O Google lança o novo modelo Gemini 2.5 Flash Native Audio. Utilizado para controlar diversas aplicações de voz em tempo real. "Áudio Nativo" refere-se à capacidade do modelo de gerar diretamente uma saída de fala natural, em vez de gerar primeiro o texto e depois sintetizar a fala. Não só "entende o que você diz", como também "consegue responder imediatamente com voz humana", com um tom, ritmo e pausas mais naturais. As três competências essenciais foram aprimoradas de forma abrangente: 1️⃣ Chamadas de função mais inteligentes O Gemini agora pode acessar proativamente fontes de informação externas durante conversas por voz, tais como: Chame a API de previsão do tempo; Consultar o banco de dados; Receba notícias ou informações sobre ações em tempo real. Não se limita a "responder", mas consegue determinar quando procurar informações e quando continuar a conversa durante o diálogo, podendo também "procurar informações enquanto fala" para manter um fluxo de áudio suave.
2️⃣ Compreensão aprimorada das instruções O Gemini 2.5 Flash Native Audio é mais preciso na compreensão de instruções faladas complexas. Os dados de teste do Google mostram: A taxa de cumprimento das instruções aumentou de 84% para 90%; A integridade e a precisão do conteúdo gerado foram significativamente aprimoradas. 3️⃣ Melhoria na fluência da conversação O Gemini 2.5 Flash Native Audio consegue memorizar o contexto de múltiplas conversas, tornando as transições de voz mais naturais.
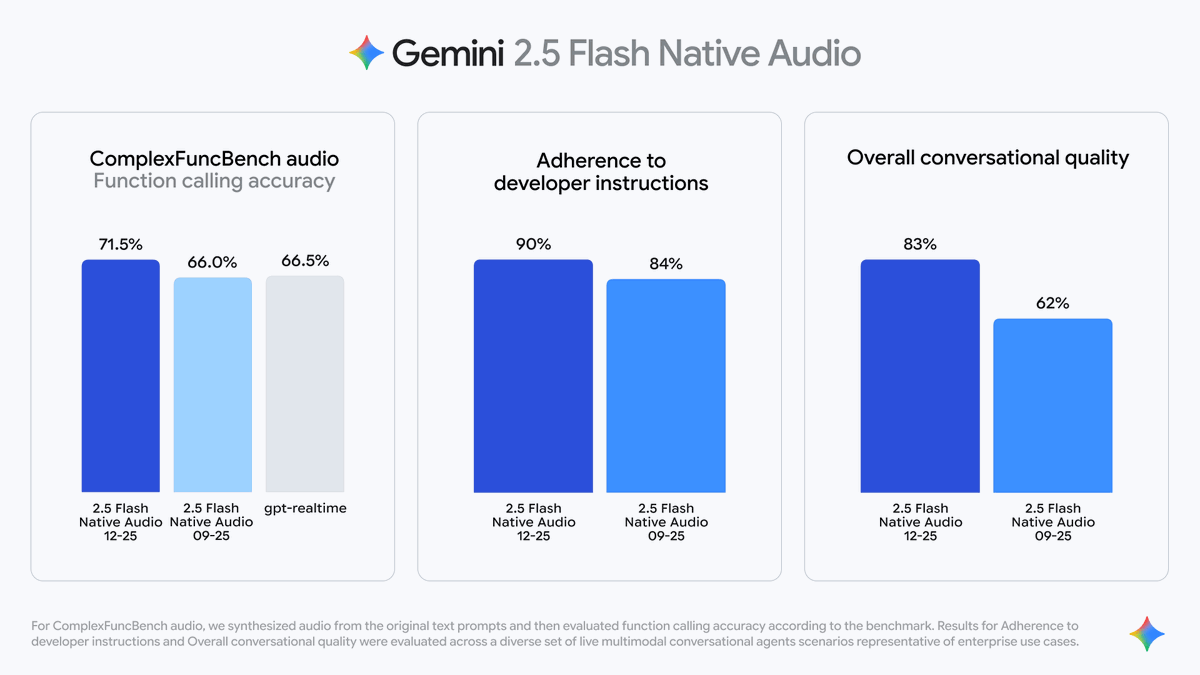
O modelo de áudio nativo Flash Gemini 2.5 já está totalmente disponível no Vertex AI xiaohu.ai/c/xiaohu-ai/go… na API Gemini (versão prévia). Detalhes: https://t.co/CnBlan3RBh