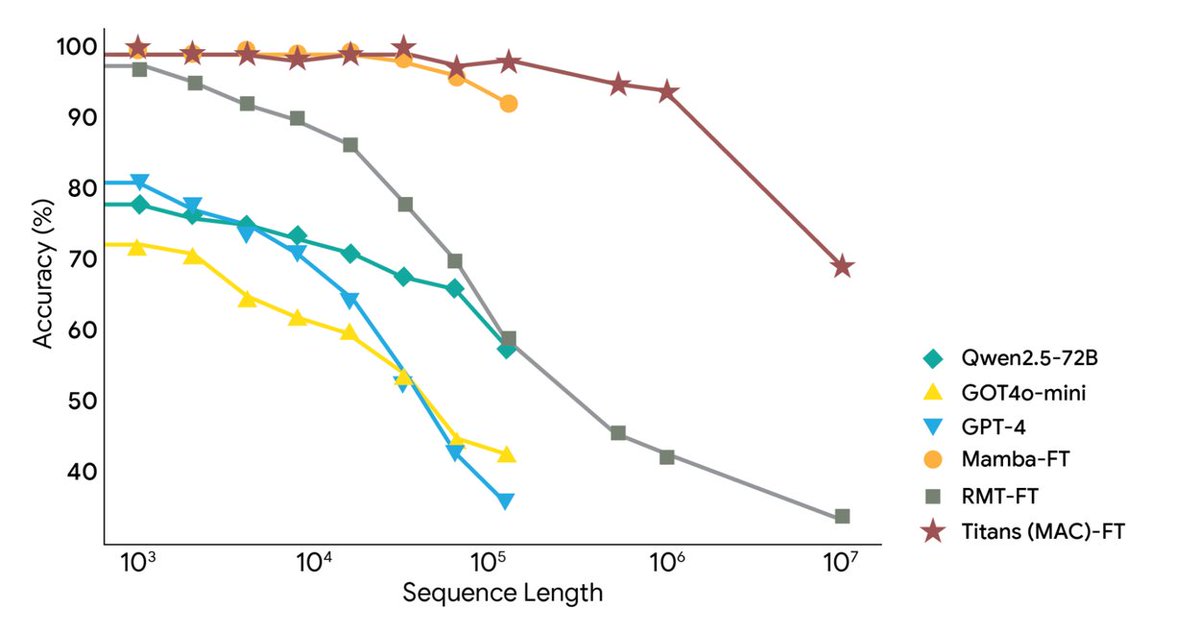
O Google Research lançou hoje duas novas estruturas: a arquitetura Titans e a estrutura MIRAS, que abordam os desafios do contexto extremamente longo e da memória de longo prazo da IA, estendendo o contexto para mais de 2 milhões de tokens. Utiliza memória neural profunda para aprendizado em tempo real, permitindo que modelos grandes atualizem sua memória de longo prazo em tempo real durante a execução, alcançando assim a velocidade das RNNs e a precisão dos Transformers. O Titans permite que a IA atualize seu módulo de memória de longo prazo em tempo real durante a execução. O MIRAS fornece um modelo teórico para um sistema de memória unificado. O Titans utiliza um perceptron multicamadas (MLP) para criar memória de longo prazo, em vez dos vetores fixos de uma RNN tradicional. Para cada nova palavra lida, o "nível de surpresa" é calculado; palavras irrelevantes são ignoradas, enquanto aquelas relevantes são armazenadas na memória de longo prazo e os parâmetros do MLP são atualizados de acordo. Para controlar a capacidade, foi adicionado o recurso de decaimento de peso, que elimina automaticamente informações antigas e irrelevantes. Em última análise, a camada de Atenção pode recuperar a memória de longo prazo "sob demanda" ou analisar apenas o contexto mais recente. O MiRAS oferece uma perspectiva unificada, argumentando que os modelos de sequência convencionais estão essencialmente resolvendo o mesmo problema: como combinar eficientemente novas informações com memórias antigas sem esquecer informações importantes. Todos eles são formas diferentes de sistemas de "memória associativa". Ele divide o sistema de memória de um modelo de IA em quatro partes principais: estrutura de memória, viés de atenção, mecanismos de retenção e algoritmo de memória. Além disso, propõe-se a utilização de métodos matemáticos mais complexos e sofisticados para o julgamento, o que permitiria o desenvolvimento de um sistema de memória mais poderoso e robusto. Experimentos mostram que o Titans supera o Transformer++, o Mamba-2 e o Gated DeltaNet de escala semelhante em modelagem de linguagem, raciocínio de senso comum, modelagem de DNA, previsão de séries temporais e na tarefa BABILong de 2 milhões de tokens, e até mesmo supera o GPT-4. #Memória de IA #Titãs