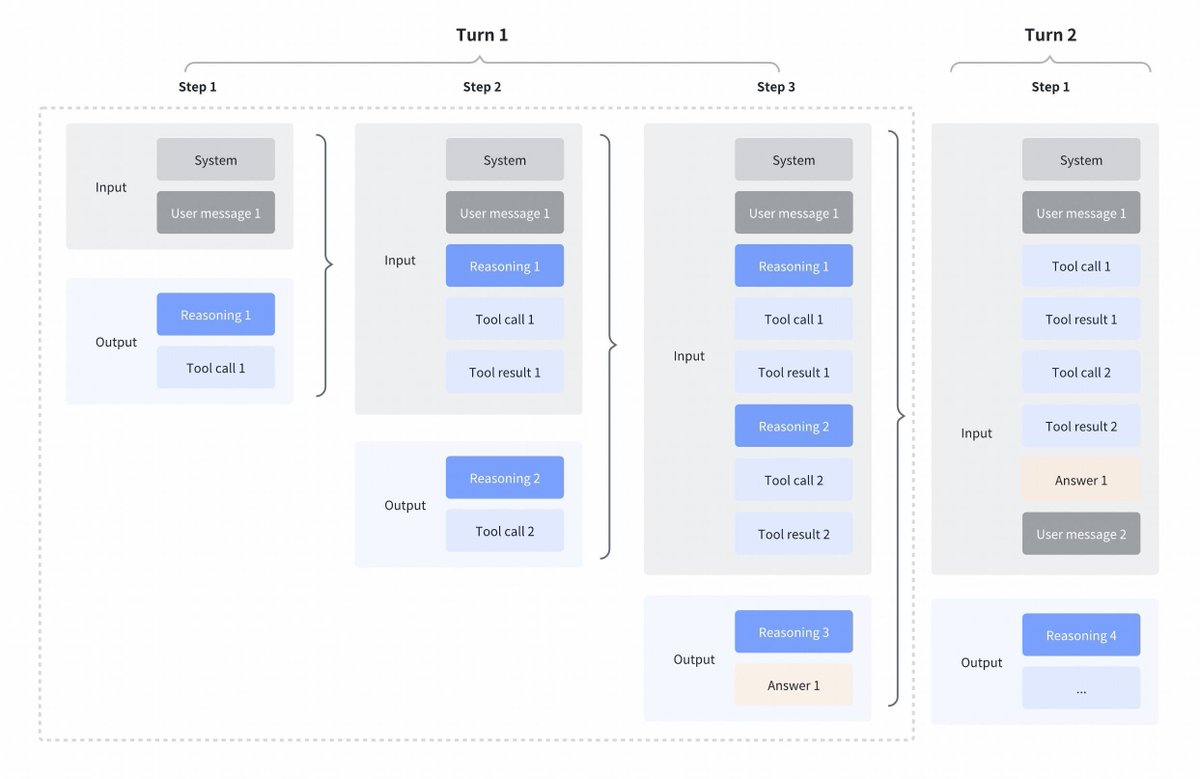
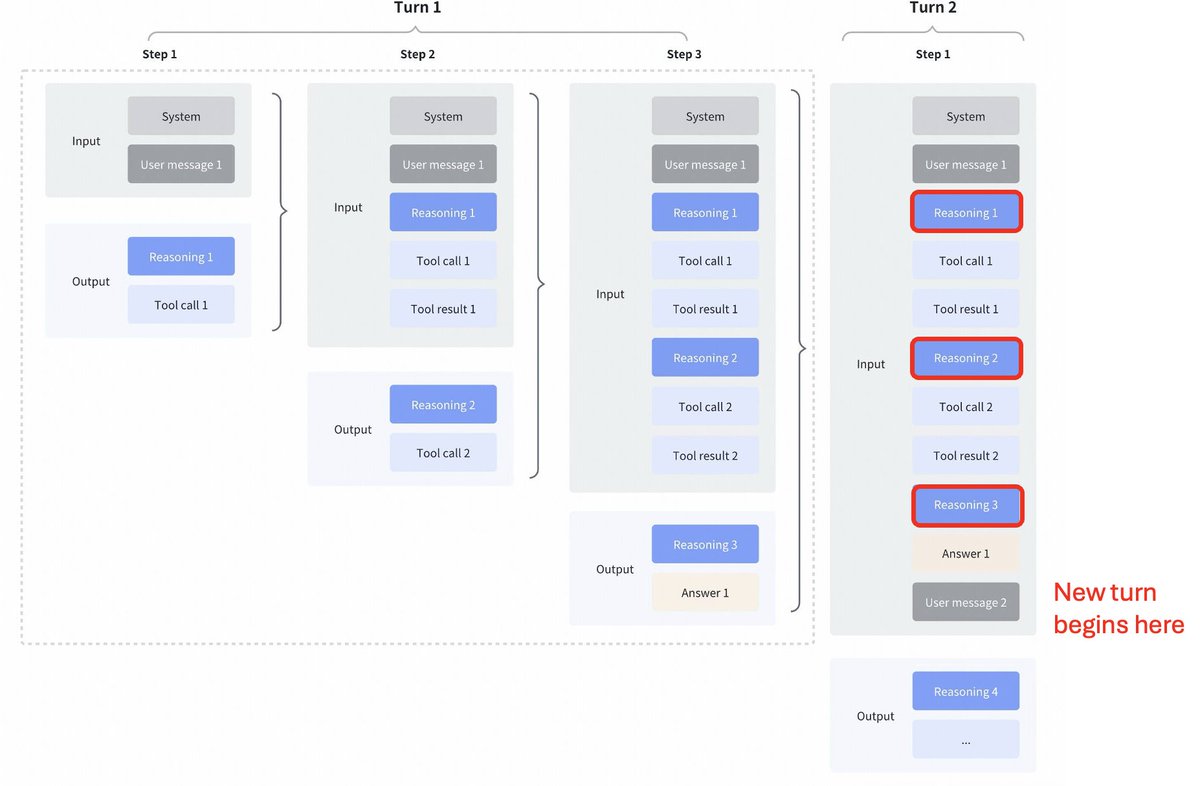
Mudança interessante de estratégia por parte do GLM4.7 comparado com Kimi K2 Thinking, DeepSeek V3.2 e MiniMax M2.1 Pensamento intercalado entre chamadas de ferramentas: Todos esses modelos suportavam o pensamento intercalado para chamadas de ferramentas, mas eles eliminavam o pensamento das etapas anteriores, como pode ser visto na primeira captura de tela abaixo. Pensamento preservado no GLM 4.7: Em comparação, o GLM 4.7 (apenas para codificação de endpoints) preserva o raciocínio das etapas anteriores, como pode ser visto na captura de tela abaixo (observe os blocos vermelhos). Para o outro endpoint da API, o comportamento é o mesmo de antes (descartar o raciocínio das etapas anteriores). Isso certamente melhorará o desempenho, já que o modelo terá contexto histórico. Como @peakji aconselha, os modelos precisam do seu processo de pensamento anterior para tomar boas decisões posteriormente. Isso é contrário à compressão de contexto, mas acredito que, para cenários de programação, pode valer a pena. Gostaria que fosse configurável, para que pudéssemos ver o impacto por nós mesmos.