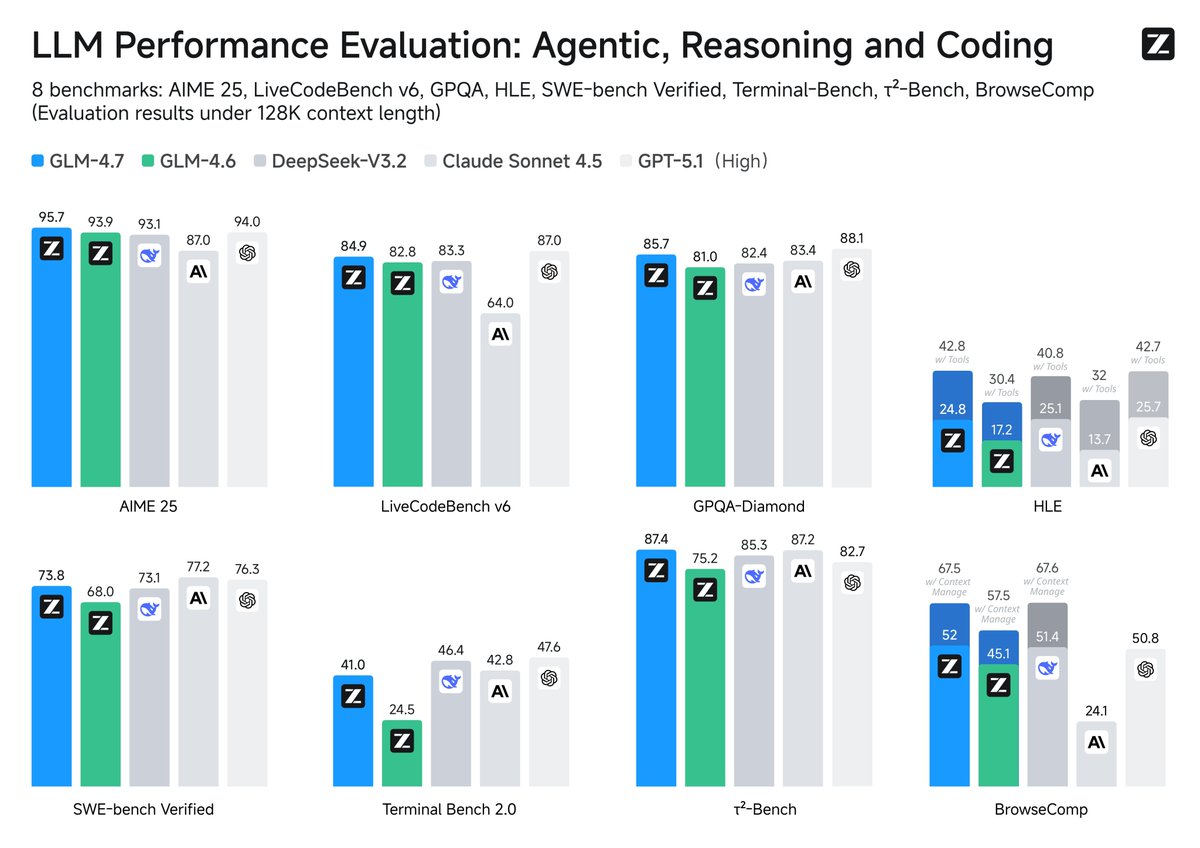
A Zhipu acaba de disponibilizar em código aberto seu modelo mais recente: o GLM-4.7, cujas capacidades de ferramental superam as do Claude Sonnet 4.5. Obteve uma pontuação de 67,5 na avaliação de tarefas web BrowseComp e 87,4 na avaliação de chamadas de ferramentas interativas τ²-Bench, superando o Claude Sonnet em 4,5 pontos. Obteve 42,8% em HLE, uma melhoria de 41% em relação ao GLM-4.6 e superando o GPT-5.1. Super GPT-5.2 na Code Arena As capacidades do GLM-4.7 se manifestam em três níveis: programação, raciocínio e agentes inteligentes. Em termos de habilidades de programação, incluindo front-end/back-end e cumprimento de instruções, o desempenho melhorou significativamente em comparação com 4,6 em um teste cego de 100 tarefas em um projeto real. Isso também melhora o desempenho na programação multilíngue e em agentes inteligentes de ponta, permitindo "pensar antes de agir" em estruturas de programação como o Claude Code. O planejamento de tarefas a longo prazo e a utilização de ferramentas estáveis permitem um raciocínio implícito e armazenável em cache. Requisitos complexos são automaticamente divididos em etapas, e buscas, terminais, sistemas de arquivos e navegadores são acionados. Erros são revertidos. Atinge 87,4 no τ²-Bench, o que significa que cadeias de ferramentas com múltiplas etapas raramente travam. O módulo Skills foi lançado no modo de desenvolvimento full-stack do z ai para dar suporte ao agendamento unificado de tarefas multimodais. #ZhipuGLM47
GitHub:github.com/zai-org/GLM-4.5V Abraço em fhuggingface.co/zai-org/GLM-4.7t.co/dmodelscope.cn/models/ZhipuAI…oda: https://t.co/ELPQoNUXbc