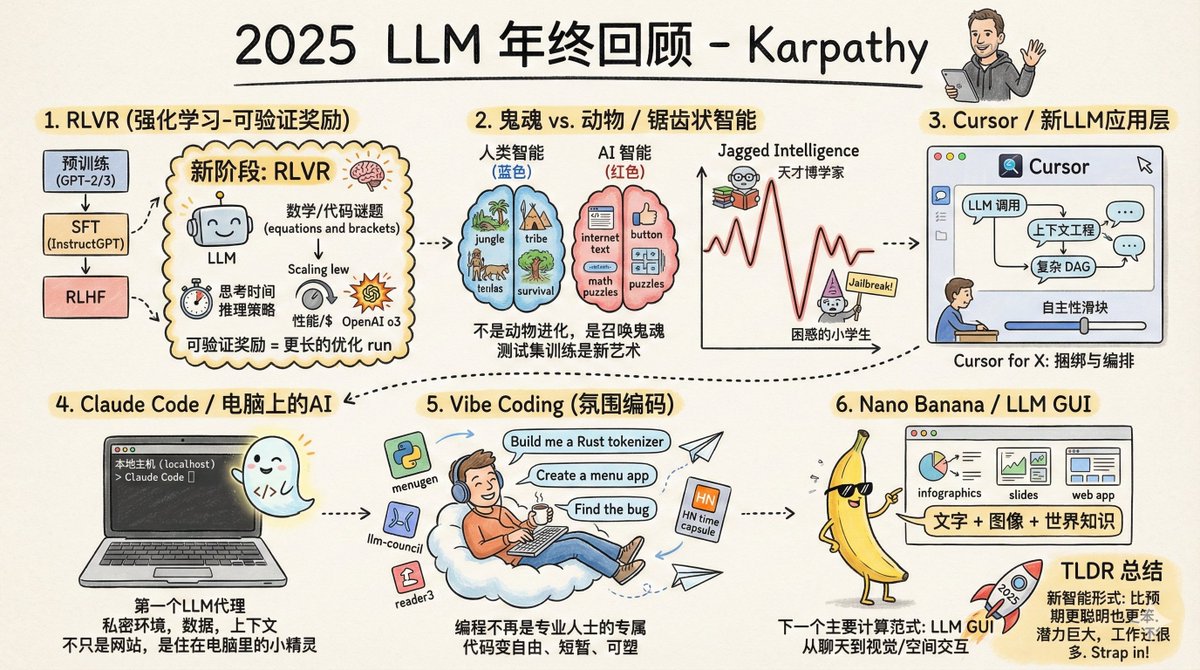
Andrej Karpathy, cofundador da OpenAI, ex-diretor de IA da Tesla e um dos pesquisadores de IA mais influentes do mundo, acaba de divulgar uma revisão de final de ano do programa LLM de 2025. A primeira grande mudança: uma mudança de paradigma nos métodos de treinamento. Antes de 2025, o treinamento de um modelo grande e utilizável envolvia basicamente três etapas: pré-treinamento, ajuste fino supervisionado e aprendizado por reforço com feedback humano. Essa fórmula tem sido usada desde 2020 e permanece estável e confiável. Em 2025, foi adicionado um quarto passo crucial: RLVR, que significa Aprendizado por Reforço a partir de Recompensas Verificáveis. O que isso significa? Simplificando, significa deixar o modelo praticar repetidamente em um ambiente com "respostas padrão". Por exemplo, em problemas de matemática, a resposta é certa ou errada; não há necessidade de correção humana. O mesmo se aplica ao código; se ele funciona, funciona. Qual é a diferença fundamental entre este treinamento e os anteriores? O ajuste fino supervisionado e o feedback humano anteriores consistiam essencialmente em "copiar o modelo", onde o modelo aprendia com base nas amostras fornecidas pelo humano. Mas o RLVR é diferente; ele permite que o modelo descubra suas próprias estratégias de resolução de problemas. É como aprender a nadar: antes, você assistia a vídeos instrutivos e imitava os movimentos; agora, você simplesmente é jogado na água — contanto que consiga nadar até a outra margem, a forma como você rema não importa. O resultado? O modelo "descobriu" algo que parecia raciocínio por conta própria. Aprendeu a decompor grandes problemas em etapas menores e a voltar atrás e recomeçar quando se desviava do caminho. Essas estratégias não podem ser demonstradas por humanos, porque nem mesmo os humanos conseguem explicar claramente como é o "processo de pensamento correto". Essa mudança desencadeou uma reação em cadeia: a forma como o poder computacional é alocado mudou. Antes, a maior parte do poder computacional era gasta na fase de pré-treinamento, mas agora cada vez mais poder computacional é usado na fase de aprendizado por reforço (RL). O número de parâmetros do modelo não aumentou muito, mas sua capacidade de inferência disparou. O OpenAI o1 foi o ponto de partida dessa trajetória, e o OpenAI o3 foi o ponto de inflexão que realmente fez as pessoas "sentirem a diferença". Existe uma nova abordagem: ela também pode utilizar mais poder computacional durante a inferência. Fazer o modelo "pensar por mais tempo" gera cadeias de inferência mais longas, resultando em melhor desempenho. Isso equivale a adicionar um parâmetro de ajuste para controlar suas capacidades. A segunda grande mudança: finalmente entendemos qual é a "forma" da inteligência da IA. Karpathy usou uma analogia brilhante: não estamos "criando animais", estamos "invocando fantasmas". A inteligência humana evolui, e seu objetivo de otimização é "ajudar a tribo a sobreviver na selva". A inteligência de grandes modelos é treinada, e seu objetivo de otimização é "imitar textos humanos, marcar pontos em problemas de matemática e acumular pontuações em listas de referência". Os objetivos de otimização são completamente diferentes, portanto os resultados também serão naturalmente completamente diferentes. Portanto, a inteligência da IA é uma "inteligência irregular". Ela pode se comportar como um erudito onisciente em algumas áreas, enquanto comete erros que nem mesmo um aluno do ensino fundamental cometeria em outras. Num segundo, ela está ajudando você a deduzir fórmulas complexas e, no segundo seguinte, está sendo enganada para fornecer dados por uma simples dica de jailbreak. Por que isso acontece? Porque em áreas com "recompensas verificáveis", os modelos desenvolvem "picos" nessas áreas. A matemática tem respostas padronizadas e o código pode ser testado, então o progresso nessas áreas é rápido. Mas em áreas como senso comum, interação social e criatividade, o que é "certo" é difícil de definir, tornando mais difícil para os modelos aprenderem de forma eficiente. Isso também fez com que Karpathy perdesse a fé nos benchmarks. O motivo é simples: as próprias questões do teste são "ambientes verificáveis", e o modelo pode ser otimizado para esses ambientes. Dominar os benchmarks tornou-se uma arte. É perfeitamente possível atingir a pontuação máxima em todos os benchmarks, mas ainda assim ficar muito aquém da verdadeira inteligência geral. A terceira grande mudança: surge a camada de aplicação LLM. O Cursor se tornou incrivelmente popular este ano, mas Karpathy acredita que sua maior importância reside não no produto em si, mas em comprovar a existência de uma nova espécie: os "aplicativos LLM". O surgimento de discussões sobre "cursores no domínio X" indica a formação de um novo paradigma de software. O que essas aplicações farão? Primeiro, realize a engenharia de contexto. Organize as informações relevantes e insira-as no modelo. Em segundo lugar, orquestre várias chamadas de modelo. O backend pode estar lidando com diversas chamadas de API; equilibre desempenho e custo. Em terceiro lugar, forneça interfaces para cenários especializados, permitindo que os humanos intervenham em pontos-chave. Em quarto lugar, ofereça aos usuários um "controle deslizante de grau de autonomia". Você pode configurá-lo para fazer mais ou menos. Uma questão vem sendo debatida há um ano inteiro: qual a "espessura" dessa camada de aplicação? Os fornecedores de modelos vão monopolizar todas as aplicações? A avaliação de Karpathy é que os fabricantes de modelos treinam "graduados universitários com habilidades gerais", mas os programas de mestrado em Direito (LLM) são responsáveis por organizar, treinar e inserir esses graduados no mercado de trabalho, transformando-os em equipes profissionais capazes de atuar em setores específicos. Dados, sensores, atuadores, circuitos de feedback — tudo isso são tarefas da camada de aplicação. A quarta grande mudança: a IA chegou ao seu computador. Claude Code é um dos produtos que mais impressionou Karpathy este ano. Ele demonstra como um "agente de IA" deveria ser: capaz de acionar ferramentas, realizar inferências, executar loops e resolver problemas complexos. Mas, mais importante ainda, ele roda no seu computador. Ele usa seu ambiente, seus dados e seu contexto. Karpathy acredita que a OpenAI avaliou mal a situação. Eles focaram o Codex e os agentes em contêineres na nuvem, agendando-os a partir do ChatGPT. Parece que estão mirando no "objetivo final da Inteligência Artificial Geral", mas ainda não chegamos lá. A realidade é que as capacidades da IA variam muito, e os humanos ainda precisam supervisioná-las e auxiliá-las. Colocar agentes inteligentes localmente, trabalhando em conjunto com os desenvolvedores, é a abordagem mais sensata no momento. Claude Code consegue isso com uma interface de linha de comando minimalista. A IA não é mais apenas um site que você visita, mas um pequeno sprite "vivendo" no seu computador. Este é um paradigma completamente novo de interação humano-computador. A quinta grande mudança: a Codificação Vibe decolou. Em 2025, as capacidades da IA ultrapassaram um limite: você poderia descrever suas necessidades puramente em inglês e ter o programa escrito para você, sem se preocupar com a aparência do código. Karpathy comentou casualmente sobre esse estilo de programação no Twitter, chamando-o de "programação vibe", e o termo viralizou. O que isso significa? Programar não é mais domínio exclusivo de programadores profissionais; pessoas comuns também podem programar. Isso é diferente de qualquer modelo anterior de difusão tecnológica. No passado, as novas tecnologias eram sempre dominadas primeiro por grandes empresas, governos e profissionais, antes de se disseminarem gradualmente para outros setores. Mas o modelo se inverteu, com pessoas comuns se beneficiando muito mais do que os profissionais. Não se trata apenas de "capacitar não-programadores a programar". Para aqueles que sabem programar, muitos pequenos programas que antes "não valiam a pena escrever" agora valem a pena. O próprio Karpathy realizou muitos projetos com o Vibe Coding: ele escreveu um analisador léxico personalizado em Rust, criou diversos aplicativos utilitários e até escreveu um programa único apenas para encontrar um bug. De repente, o código se torna barato, descartável e pode ser escrito tão facilmente quanto em um pedaço de papel. Isso mudará completamente a forma do software e o trabalho dos programadores. A sexta grande mudança: a "era da interface gráfica" para modelos de grande escala está chegando. O Gemini Nano Banana do Google é um dos produtos mais subestimados deste ano. Ele consegue gerar imagens, infográficos e animações em tempo real com base no conteúdo da conversa, "desenhando" em vez de "escrever" as respostas. Karpathy situa isso num contexto histórico mais amplo: os grandes modelos representam o próximo grande paradigma da computação, tal como os computadores nas décadas de 1970 e 80. Portanto, veremos um caminho evolutivo semelhante. "Conversar" com modelos grandes hoje em dia é um pouco como digitar comandos em um terminal na década de 1980. O texto é um formato preferido pelas máquinas, mas não pelos humanos. Os humanos, na verdade, não gostam de ler textos; é lento e cansativo. As pessoas preferem ver imagens, vídeos e representações visuais. É por isso que os computadores tradicionais inventaram as interfaces gráficas. Modelos grandes também precisam de sua própria "interface gráfica do usuário" (GUI). Ela deve se comunicar conosco de maneiras que nos agradem: imagens, slides, quadros brancos, animações, miniaplicativos. Os emojis e o Markdown atuais são apenas formas rudimentares, meramente "enfeitando" o texto. Como será uma verdadeira GUI para LLM? O Nano Banana é um indício inicial. O mais interessante é que não se trata apenas de geração de imagens. Requer a interligação da geração de texto, da geração de imagens e do conhecimento do mundo, integrando tudo isso aos pesos do modelo. A conclusão de Karpathy é a seguinte: o grande modelo de 2025 é, ao mesmo tempo, mais inteligente e mais estúpido do que ele esperava. Ambas as afirmações são verdadeiras simultaneamente. Mas uma coisa é certa: mesmo com as nossas capacidades atuais, ainda não exploramos nem 10% do nosso potencial. Há ainda muitas ideias para experimentar; todo o campo parece estar em aberto. Ele disse algo aparentemente contraditório no podcast de Dwarkesh: Ele acredita que o progresso continuará em ritmo acelerado. Ao mesmo tempo, acredito que ainda há muito trabalho a ser feito. Essas duas coisas não são contraditórias. Apertem os cintos e continuem acelerando em 2026.