Há alguns dias, apresentei nossa solução vencedora do Desafio BEHAVIOR 2025 na @NeurIPSConf. Agora, disponibilizamos nossa solução em código aberto: código, pesos do modelo e um relatório técnico detalhado. Deixe-me explicar o que fizemos 👇
O que é o Desafio Comportamental? Nesta competição, tivemos que treinar um robô capaz de realizar 50 tarefas domésticas robóticas em uma simulação de alta qualidade. A política controla um robô humanoide bimanual com uma base móvel, e as tarefas variam de 1 a 14 minutos. Leia mais detalhes na publicação de @drfeifei: https://t.co/jDviv5d6pB
Nossa equipe independente, composta por mim, @zaringleb e @akashkarnatak, conquistou o 1º lugar com uma pontuação de 26% (incluindo sucessos totais e parciais).
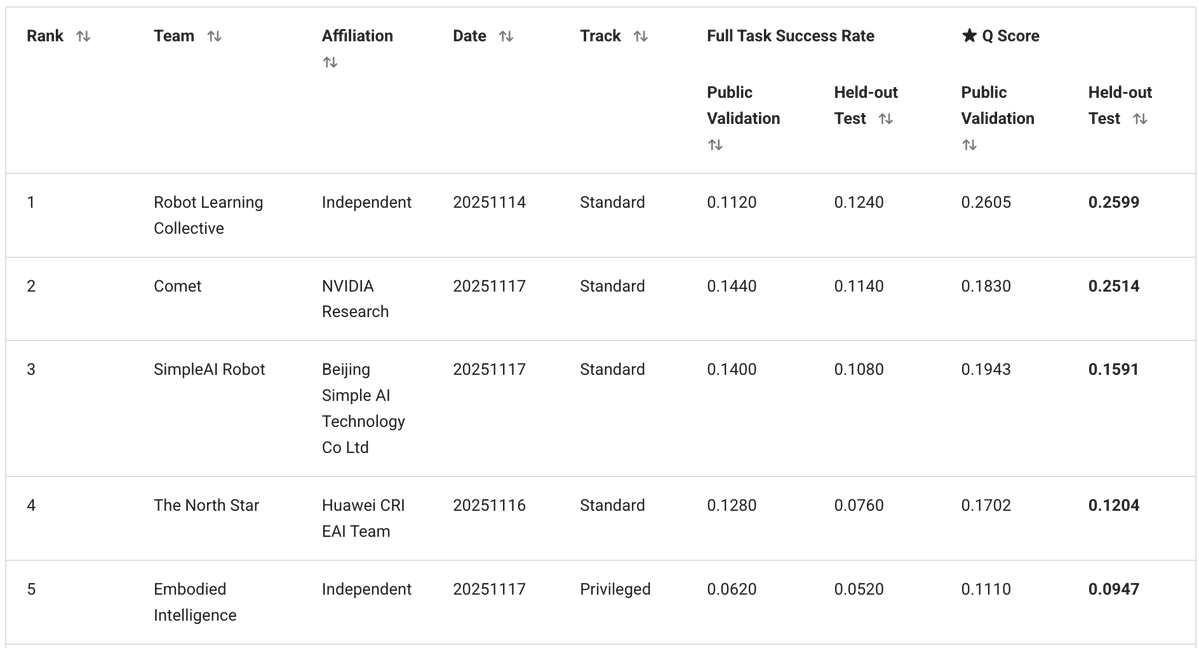
Nossa solução é baseada no VLA Pi0.5 da @physical_int e construída sobre o repositório openpi. Modificamos substancialmente o modelo, assim como os processos de treinamento e inferência.
- O modelo BEHAVIOR possui um conjunto fixo de 50 tarefas. Como não precisamos generalizar para novos prompts de texto, removemos o texto completamente e o substituímos por 50 embeddings de tarefas treináveis (um por tarefa). - O conjunto de dados de treinamento continha múltiplas modalidades (RGB, profundidade, segmentação), bem como anotações adicionais de subtarefas, mas optamos pela abordagem mais simples: apenas imagens RGB e o estado do robô. - Prevemos blocos de ação de 30 etapas (1s) e usamos ações delta com normalização por carimbo de data/hora.
Muitas imagens parecem idênticas, mas correspondem a subtarefas muito diferentes. Por exemplo, nestas duas imagens: em uma, o micro-ondas está vazio e o robô deve abri-lo primeiro; na outra, a pipoca já está dentro e ele deve ligar o micro-ondas. Você consegue adivinhar qual é qual? Isso também confunde o robô. Por padrão, os VLAs não têm memória, então eles não sabem exatamente o que fazer em seguida.


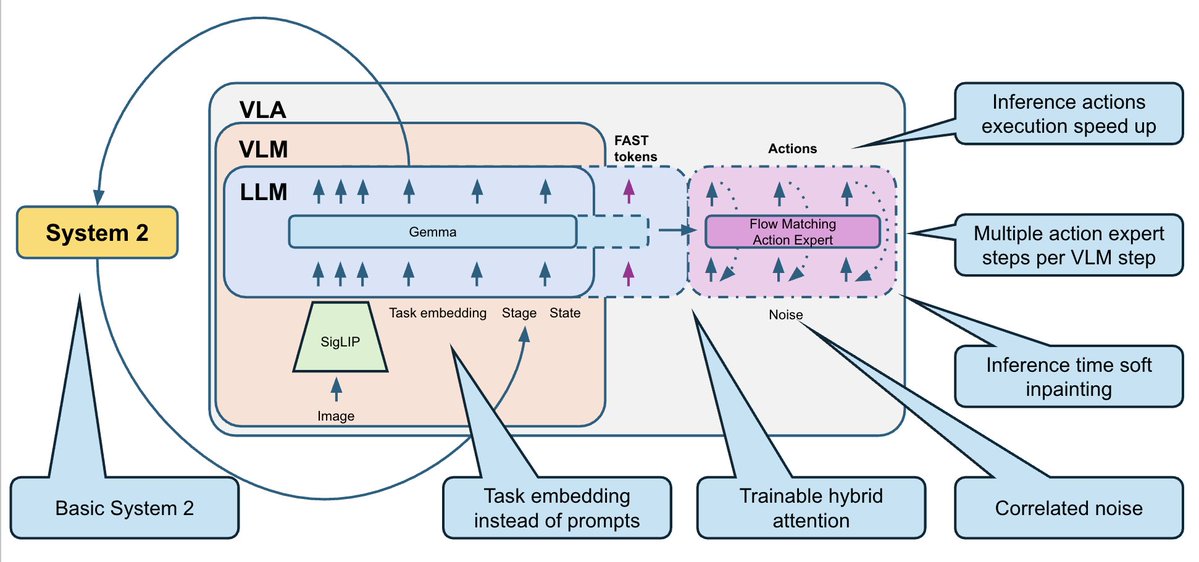
Para corrigir isso, adicionamos uma lógica básica do Sistema 2 que rastreia o progresso da conclusão da tarefa: - Treinamos o VLA para prever o estágio atual como uma cabeça auxiliar. Ao mesmo tempo, pode usar o palco para resolver ambiguidades no quadro atual. - Durante a inferência, suavizamos as previsões de estágio com uma lógica de votação: os estágios podem progredir apenas passo a passo (0, 1, 2, 3, ...). - Reinserimos o cenário no modelo como entrada adicional. Isso fornece à política um contexto adicional sobre o progresso da tarefa e corrige muitos erros do tipo "esqueci onde estou".
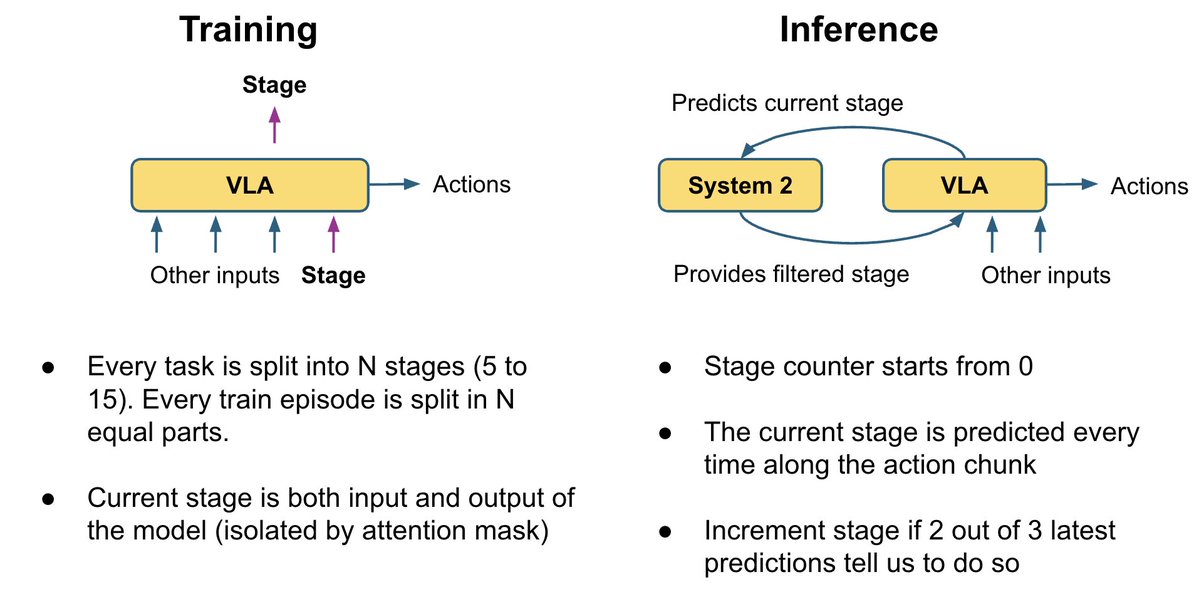
Diferentes artigos sobre VLA conectam a cabeça de ação às camadas VLM de maneiras distintas: alguns consideram todas as camadas VLM, outros ignoram metade, outros consideram apenas a última; às vezes, são usadas atenções cruzadas e autoatenções separadas, e outras vezes, elas são combinadas. Em vez de escolher e codificar uma dessas opções, deixamos o modelo aprender a melhor combinação para cada camada de ação. Nosso especialista em ações trabalha com uma combinação linear treinável de todas as camadas VLM, permitindo que ele aprenda a combinação ideal para cada camada de ação.
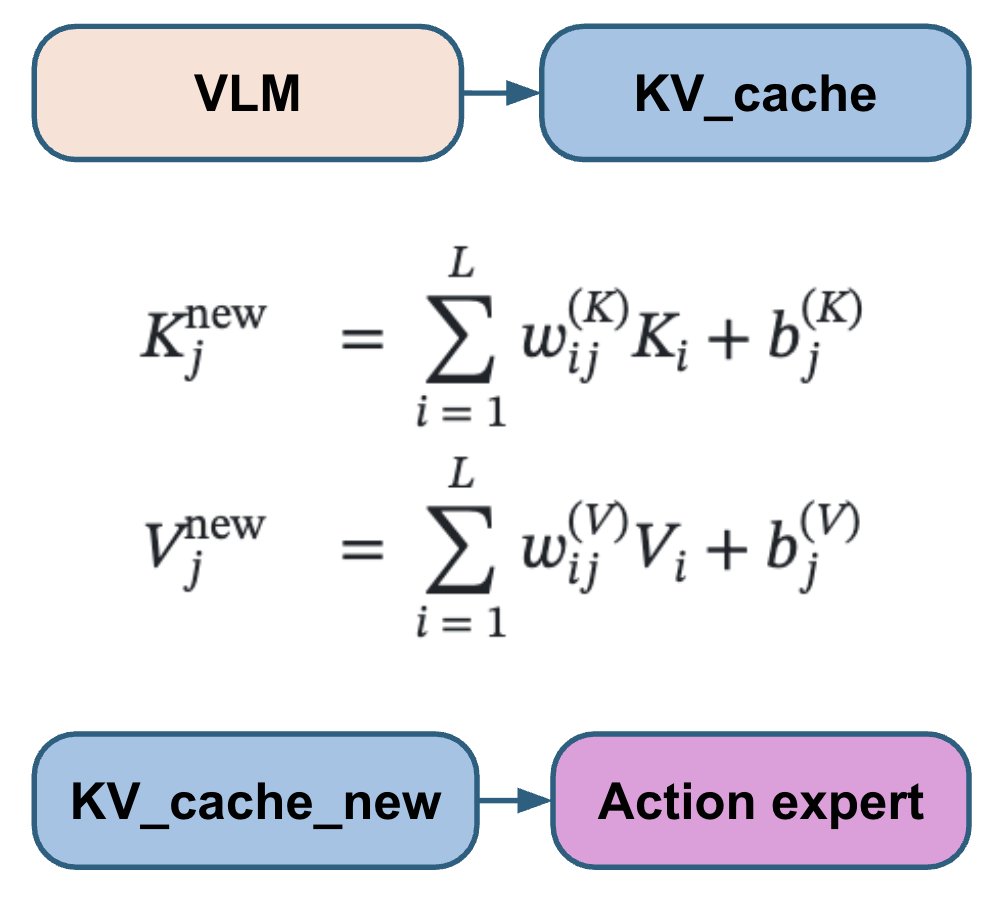
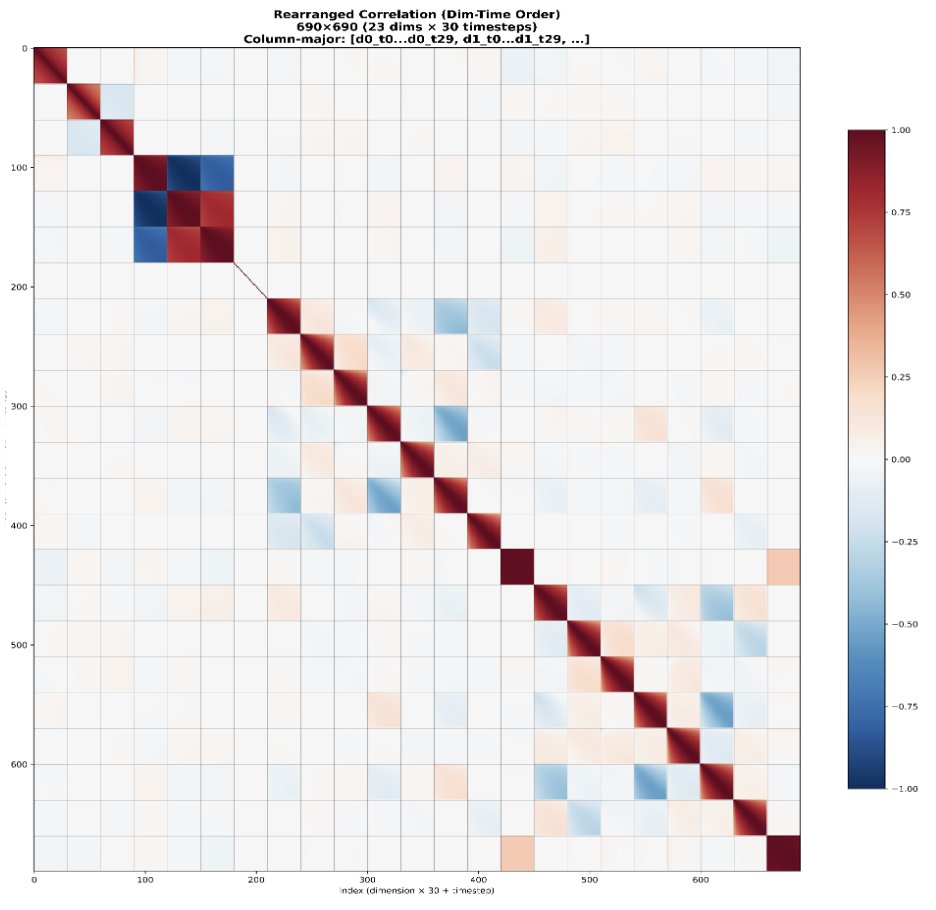
O método padrão de correspondência de fluxo utiliza ruído gaussiano iid. No entanto, as ações do robô são altamente correlacionadas tanto ao longo do tempo quanto entre as articulações. Isso faz com que as etapas de correspondência de fluxo tenham níveis de dificuldade desiguais: as primeiras etapas são muito mais difíceis, enquanto as posteriores são muito mais fáceis, porque o modelo pode usar as correlações conhecidas como um atalho. Em vez disso, usamos ruído de N(0, 0,5 Σ + 0,5 I) em vez de N(0, I), onde Σ é a matriz de covariância da ação estimada a partir do conjunto de dados. Isso visa tornar a dificuldade de todas as etapas mais uniforme.
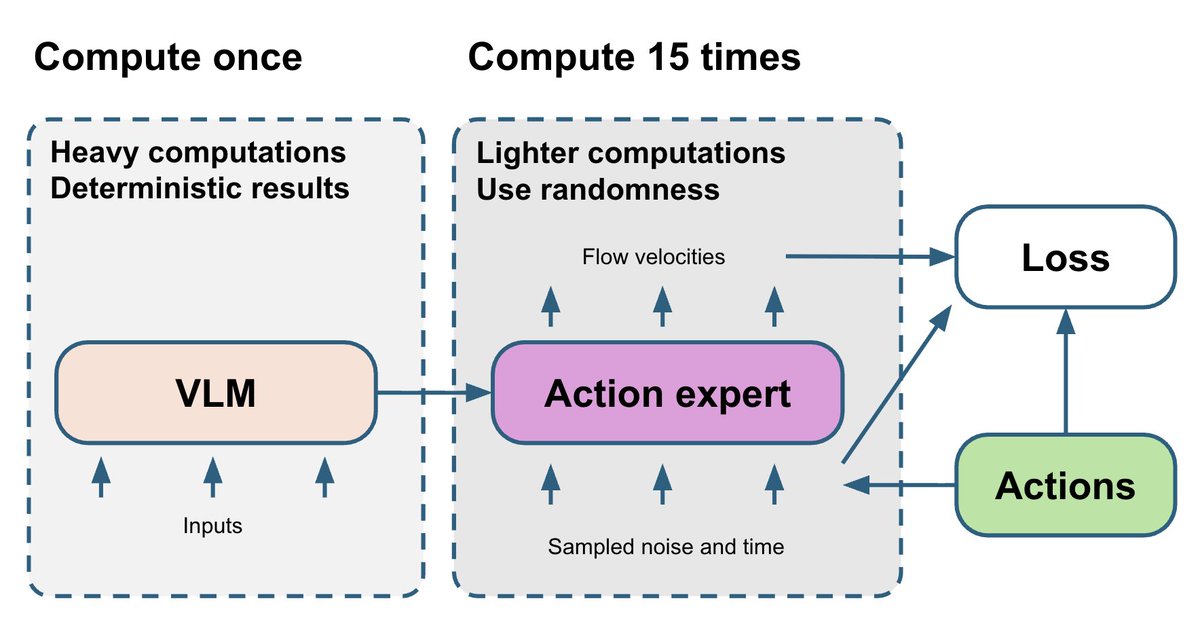
A parte VLM é a mais complexa e determinística. O especialista em ações de correspondência de fluxo é relativamente menor, mas seu treinamento depende de duas variáveis aleatórias: t e ruído. Eventualmente, o gradiente ruidoso do especialista em ações retorna para a parte VLM. Para melhorar isso, sorteamos 15 pares diferentes (t, ruído) e executamos o algoritmo especialista em ações 15 vezes para cada passagem direta do VLM. Isso utiliza apenas um pequeno orçamento computacional adicional, mas torna o gradiente do algoritmo especialista em ações mais estável.
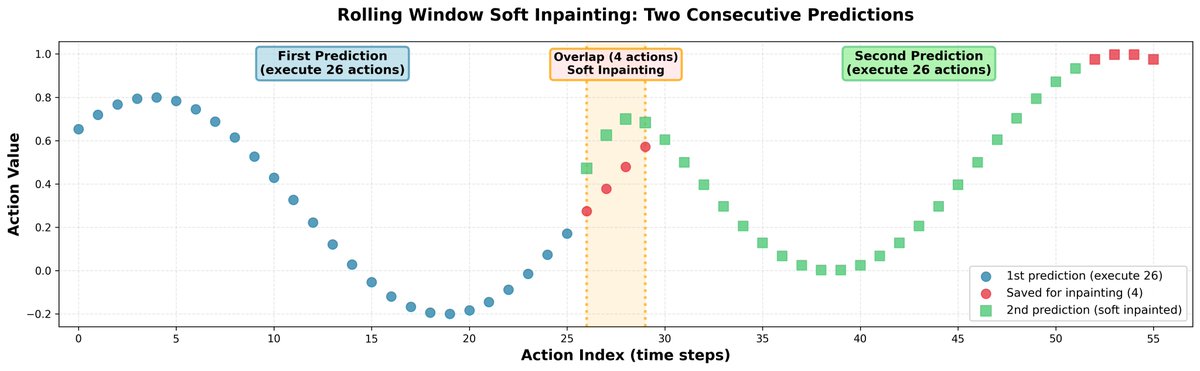
Durante a inferência, prever blocos de ação completamente independentes pode levar a saltos nas trajetórias e a um comportamento indeciso por parte da política. Para solucionar isso, conectamos todos os blocos por meio de inpainting: - Prevemos 30 ações simultaneamente, mas executamos apenas 26. Os 4 restantes são usados como entrada inicial para a próxima previsão. - Ao prever as próximas 30 ações, preenchemos suavemente as primeiras 4 ações para que fiquem muito próximas das ações salvas anteriormente. Para preservar a correlação entre as ações, propagamos a correção para o restante do horizonte usando a matriz de correlação aprendida. Resultado: trajetórias suaves do robô, sem descontinuidades bruscas.
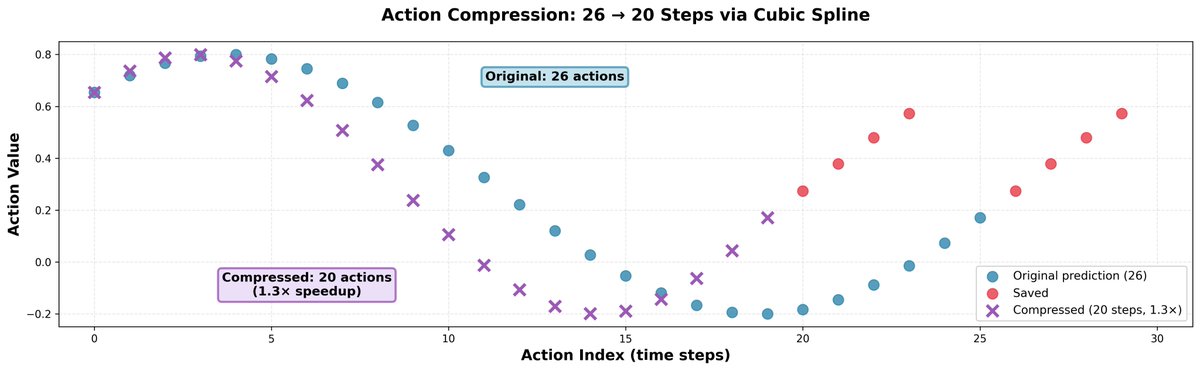
Descobrimos que ir um pouco mais rápido do que as previsões do modelo geralmente ajuda; isso não reduz a precisão dos movimentos, mas torna o robô mais rápido e permite que ele faça mais no mesmo período de tempo. O truque é simples: pegamos 26 ações e as comprimimos em 20 usando interpolação spline cúbica, depois as executamos em 20 etapas. Isso resulta em um aumento de velocidade de 1,3x.
O conjunto de dados de treinamento para este problema é extremamente limpo: não há falhas nem demonstrações de recuperação. Isso representa um problema para as políticas de robótica, pois elas não conseguem aprender a se recuperar nem mesmo de erros simples. Um padrão comum: o robô tenta pegar o objeto, mas falha e fecha a garra. Então ele simplesmente fica parado sem fazer nada, porque não sabe que pode abrir a garra e tentar novamente. Implementamos uma heurística simples que abre a garra se ela estiver fechada em uma configuração na qual nunca esteve fechada em nenhuma demonstração para esta tarefa e etapa. Essa regra simples praticamente dobrou a pontuação q em um subconjunto de tarefas em nosso pequeno estudo.
Mas, às vezes, o comportamento de recuperação surgia naturalmente do treinamento multitarefa. No primeiro vídeo, você vê o comportamento típico de falha da política treinada em apenas uma ou algumas tarefas. Se ela comete um erro (por exemplo, deixa a imagem cair no chão), ela simplesmente para e não faz nada, já que essa situação nunca ocorreu nos dados de treinamento. No segundo vídeo, você vê o comportamento de recuperação da política treinada em todas as 50 tarefas. Tendo visto outras tarefas em que era necessário pegar objetos do chão, ela generaliza para essa situação e captura a imagem caída.
Os recursos computacionais foram essenciais nesta competição. O conjunto de dados de treinamento completo consiste em mais de 1000 horas de dados de teleoperação, e uma época em 8 GPUs H200 leva cerca de 2 semanas. Treinamos a política por cerca de 30 dias, o que corresponde a aproximadamente 2 épocas. Agradecemos imensamente à @nebiusai pelo patrocínio com créditos de GPU, que tornaram isso possível.
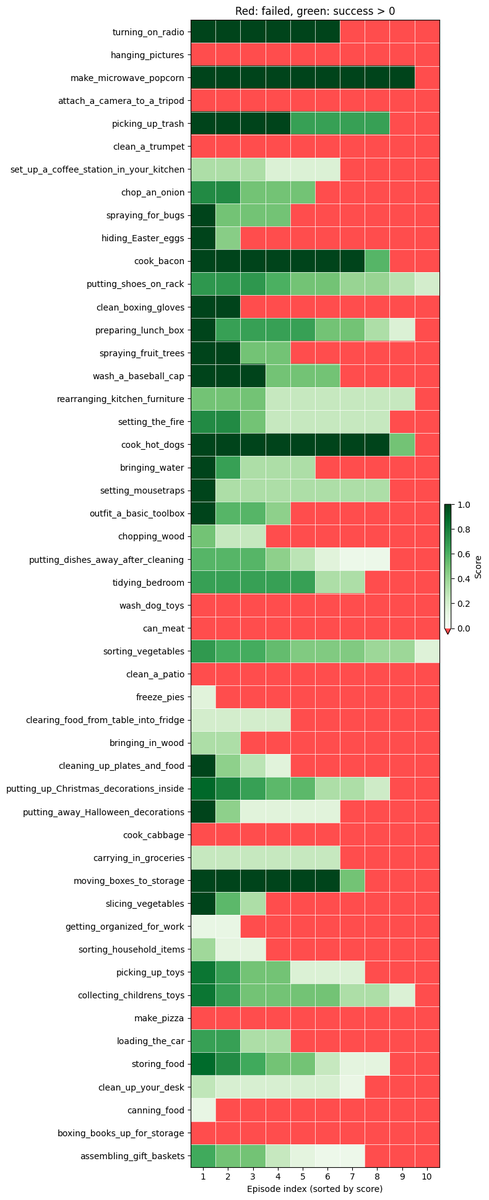
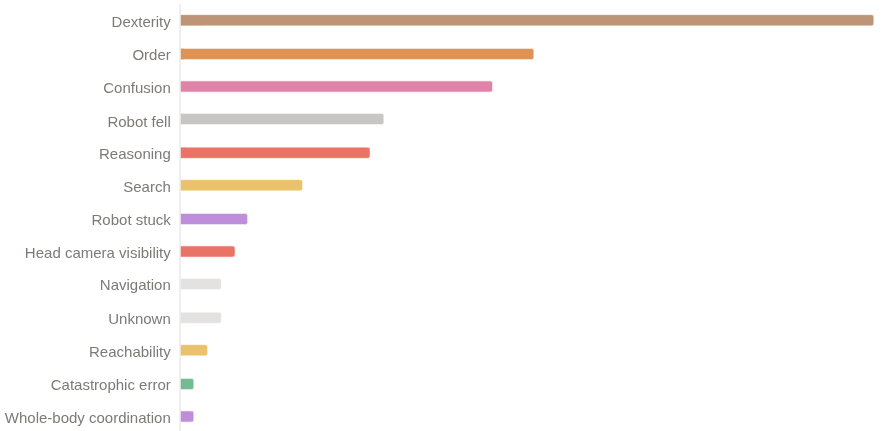
Apesar de termos conquistado o primeiro lugar, acreditamos que ainda há muito espaço para melhorias. Obtivemos uma pontuação q de 26% e uma taxa de sucesso binário de 11 a 12%. Os principais motivos pelos quais a política ainda falha são: - Problemas de destreza (preensão, liberação) - Erros de progresso em sequências longas - Ficar confuso após entrar em estados fora de distribuição
Disponibilizamos todo o código-fonte da nossa solução: o código, os pesos do modelo e um relatório técnigithub.com/IliaLarchenko/… https://t.huggingface.co/IliaLarchenko/…https://t.co/f3arxiv.org/abs/2512.06951cnico: https://t.co/TeFiiTha0d Mais tarde, também gravarei um vídeo explicativo com mais detalhes. Fiquem ligados! 🎥