Lembrando que o Common Corpus possui o maior conjunto de dados disponível para esse tipo de projeto: cerca de 900 bilhões de registros anteriores a 1950.
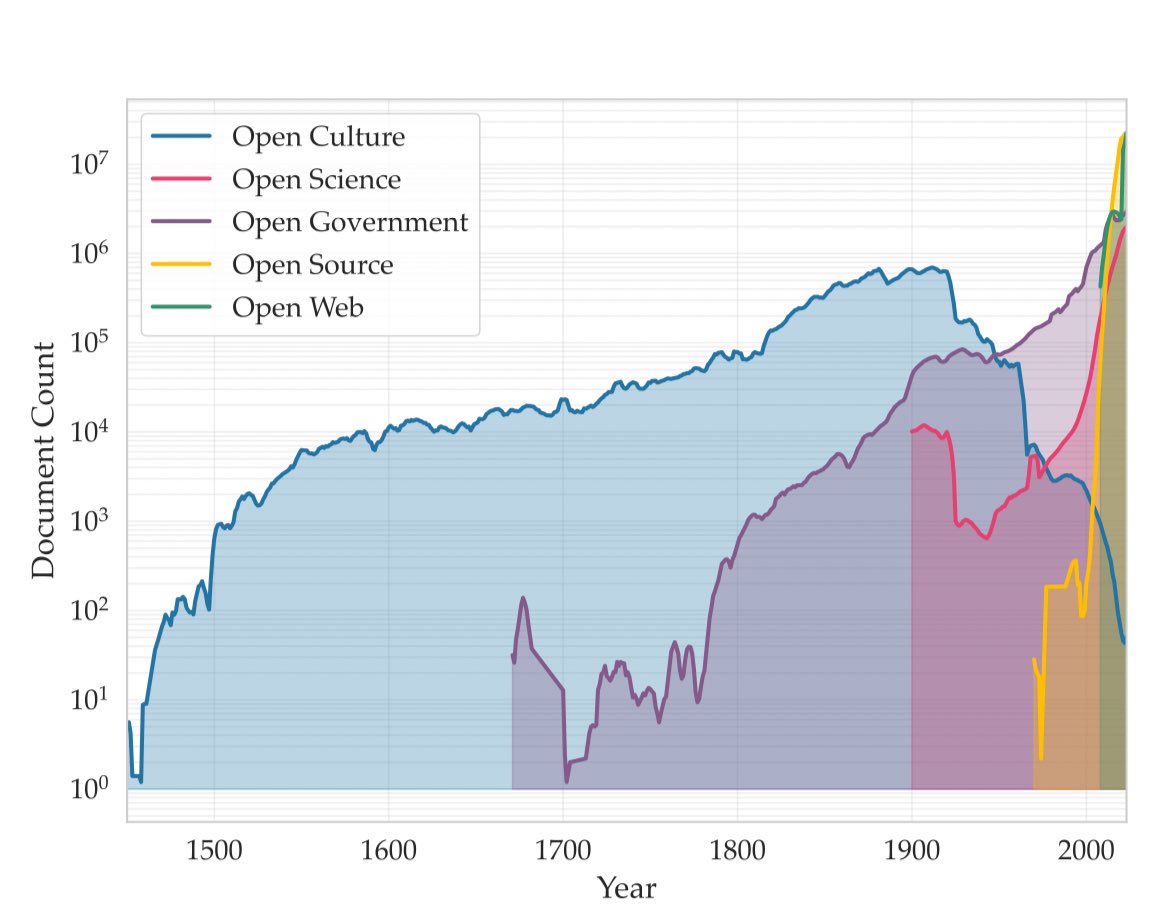
Mas agora eu estaria mais interessado em uma abordagem de ambiente sintético para modelos com sincronização temporal. Um modelo de raciocínio da época romana poderia até ser viável.