Na verdade, acho que treinei o primeiro LLM histórico de todos os tempos: nosso modelo de correção OCR, o Ocronos, foi totalmente pré-treinado e bloqueado para dados anteriores a 1950, podendo ser usado no modo de modelo base. A maioria das fontes utilizadas eram jornais do Chronicle of America.
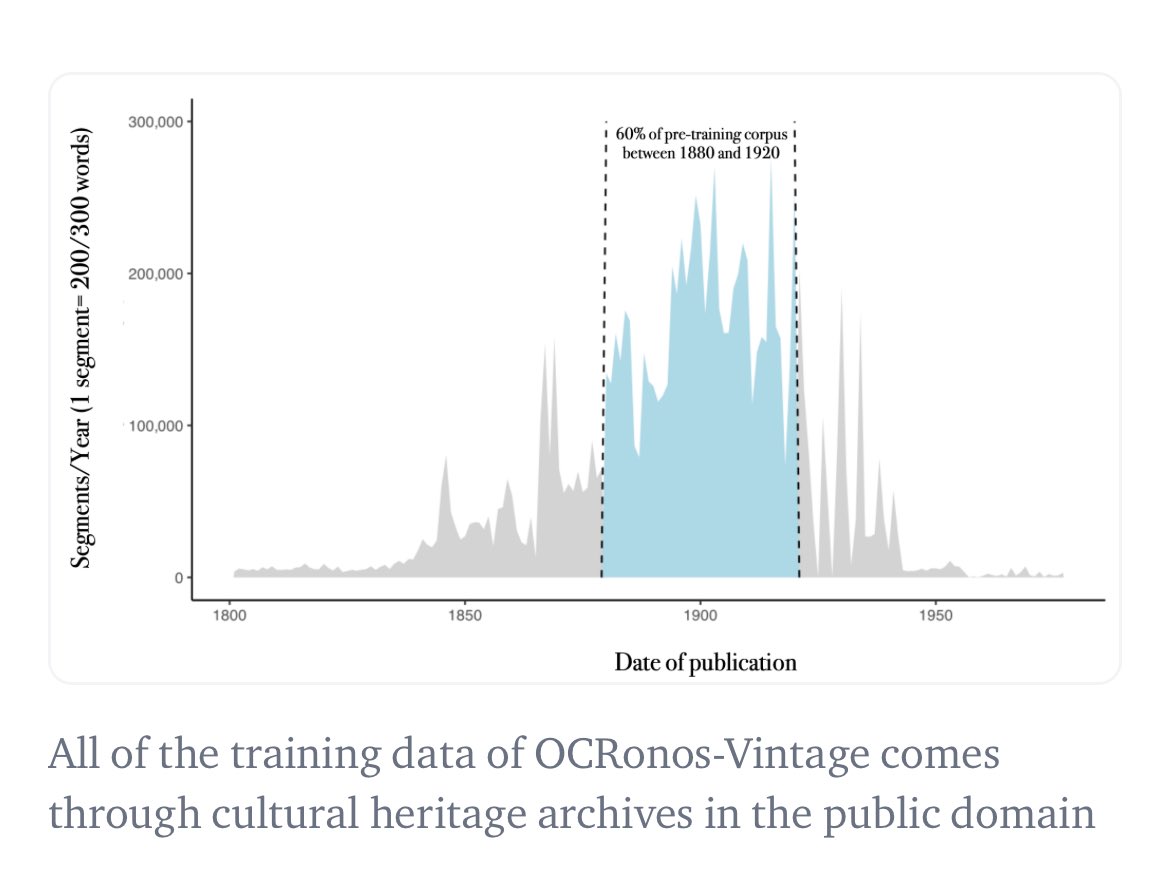
Exemplo de geração historicamente ancorada (o modelo não tem a mínima ideia de quem é Trump e regride ao início do século XX). Vejo que esse modelo ainda é pohuggingface.co/PleIAs/OCRonos…co/1ye5VEGerd

Ted Underwood e outros também treinaram um GPT-1914, que pode muito bem ser o maior modelo histórico até hoje (quase 800 arxiv.org/pdf/2505.00030wSA1WCmz2D
