Nova pesquisa do Programa de Bolsas de Pesquisa Antropológica: Mascaramento Seletivo de Gradientes (SGTM). Estudamos como treinar modelos de forma que o conhecimento de alto risco (por exemplo, sobre armas perigosas) seja isolado em um pequeno conjunto separado de parâmetros que podem ser removidos sem afetar amplamente o modelo.

O SGTM divide os pesos do modelo em subconjuntos "reter" e "esquecer", e direciona conhecimento específico para o subconjunto "esquecer" durante o pré-treinamento. Esse conhecimento pode então ser removido antes da implalignment.anthropic.com/2025/selective… alto risco. Leia mais: https://t.co/BfR4Kd86b0
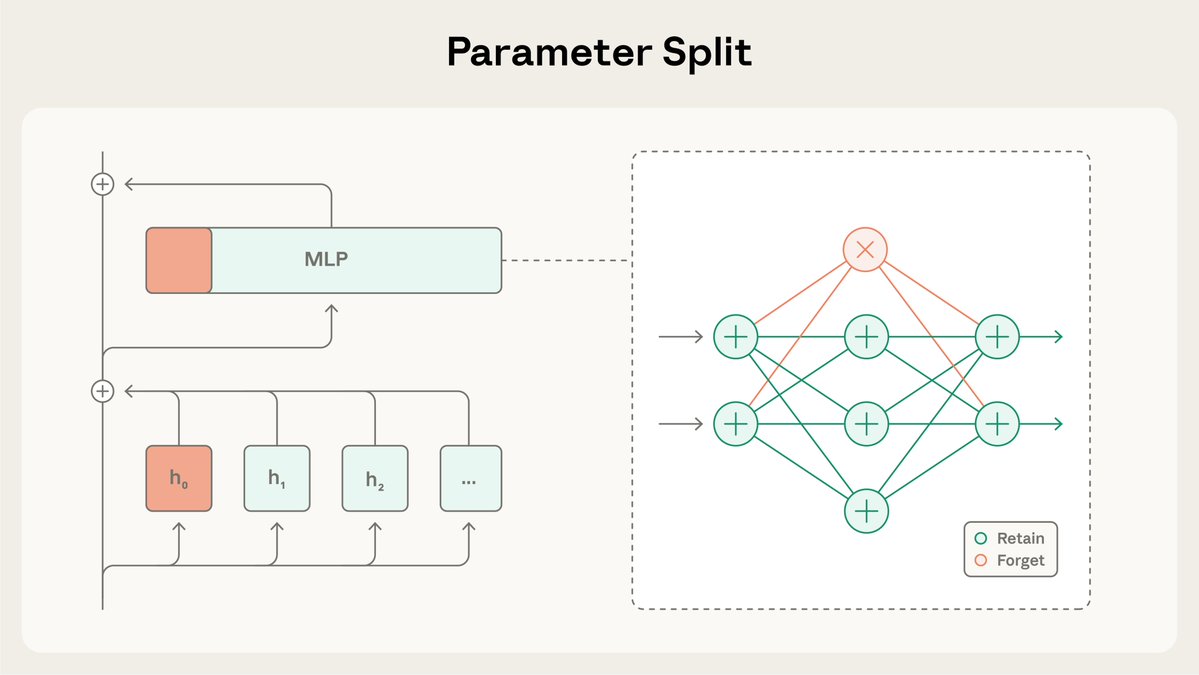
Em nosso estudo, testamos se o SGTM poderia remover conhecimento de biologia de modelos treinados na Wikipédia. A filtragem de dados poderia vazar informações relevantes, visto que páginas da Wikipédia que não tratam de biologia ainda podem conter conteúdo biológico.
Controlando as capacidades gerais, os modelos treinados com SGTM têm um desempenho inferior no subconjunto indesejado de conhecimento "esquecido" em comparação com aqueles treinados com filtragem de dados.

Ao contrário dos métodos de desaprendizagem que ocorrem após a conclusão do treinamento, o SGTM é difícil de desfazer. São necessárias 7 vezes mais etapas de ajuste fino para recuperar o conhecimento esquecido com o SGTM em comparação com um método de desaprendizagem anterior, o RMU.

O estudo apresentou limitações: foi realizado em um ambiente simplificado, com modelos pequenos e avaliações indiretas em vez de parâmetros de referência padrão. Além disso, assim como ocorre com a filtragem de dados, o SGTM não impede ataques contextuais nos quais o adversário fornece as informações por conta própria.
Leia o artigo completo sobre SGTM arxiv.org/abs/2512.05648tjX7hD Para garantir a reprodutibilidade, também disponibilizamos o código rgithub.com/safety-researc…ps://t.co/zRmJYy6bDE.
Esta pesquisa foi liderada por @_igorshilov como parte do Programa de Bolsas de x.com/_igorshilov/st…