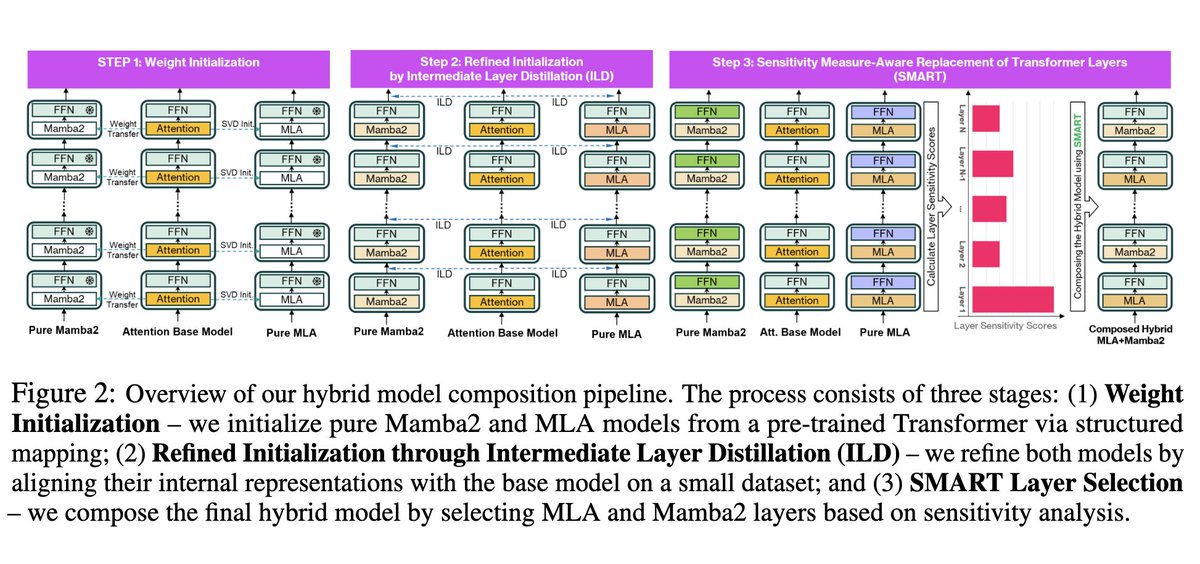
Passou despercebido: um híbrido Mamba-2+MLA, *pós-treinado* a partir do Llama 3. Sabíamos que GQA=>MLA completo era possível. Kimi provou que é possível combinar MLA e atenção linear (embora o KDA seja mais sofisticado que o Mamba2), mas eles treinaram do zero. Isso é tecnicamente impressionante.