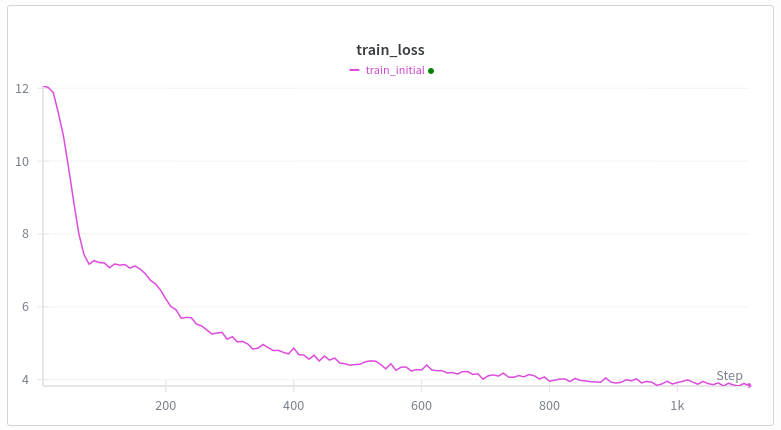
Sempre que treino um Transformer do zero com webtext, a curva de perda fica assim. A primeira queda faz sentido, mas por que a segunda? Gêmeos está me dizendo bobagens. A arquitetura é a mesma do gpt2, exceto por swiglu, rope e untied embeddings. treinamento: múon + adão Aquecimento linear (até 500 passos) A minha melhor hipótese é o meme da formação da cabeça durante a indução, mas pelo que entendi, isso acontece bem tarde, tipo depois de vários milhares de passos de treino ou um bilhão de tokens ou algo assim, e eu tenho 100 mil tokens por lote. Alguém que trabalhe com treinamento em transformadores sabe por que isso acontece?