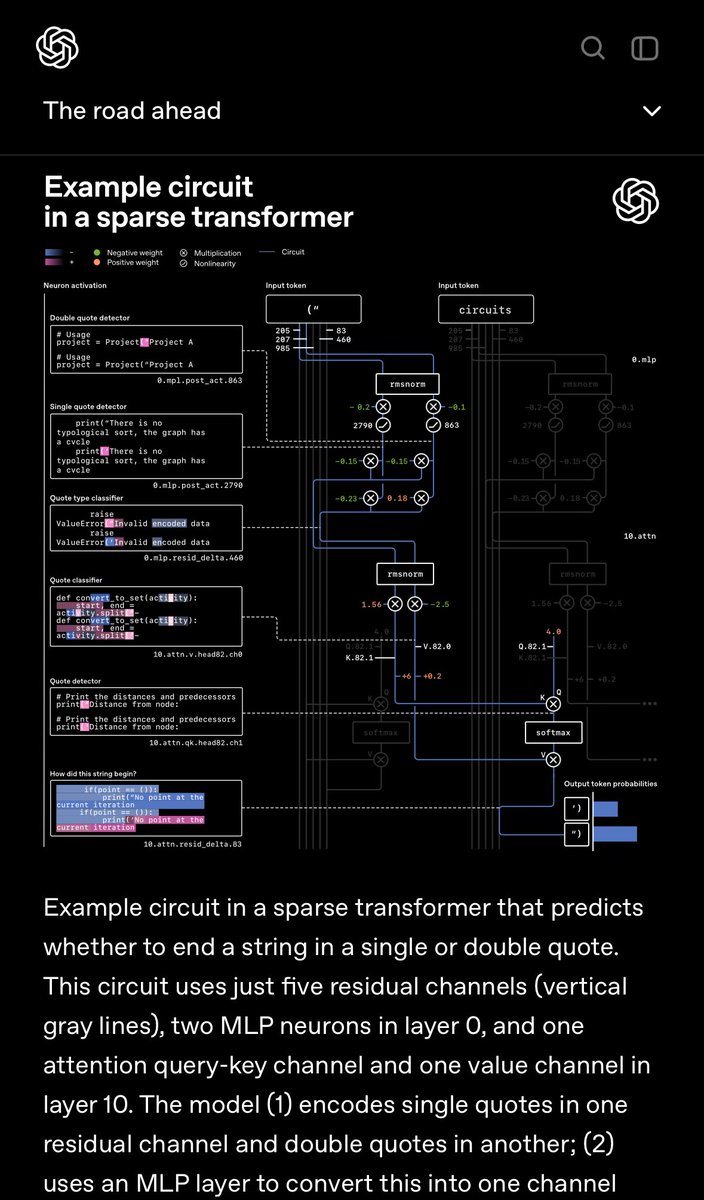
Uma raridade e um presente muito interessante da OpenAI. Em princípio, modelos de ativação inerentemente esparsos com grandes dimensões nominais são preferíveis a modelos de especialistas com poucos especialistas e baixa capacidade. Embora talvez a comunicação entre especialistas em diferentes camadas seja outro caminho viável.