A NVIDIA acaba de lançar um modelo acelerado projetado especificamente para o GPT-OSS-120B. A NVIDIA acaba de lançar um novo modelo, gpt-oss-120b-Eagle3-throughput, projetado especificamente para funcionar com o gpt-oss-120b. Ele pode ser usado como um pré-modelo para decodificação especulativa do gpt-oss-120b, melhorando assim a velocidade de saída do modelo gpt-oss-120b. Para quem não está familiarizado com a decodificação especulativa, ela envolve o uso de um modelo pequeno para gerar dados e, em seguida, alimentar esses dados em lotes para um modelo maior para correção. Dessa forma, se o modelo pequeno "acertar", a velocidade é muito alta. Além disso, em contextos normais, ainda existem muitas palavras irrelevantes (palavras com frequência extremamente alta na língua, mas que contribuem muito pouco para distinguir a semântica central de uma frase). Portanto, a melhoria na velocidade é significativa.

Informações do modelo / 1




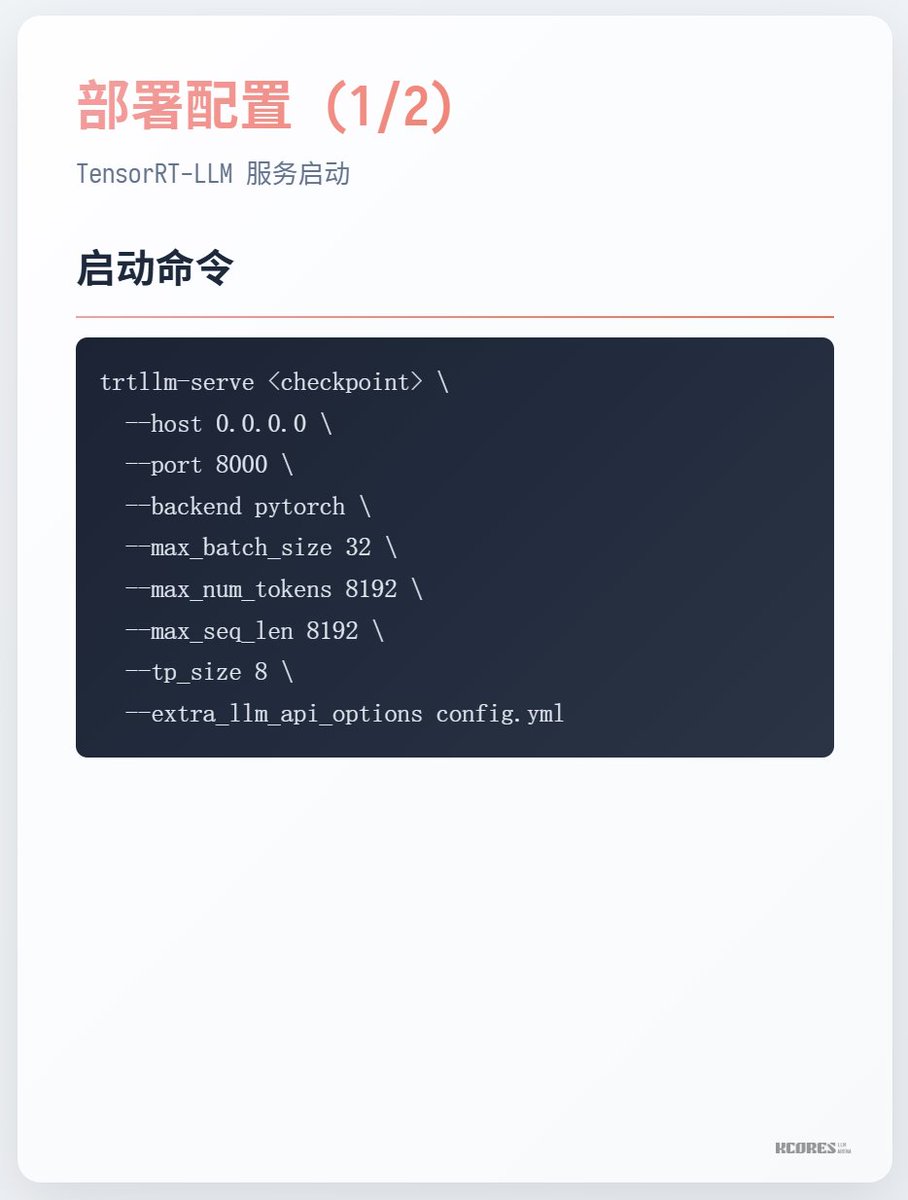
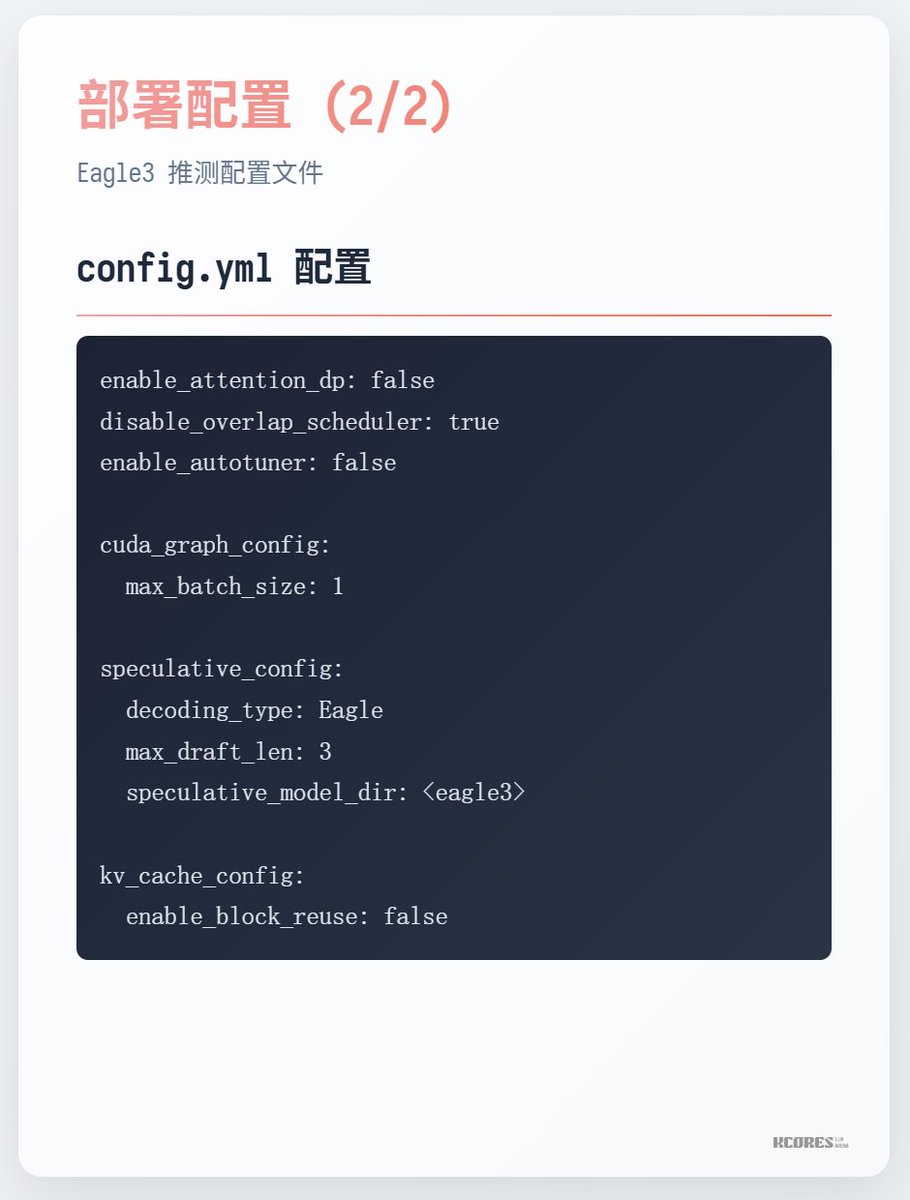
Como executar