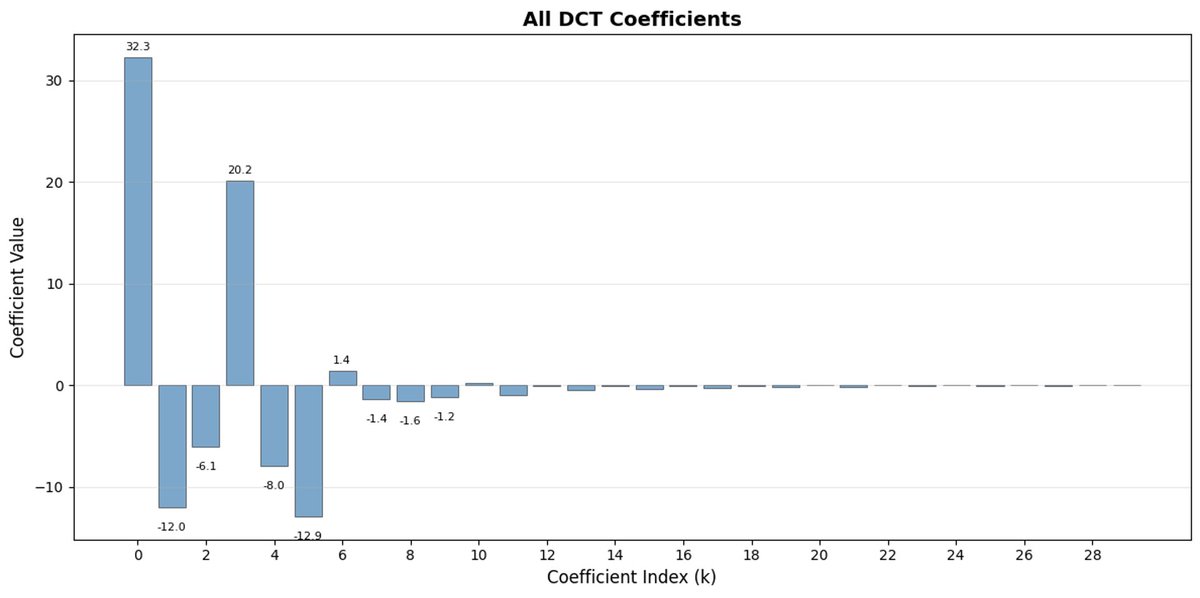
O FAST pode apresentar baixa compressão se suas ações tiverem ruído de alta frequência (como artefatos de normalização por passo de tempo), os coeficientes deixarem de ser próximos de zero e a compressão se degradar. Os dados reais de robôs geralmente são suaves, então na maioria dos casos você não terá problemas - apenas tome cuidado com o pré-processamento dos dados.
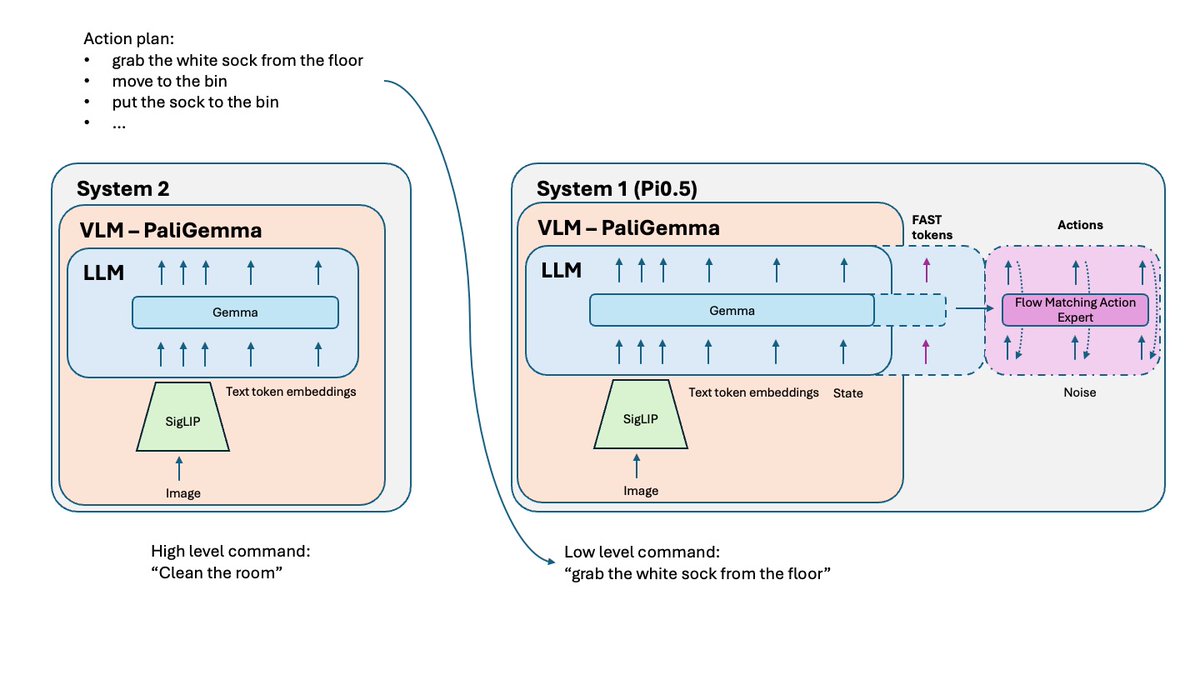
A política de VLA (Visual Life Assessment) treinada em tarefas simples pode ter dificuldades em combiná-las em problemas complexos e de longo prazo. Para resolver o problema, utiliza-se o Sistema 2 de nível superior. O Pi0.5 usa o mesmo VLM que o Sistema 1 (VLA), mas é chamado com uma frequência muito menor para analisar o problema e definir o próximo passo. Este passo é posteriormente enviado ao Sistema 1 para execução.
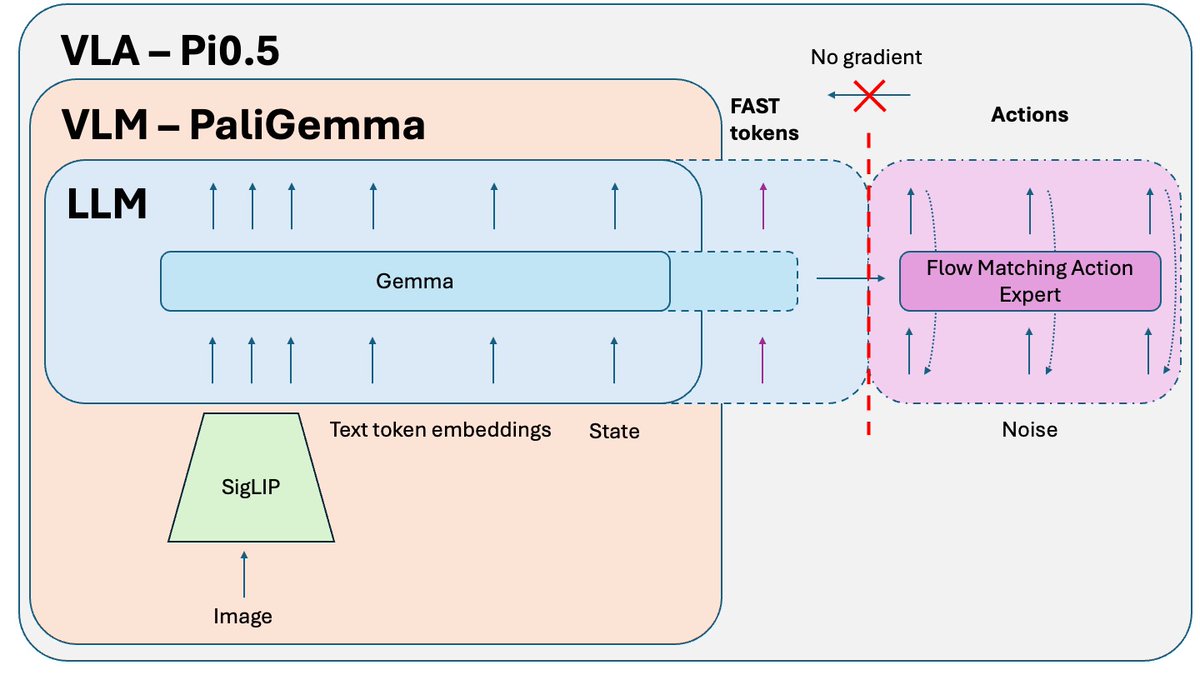
Um truque adicional, publicado após o artigo sobre o Pi0.5, mas usado para treinar a versão de código aberto do modelo, é o Isolamento de Conhecimento. Ao treinar conjuntamente a parte VLM (pré-treinada em dados de escala da internet) e o especialista em ações (inicializado aleatoriamente), o gradiente ruidoso do especialista em ações corrompe o pré-treinamento do VLM. Ele simplesmente começa a esquecer seu conhecimento pré-treinado. A solução é isolar o gradiente do especialista em ações e permitir que ele impacte apenas os pesos do especialista em ações, enquanto o VLM é treinado em tokens de ação FAST + dados relevantes que não são de ação.
Outro problema durante a inferência é o movimento não suave devido ao agrupamento. O modelo prevê o próximo bloco de código, executa-o e, em seguida, pausa para prever o próximo (vídeo abaixo, em velocidade 3x). Se você tentar prever um bloco de código antes que o anterior seja executado, isso pode levar a erros fatais se o modelo pular para um novo modo de ação enquanto executa um modo muito diferente. A solução é o inpainting, uma técnica frequentemente usada na geração de imagens. Podemos prever o próximo bloco de código enquanto o anterior está sendo executado, mas forçamos essa nova previsão a corresponder exatamente ao final do bloco anterior. O resultado é um movimento muito mais suave, sem saltos nem pausas, além de maior desempenho e capacidade de processamento do modelo.
Se você quiser uma análise completa e detalhada (com recursos visuais, demonstração e instruções de ajustyoutu.be/QgGhK1LaUe8 novo vídeo: https://t.co/TDdhedJiDn