Todos sabem que modelos de grande escala possuem um tokenizador, que registra as tabelas de segmentação de palavras usadas pelo modelo e é a menor unidade para compreender a semântica e realizar cálculos. Mas você já se perguntou por que precisamos de segmentação de palavras? Não seria melhor simplesmente inserir os tokens diretamente usando a codificação UTF-8? Vamos analisar o novo modelo de hoje, o Bolmo-8B. Eles abandonaram completamente a abordagem tradicional e, em vez disso, usaram bytes UTF-8 como unidade básica, tratando cada caractere como uma sequência de bytes para processamento.
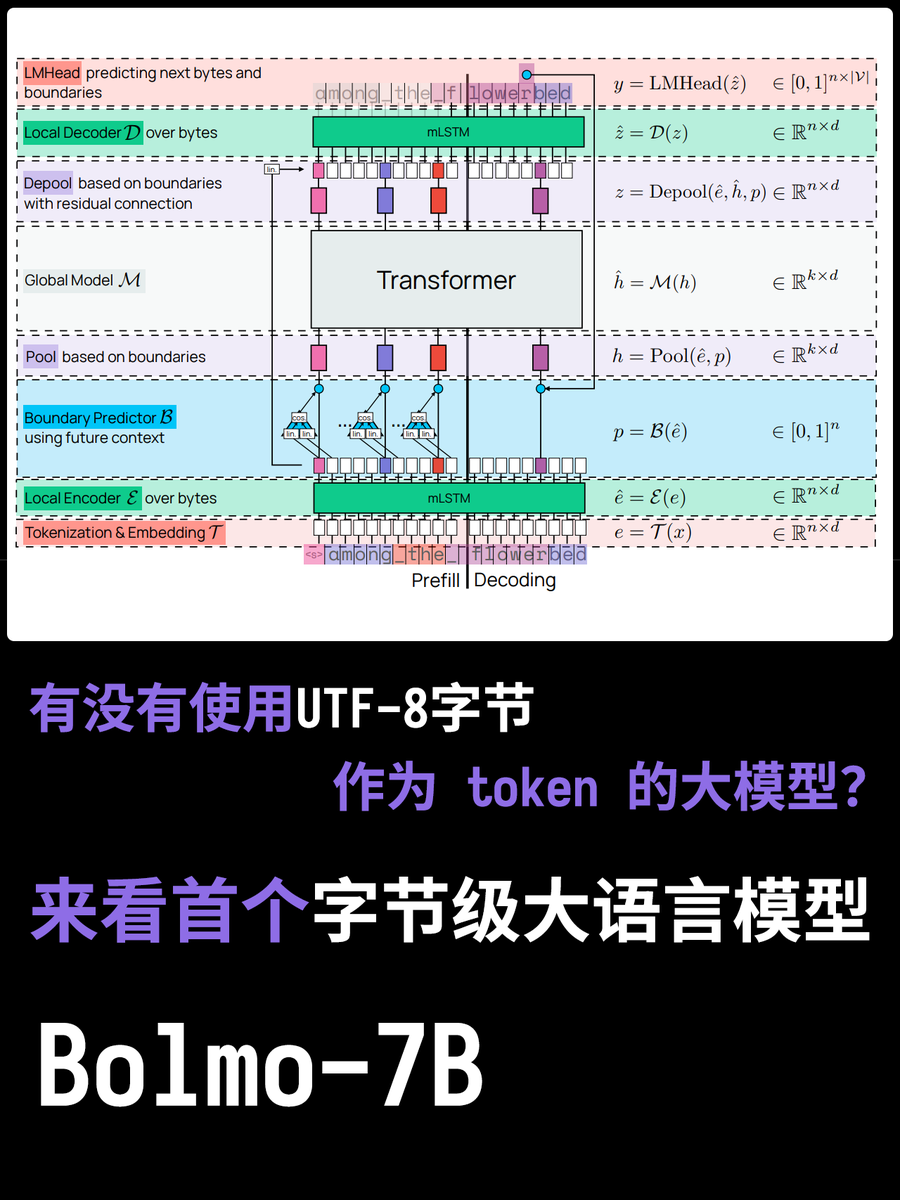
A maior vantagem disso é que perguntas como "Quantos 'r's tem a palavra Strawberry?" podem ser respondidas facilmente! Isso porque cada letra é codificada em UTF-8 de forma independente. No entanto, os problemas que isso acarreta também são muito reais. Às vezes, uma palavra pode ser muito complexa, enquanto outras vezes pode ser muito simples. Os tokenizadores tradicionais conseguem equilibrar esse problema em diferentes graus, mas quando se trata de usar UTF-8, cada palavra precisa consumir um token com o mesmo comprimento da palavra, tornando a alocação de recursos computacionais muito inflexível.
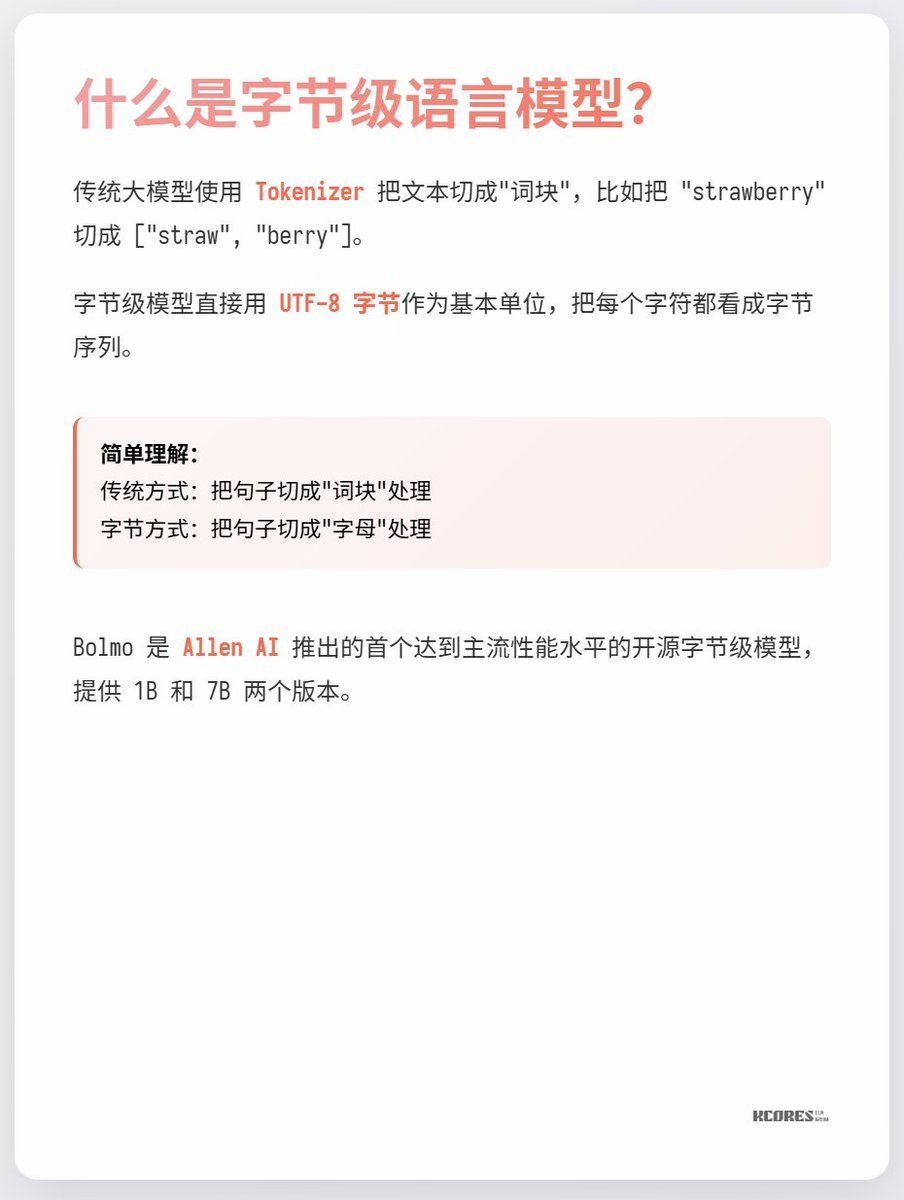



O modelo de Bolmo adota uma abordagem inteligente: em vez de treinar do zero, ele "codifica em bytes" o modelo existente. Possui um codificador/decodificador local integrado que comprime sequências de bytes em "tokens potenciais" antes de alimentá-las em um Transformer tradicional para processamento. Isso permite a conversão com sobrecarga mínima.

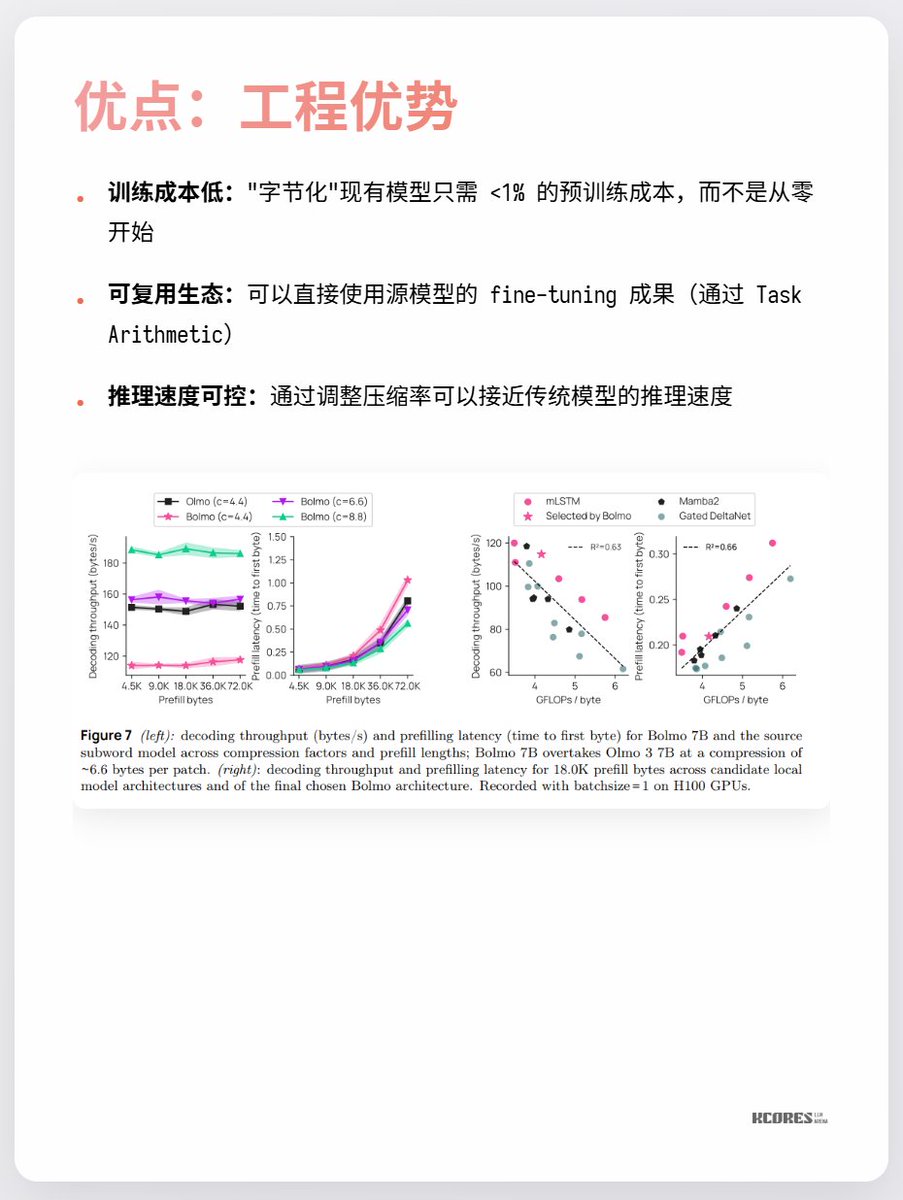

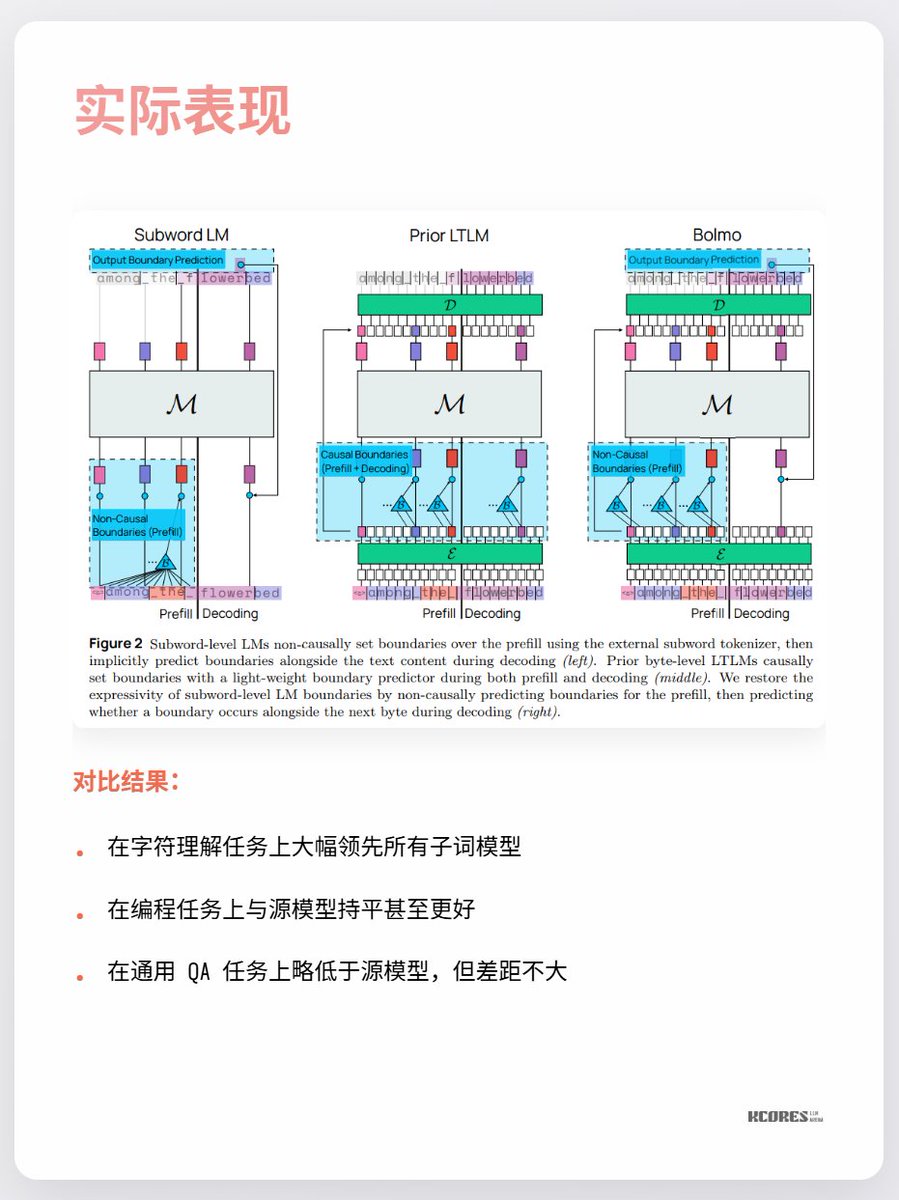
Os principais pontos de discórdia no momento são que não há muitos benefícios visíveis e que sequências mais longas exigem mais cache de chave-valor, aumentando a pressão sobre a memória da GPU. Além disso, a vantagem significativa só é observada na tarefa específica de compreensão de caracteres, com pouca melhoria notável em outras tarefas. Resumindo, vale a pena ficar de olho. A exploração em espiral durante períodos de avanços tecnológicos é sempre muito interessante. Por exemplo, eu particularmente gostava dos retificadores de mercúrio (última imagem), mas eles já foram substituídos pelos IGBTs.

