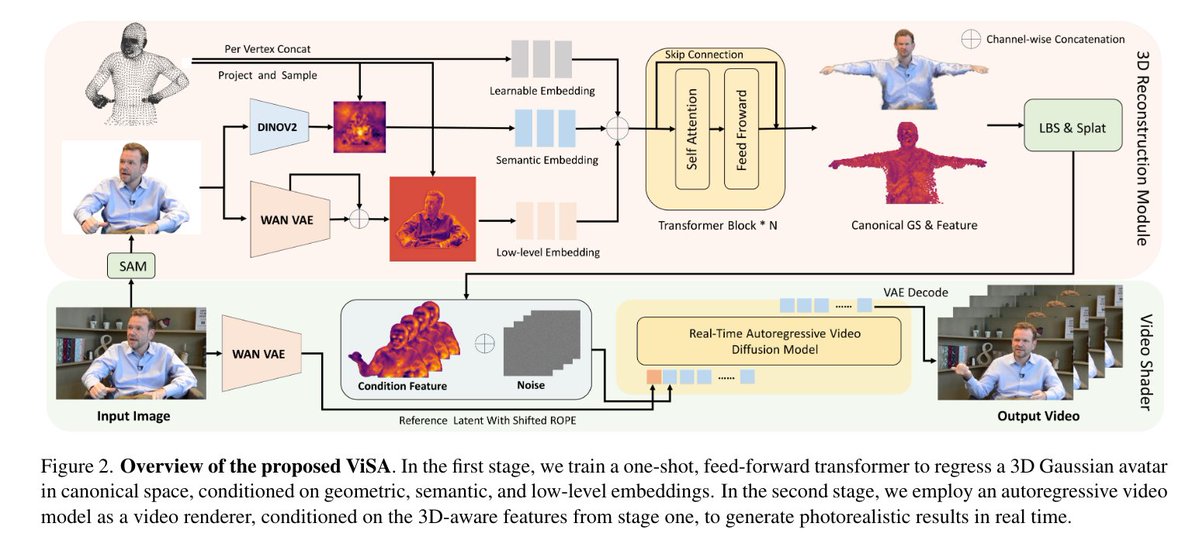
ViSA: Sombreamento de vídeo com reconhecimento 3D para criação de avatares da parte superior do corpo em tempo real Contribuições: i) Propomos uma nova estrutura que integra a reconstrução de avatares 3D em uma única captura com um shader de vídeo autorregressivo em tempo real, unificando a estabilidade geométrica com o poder de renderização generativa. ii) Apresentamos uma nova função de perda adversária para preservação de distribuição, que permite o ajuste fino e eficiente de um modelo de difusão de vídeo pré-destilado e de poucos passos, para que ele atue como um poderoso renderizador neural, mitigando a degradação típica da qualidade. iii) Nosso método estabelece um novo estado da arte na geração de avatares da parte superior do corpo em tempo real, alcançando qualidade visual e realismo de movimento superiores, validados por comparações qualitativas e quantitativas abrangentes.
Artigo:arxiv.org/abs/2512.077207 Projetolhyfst.github.io/visa/tT