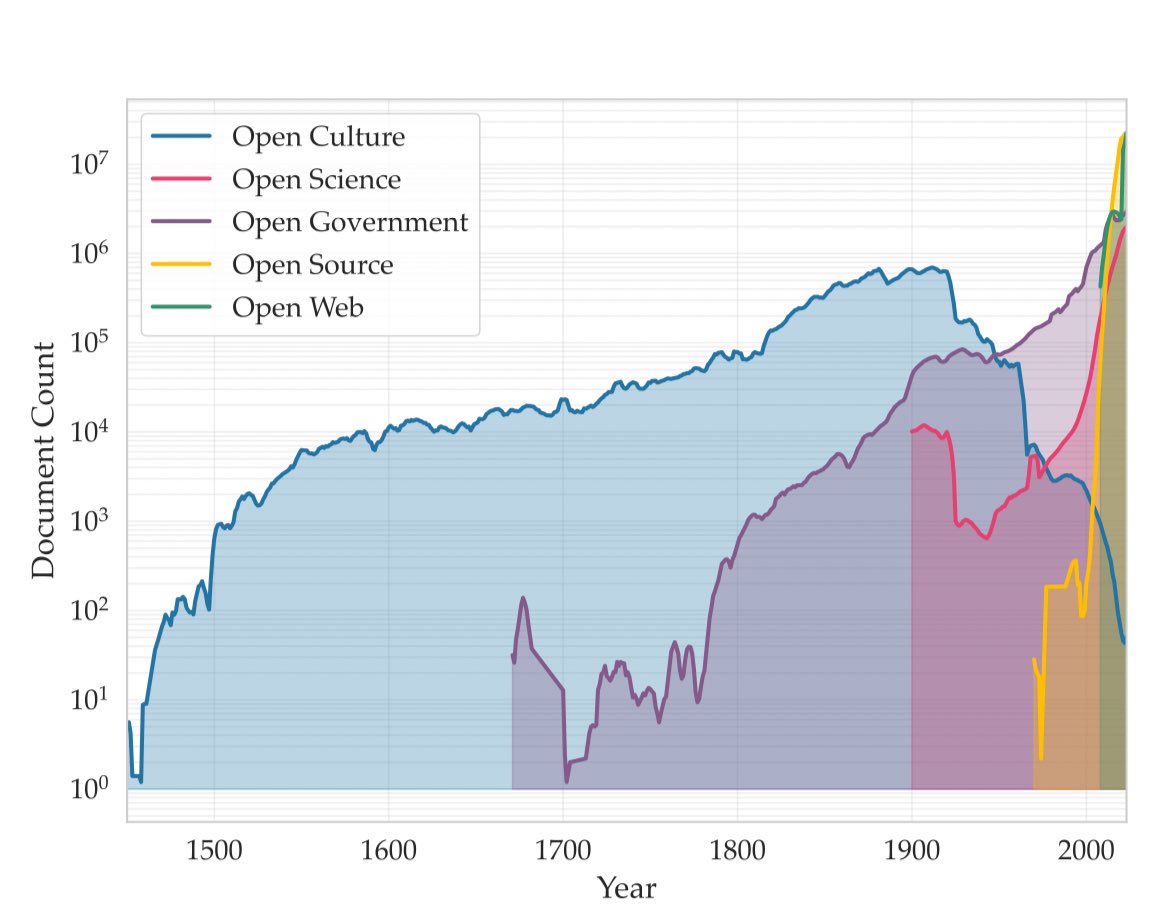
Lembrando que o Common Corpus possui o maior conjunto de dados disponível para esse tipo de projeto: cerca de 900 bilhões de registros anteriores a 1950.
Carregando detalhes do thread
Buscando os tweets originais no X para montar uma leitura limpa.
Isso normalmente leva apenas alguns segundos.
1 tweet · 12 de dez. de 2025, 17:35
Lembrando que o Common Corpus possui o maior conjunto de dados disponível para esse tipo de projeto: cerca de 900 bilhões de registros anteriores a 1950.