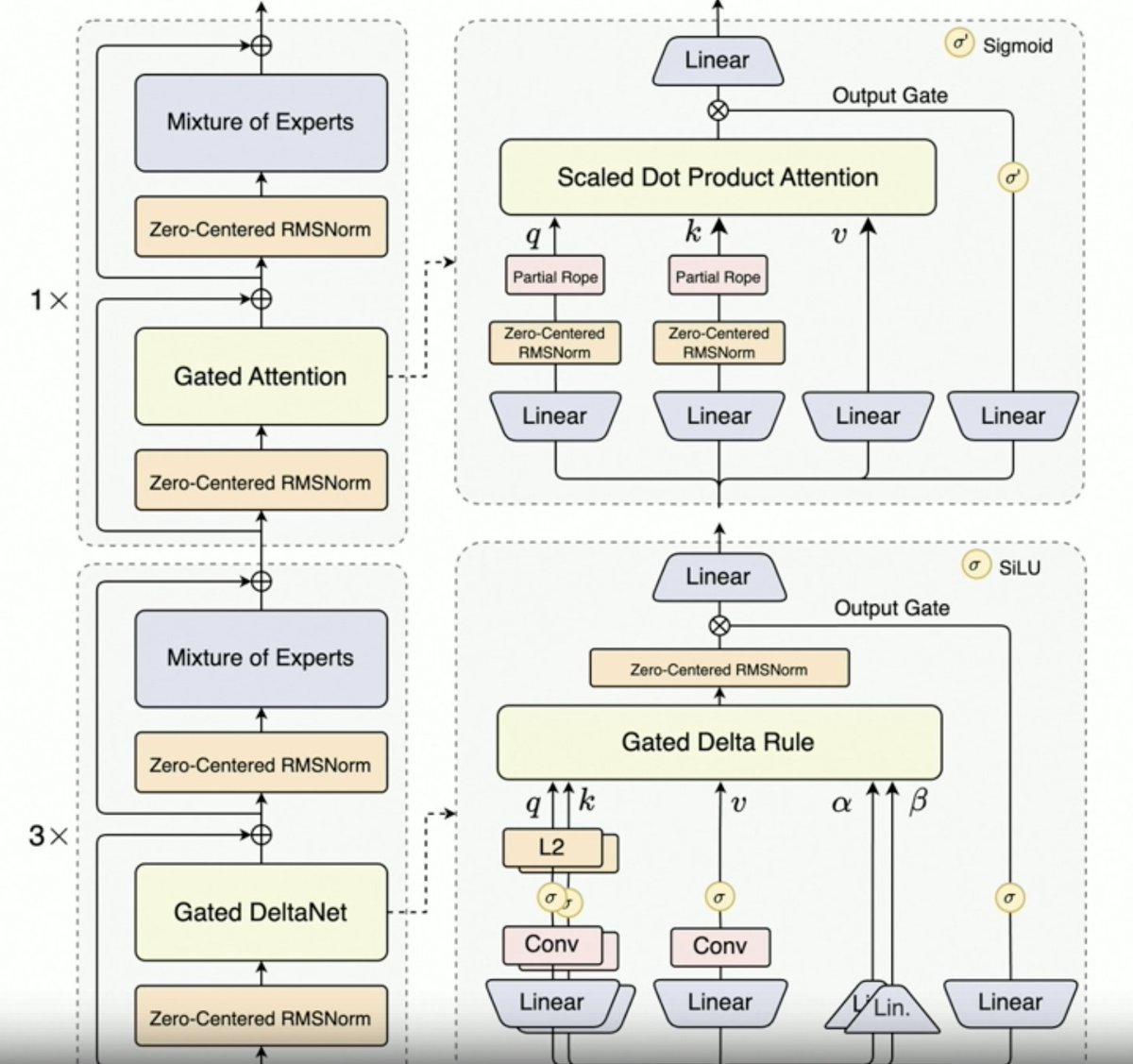
Por @JustinLin610 (Qwen 3 Coder) falando sobre dados sintéticos, aprendizado por reforço, escalabilidade, atenção por portas e direção futura. - O pensamento não dá um bom suporte aos casos de uso de codificação. O comprimento do contexto é de 256 KB, mas mesmo 128 KB seriam suficientes para agentes de codificação, já que o código é filtrado antes de ser adicionado ao contexto. Dito isso, a API suporta 1 milhão de tokens. - O Qwen 2.5 Coder auxiliou na geração de dados sintéticos com o Qwen 3 Coder. Isso envolveu a coleta de dados ruidosos, sua limpeza e reescrita. - O ambiente de grande escala da equipe Qwen para aprendizado por reforço com o agendador MegaFlow. Eles usam múltiplos scaffolds/agentes para gerar trajetórias (interessante). - O desempenho em RL aumenta significativamente, então os esforços valem a pena. - O Qwen3-Max alcançou um grande sucesso de vendas na Alibaba. Não apresenta muitas inovações, mas possui uma escalabilidade muito maior. Isso se deve inteiramente à sua capacidade de escalonamento. - A próxima geração de LLMs Qwen terá Atenção Delta com Portão, dado o sucesso do Qwen3-Next. Eles também podem combinar técnicas de Atenção Esparsa (DSA?). - Direção futura 1. Nova arquitetura para contexto longo 2. Recursos de pesquisa integrados 3. Incorporação da visão em modelos de codificação para agentes de uso de computador 4. Técnicas para tarefas de longo prazo (24 horas ou mais)