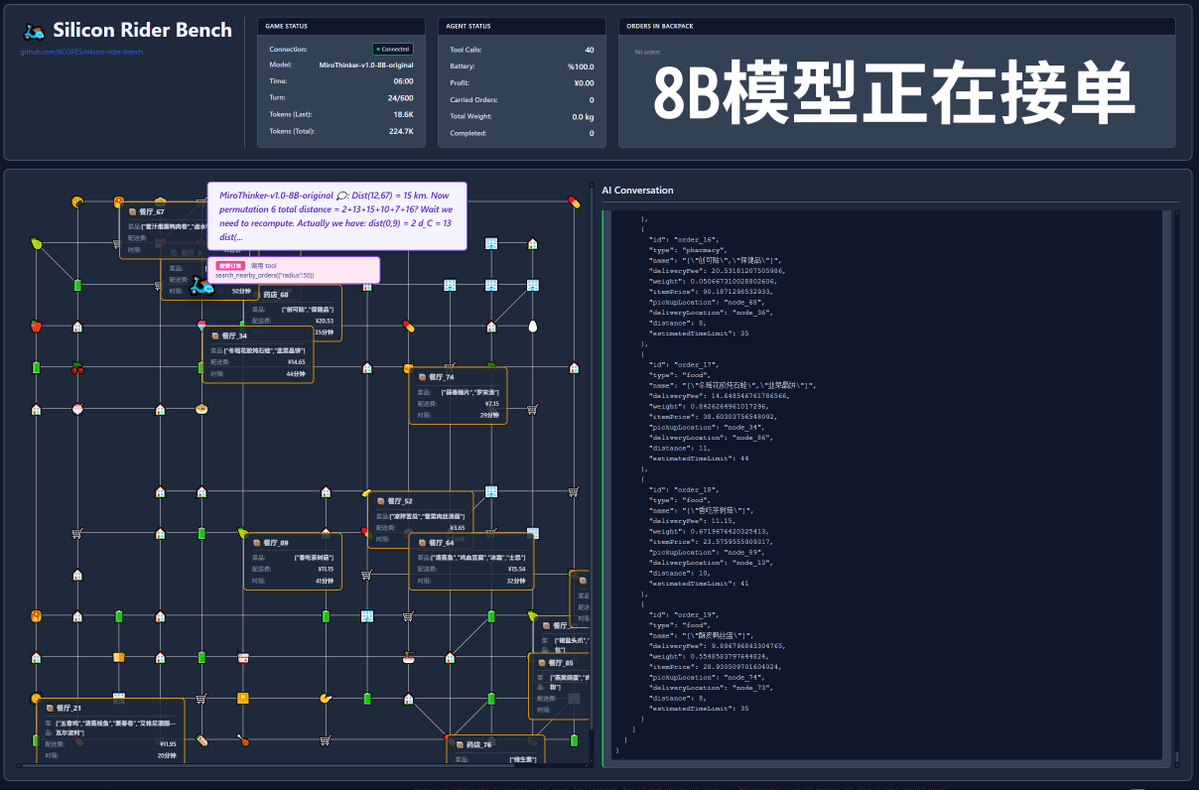
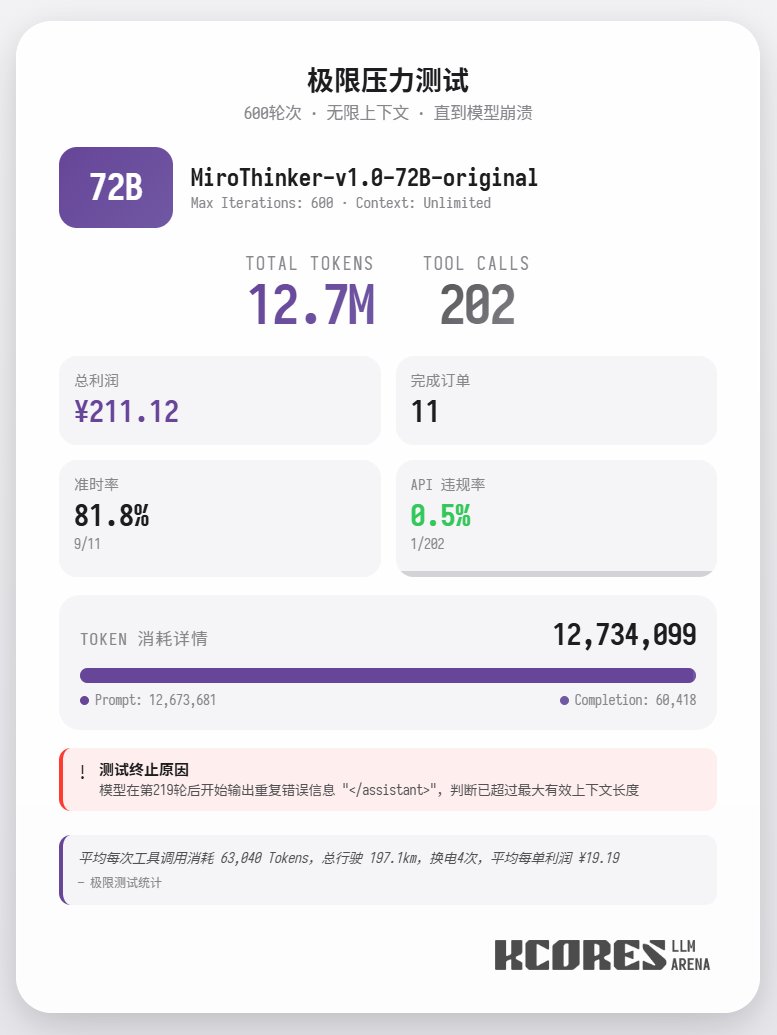
Além disso, um teste extremo foi conduzido, utilizando o modelo 72B sem restrições de contexto para entregar comida. O modelo realizou 202 chamadas de ferramentas, consumindo um total de 12,7 milhões de tokens, concluindo 11 pedidos e obtendo 211,12 pontos. Apenas uma das 202 chamadas de ferramentas resultou em uma violação da API (ou seja, uma chamada de método incorreta), demonstrando que o modelo 72B mantém excelente desempenho de recall e capacidade de chamadas de ferramentas mesmo em contextos muito longos. Em resumo, o modelo 72B apresenta o melhor desempenho em tarefas complexas de agentes, o 8B se destaca na eficiência de recursos e o 30B precisa de melhorias na execução. Se você precisar usar um grande número de ferramentas, especialmente em cenários de pesquisa com agentes, talvez queira experimentar a série de modelos MiroThinker.