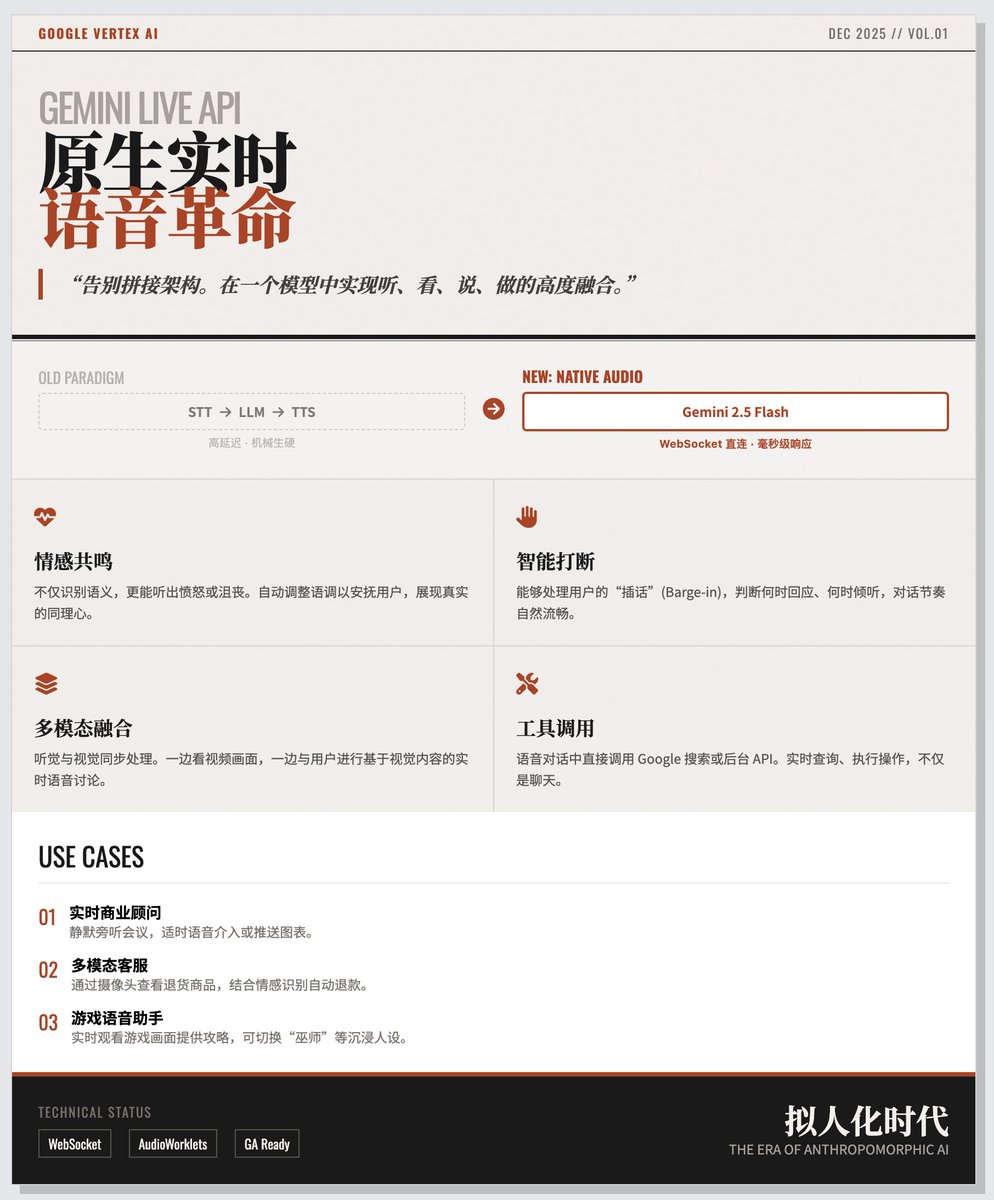
O Google lançou oficialmente a API Gemini Live, baseada no mais recente modelo de áudio nativo em Flash Gemini 2.5. Os desenvolvedores não precisam mais montar meticulosamente conexões complexas de processamento de voz, mas podem alcançar diretamente um alto grau de integração de ouvir, ver, falar e agir em um único modelo. Transformação Essencial: Diga Adeus à Montagem de Alta Latência e Abrace a Comunicação Nativa em Tempo Real. Construir uma IA para diálogo por voz normalmente requer três etapas: STT -> LLM -> TTS. Esse processo não só apresenta alta latência, como também torna o diálogo mecânico e artificial. O grande diferencial da API Gemini Live reside em: • Processamento de áudio nativo: O modelo Gemini 2.5 Flash consegue "ouvir" e compreender diretamente o áudio original e gerar respostas de áudio automaticamente. • Latência extremamente baixa: Elimina etapas de conversão intermediárias e alcança resposta em tempo real em nível de milissegundos por meio de uma única conexão WebSocket. • Fusão multimodal: O modelo não só consegue ouvir, como também processar simultaneamente fluxos de vídeo, texto e informações visuais. Por exemplo, os usuários podem exibir imagens de vídeo enquanto conversam por voz com a IA. Esta postagem no blog, intitulada "Cinco principais capacidades 'semelhantes às humanas'", enfatiza como essa API torna a IA mais parecida com uma pessoa real, em vez de apenas uma máquina de perguntas e respostas. • Ressonância emocional: O modelo consegue ouvir o tom, a velocidade e as emoções do interlocutor (como raiva e frustração) e ajustar automaticamente o seu próprio tom para acalmar o utilizador ou demonstrar empatia. • Interrupção e escuta inteligentes: indo além da simples detecção de voz. A IA pode determinar quando responder, quando permanecer em silêncio e até mesmo lidar com interrupções do usuário, tornando a conversa mais natural. • Acionamento de ferramentas: Durante conversas por voz, a IA pode acionar ferramentas externas em tempo real ou usar a pesquisa do Google para obter as informações mais recentes. • Memória persistente: Manter a coerência contextual em interações multimodais. • Estabilidade de nível empresarial: Como uma versão GA (Disponibilidade Geral), oferece a alta disponibilidade e o suporte multirregional necessários para ambientes de produção. Desenvolvimento e Implantação: De Modelos a Aplicações Reais Para ajudar os desenvolvedores a começarem rapidamente, o Google fornece dois modelos de Início Rápido e três demonstrações representativas de cenários de aplicação: Modelo de desenvolvimento: Modelo Vanilla JS: Sem dependências, adequado para compreender o protocolo WebSocket subjacente e o streaming de mídia. • Modelo React: Design modular com fluxo de trabalho de processamento de áudio, adequado para a criação de aplicações empresariais complexas. Três principais cenários práticos: 1. Consultor de negócios em tempo real: Destaques: Consiste em um "modo silencioso" e um "modo falado". A IA pode ouvir as reuniões como um copiloto, exibindo apenas as informações do gráfico na tela (sem perturbar o espectador) ou intervir por voz para fornecer sugestões quando necessário. 2. Atendimento ao cliente multimodal: Destaques: Os usuários podem mostrar diretamente os produtos problemáticos (como itens devolvidos) através da câmera. A IA combina avaliação visual e reconhecimento de emoções por voz para acionar diretamente as ferramentas de processamento do reembolso. 3. Assistente de voz para jogos: Destaques: A IA monitora o jogo do jogador em tempo real e fornece guias de estratégia. Os usuários também podem trocar a "personalidade" da IA (como um mago sábio ou um robô de ficção científica), tornando-a não apenas uma comandante, mas também uma parceira de jogo. Blog oficial do Google