O modelo de Bolmo adota uma abordagem inteligente: em vez de treinar do zero, ele "codifica em bytes" o modelo existente. Possui um codificador/decodificador local integrado que comprime sequências de bytes em "tokens potenciais" antes de alimentá-las em um Transformer tradicional para processamento. Isso permite a conversão com sobrecarga mínima.

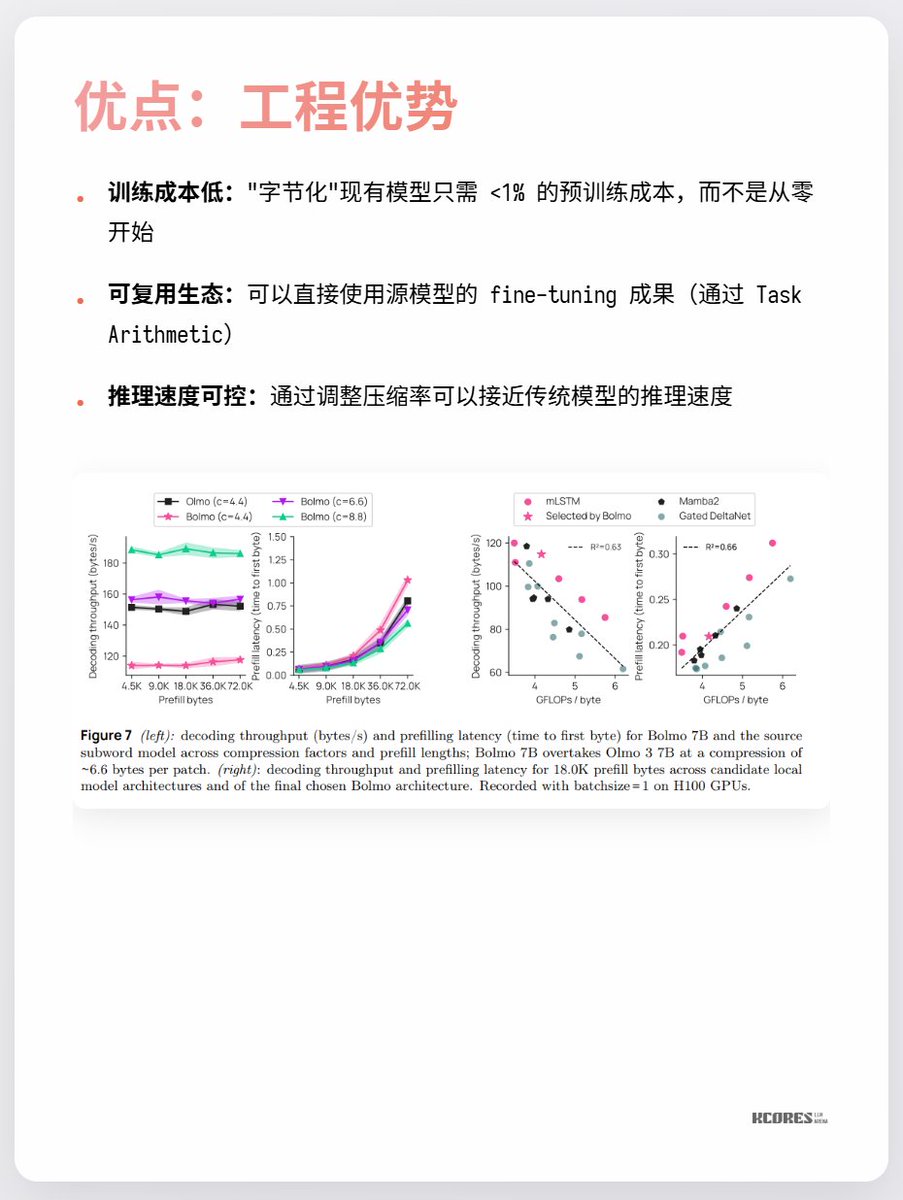

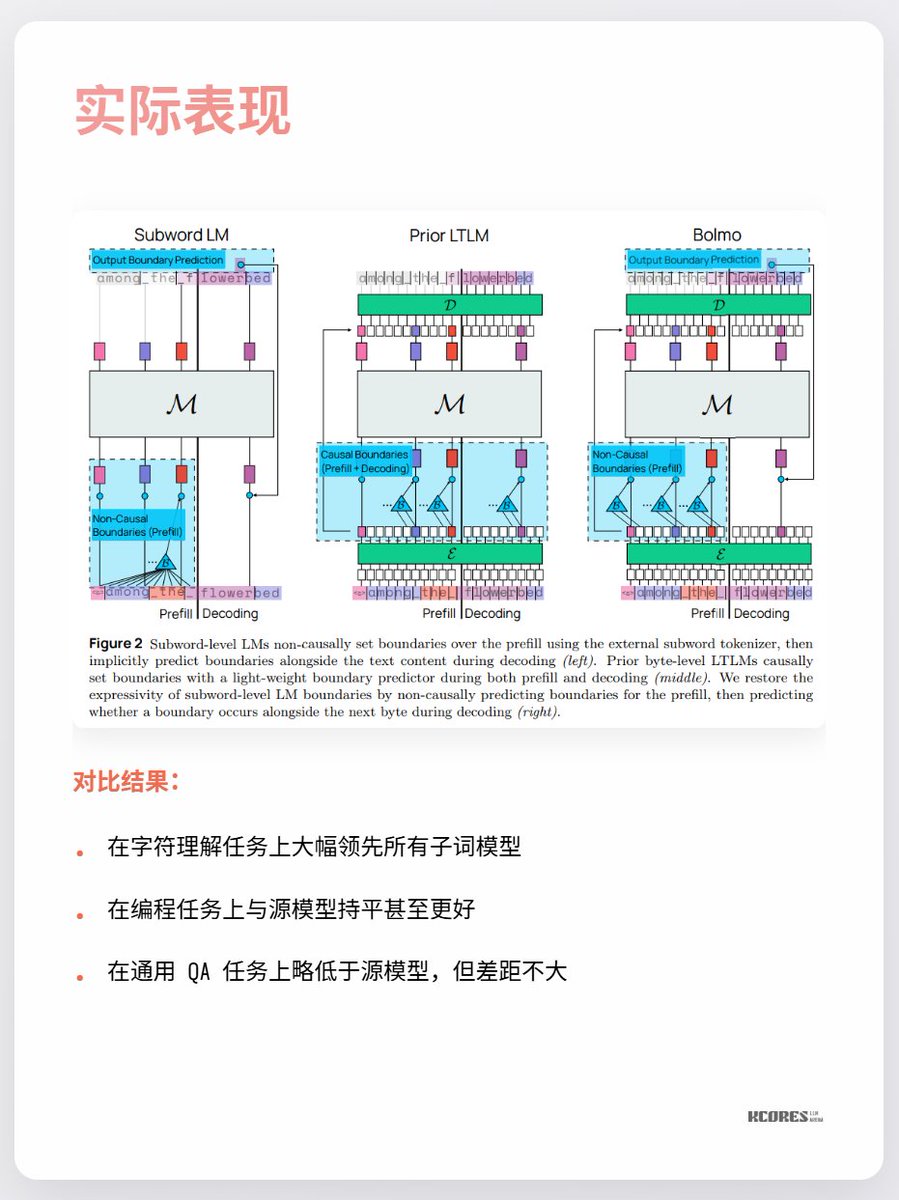
Os principais pontos de discórdia no momento são que não há muitos benefícios visíveis e que sequências mais longas exigem mais cache de chave-valor, aumentando a pressão sobre a memória da GPU. Além disso, a vantagem significativa só é observada na tarefa específica de compreensão de caracteres, com pouca melhoria notável em outras tarefas. Resumindo, vale a pena ficar de olho. A exploração em espiral durante períodos de avanços tecnológicos é sempre muito interessante. Por exemplo, eu particularmente gostava dos retificadores de mercúrio (última imagem), mas eles já foram substituídos pelos IGBTs.

