A versão 3.2 é o melhor modelo aberto no SWE-Rebench, mas por uma pequena margem, e não é a mais econômica... Até você perceber que eles não usaram cache para isso. Os custos da codificação agentiva são completamente dominados pelo pré-preenchimento. Com ≈90% de acertos no cache, o custo do Whale cairia para ≈US$ 0,1 por problema.
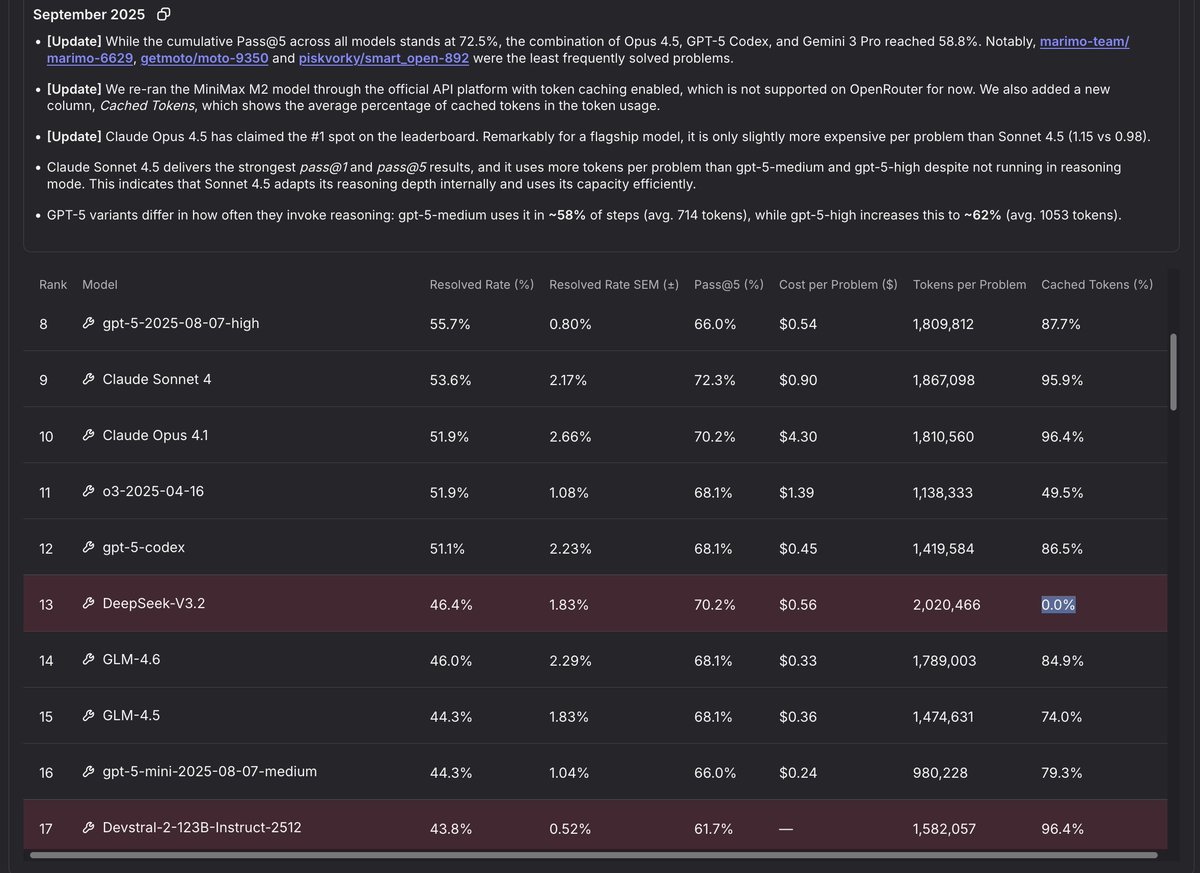
É claro que o DeepSeek possui cache próprio. Com a taxa de transferência de 5 iterações (pass@5) de 70,2, ele ainda está no nível do Opus 4.5 a uma fração ínfima do custo, perdendo apenas para o GPT 5.2 e sistemas de ferramentas bem projetados. Isso deve dar uma ideia do potencial máximo da próxima geração em termos de taxa de transferência de 1 iteração (pass@1).
