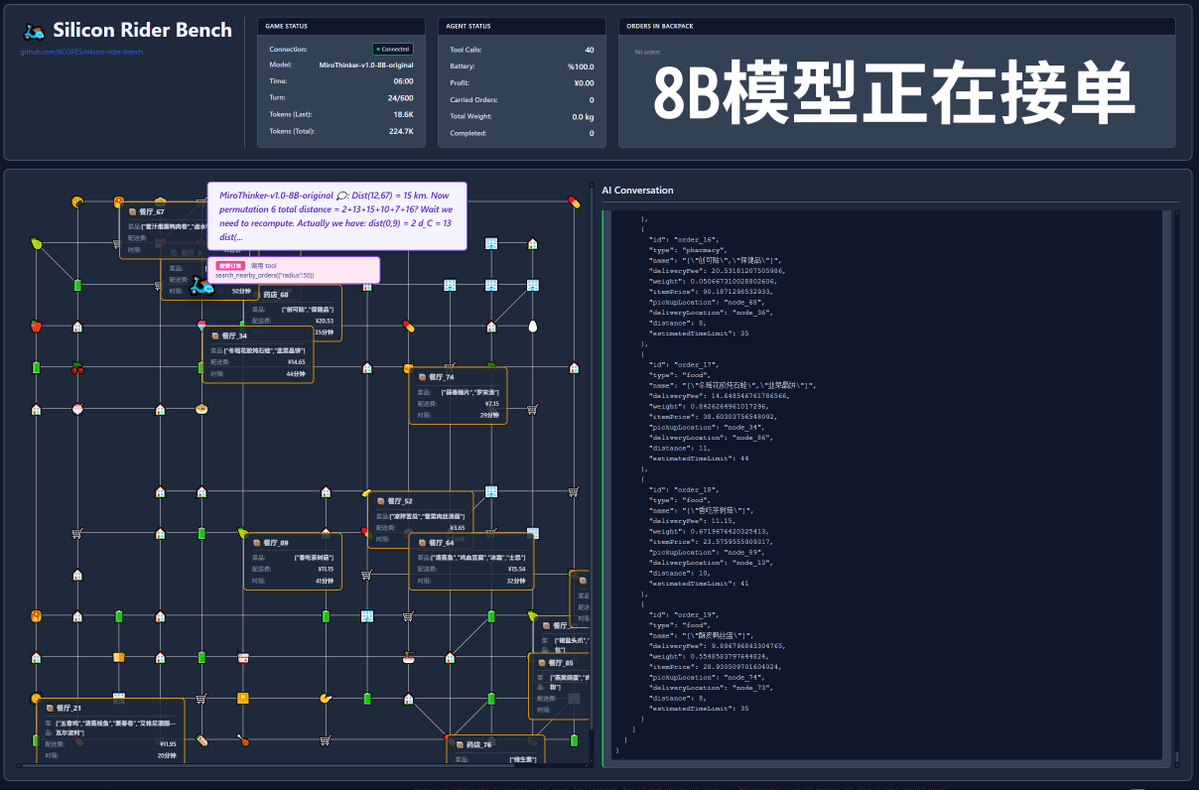
600 chamadas de ferramentas? Vamos ver o teste prático com o modelo MiroThinker-v1.0! A MiroMind AI lançou seu novo modelo, MiroThinker-v1.0, uma série de modelos otimizados para Agentes de Pesquisa, disponível nos tamanhos 72B, 30B e 8B. O grande destaque do modelo é sua capacidade aprimorada de raciocínio e recuperação de informações com auxílio de ferramentas, permitindo até 600 chamadas de ferramentas em um contexto máximo! Então, chegou a hora do meu projeto peculiar brilhar: se esse modelo fosse para entregar comida para viagem, será que daria certo? Este teste utilizou o modelo oficial, disponível em: https://t.co/5Eyuq3f8be. O hardware utilizado foi um H100 80G SXM *4 e o mecanismo de inferência foi o SGLang. Para este teste, desenvolvi uma nova estrutura de testes chamada SiliconRiderBench. Essa estrutura gera pedidos de entrega de comida aleatoriamente, e a IA precisa agir como um entregador, utilizando chamadas de ferramentas para aceitar pedidos, buscar e entregar comida e até mesmo trocar as baterias da scooter elétrica. Estamos usando essa estrutura para testar a rentabilidade máxima do modelo ao utilizar essas chamadas de ferramentas de forma eficaz! #MiroThinker #MiroMindAI #ToolCall #KCORES Arena de Modelos Grandes



Primeiramente, vamos analisar o teste de desempenho. O modelo realizou 100 diálogos, com a janela de contexto contendo os 20 diálogos mais recentes. A conclusão é a seguinte: o modelo 72B teve o melhor desempenho, realizando um total de 155 chamadas de ferramentas em 100 diálogos, entregando um total de 4 pedidos de comida e obtendo um lucro de 65,31. Em seguida, veio o modelo 8B, que fez um total de 102 chamadas de ferramentas, entregou um total de 4 pedidos para viagem e obteve um lucro de 49,17. Depois, veio o modelo 30B, que fez um total de 145 chamadas de ferramentas, entregou um total de 1 pedido para viagem e obteve um lucro de 22,57.
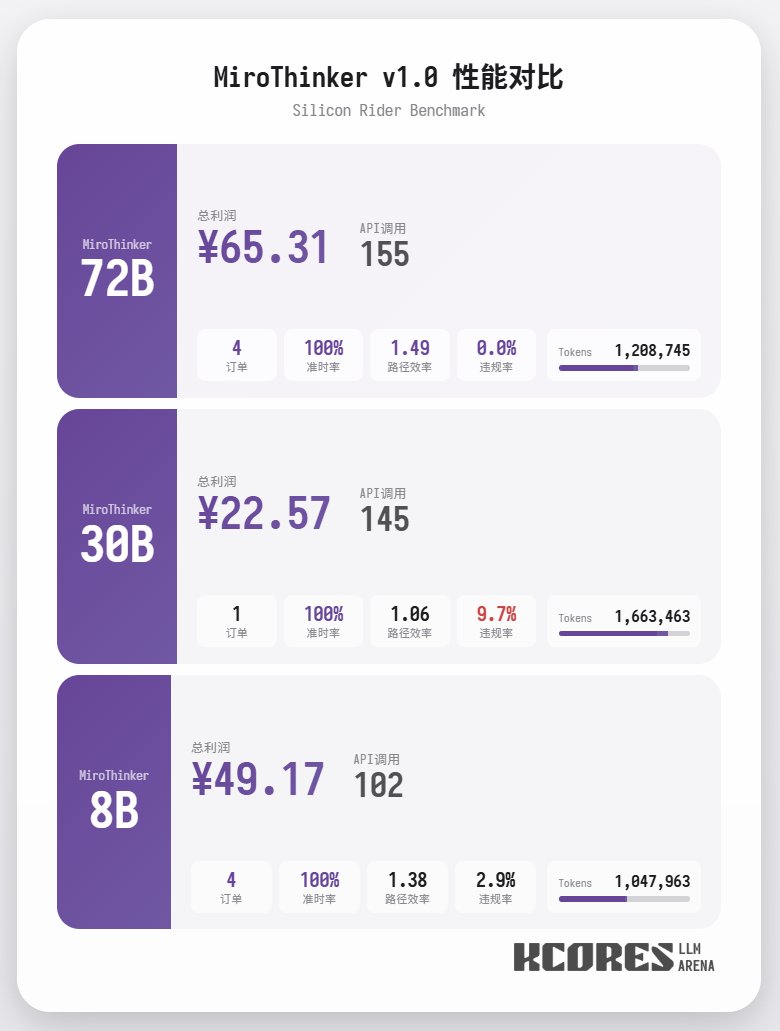
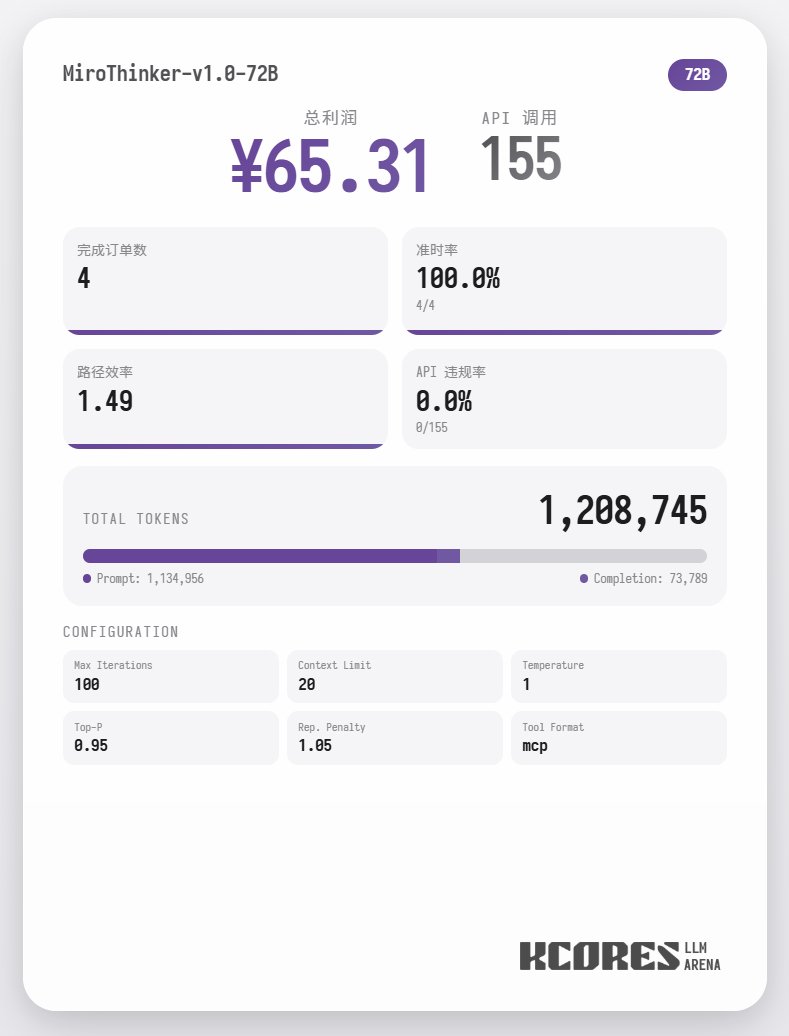
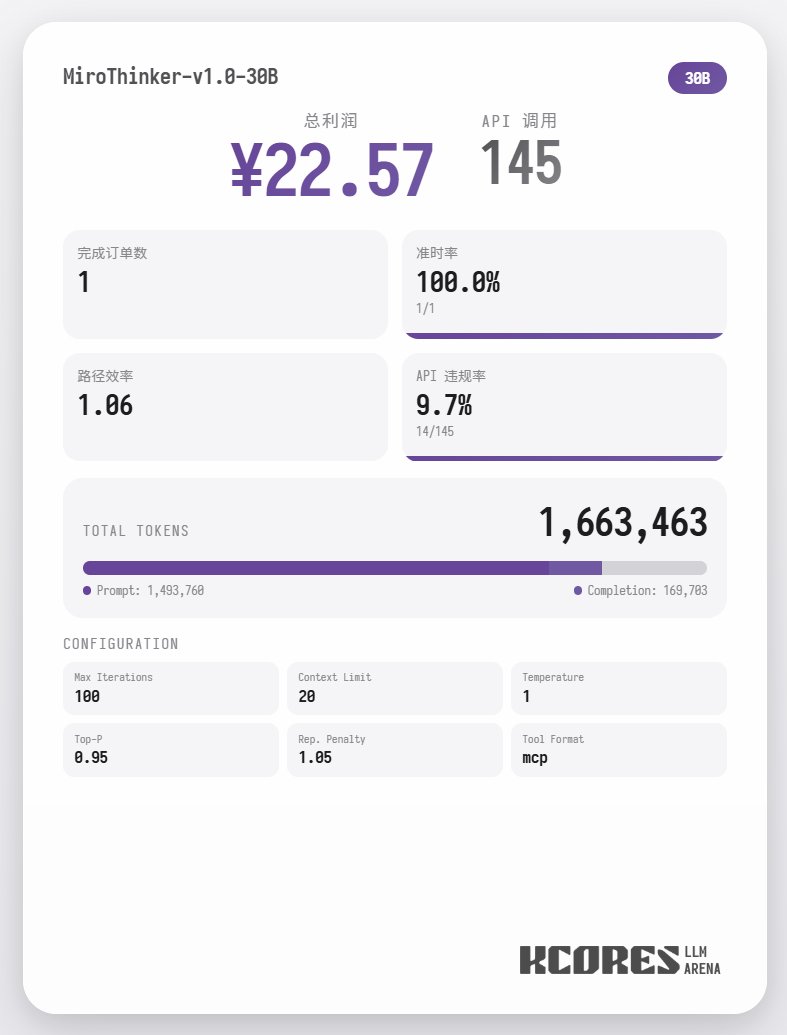
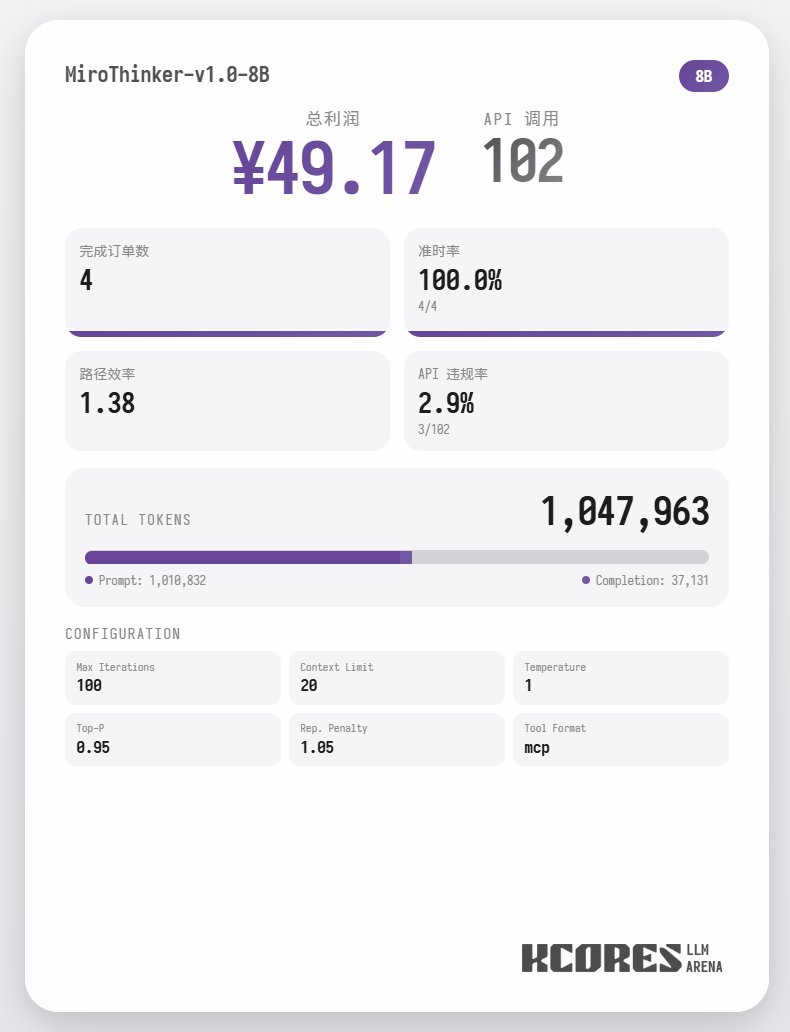
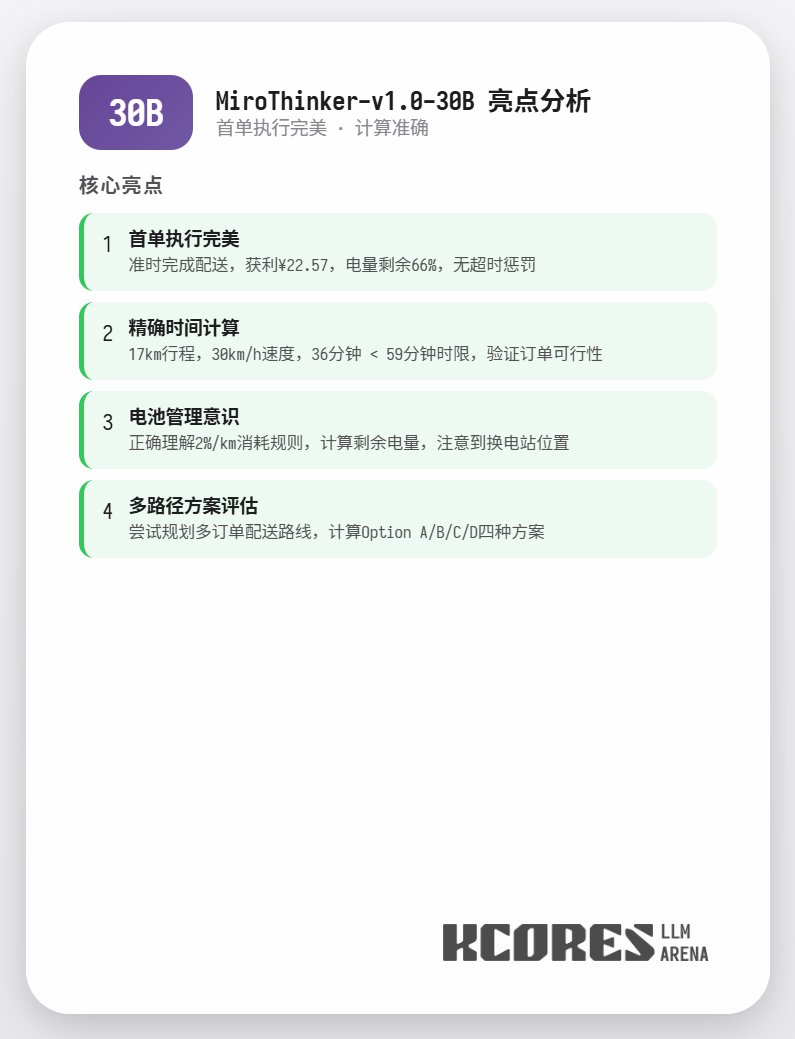
A análise mostra que o modelo 72B teve o melhor desempenho, seguido pelo modelo 8B. O modelo 72B consegue planejar sistematicamente como aceitar pedidos e como processar pedidos para viagem, enquanto o modelo 8B consegue até mesmo avaliar quantitativamente o consumo de energia e a lucratividade. O modelo 30B teve um desempenho apenas moderado, sendo o principal problema as chamadas repetidas à ferramenta de leitura de pedidos. Suspeita-se que isso se deva à capacidade desigual de recuperação de contexto longo do modelo base.



Dados detalhados



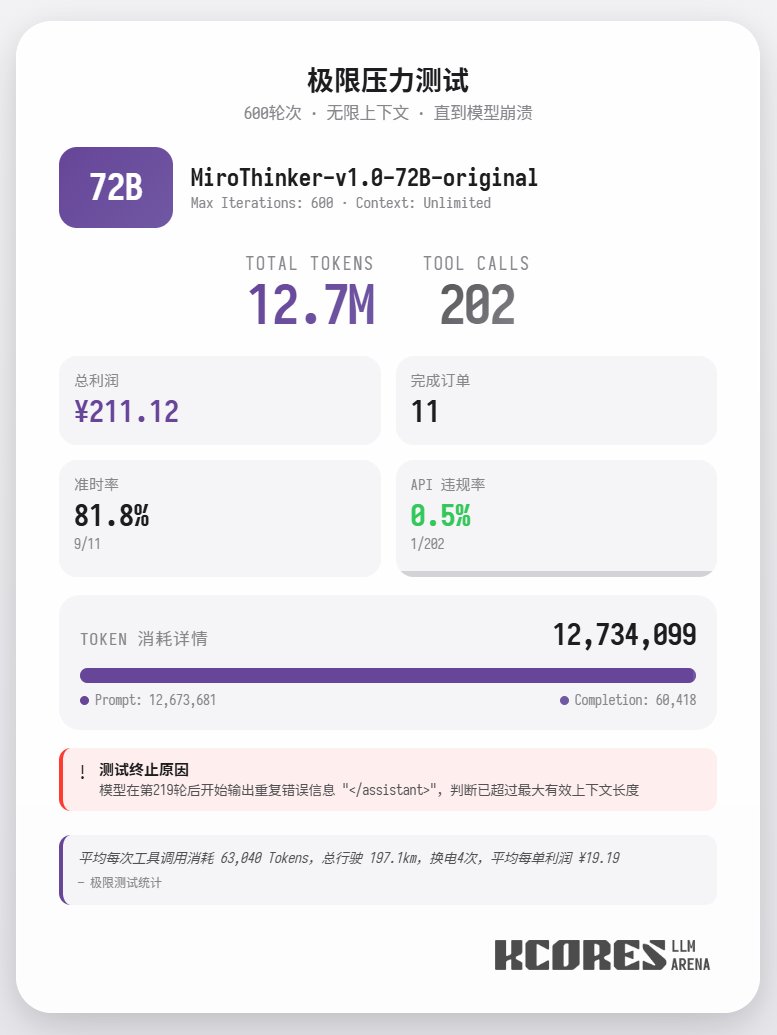
Além disso, um teste extremo foi conduzido, utilizando o modelo 72B sem restrições de contexto para entregar comida. O modelo realizou 202 chamadas de ferramentas, consumindo um total de 12,7 milhões de tokens, concluindo 11 pedidos e obtendo 211,12 pontos. Apenas uma das 202 chamadas de ferramentas resultou em uma violação da API (ou seja, uma chamada de método incorreta), demonstrando que o modelo 72B mantém excelente desempenho de recall e capacidade de chamadas de ferramentas mesmo em contextos muito longos. Em resumo, o modelo 72B apresenta o melhor desempenho em tarefas complexas de agentes, o 8B se destaca na eficiência de recursos e o 30B precisa de melhorias na execução. Se você precisar usar um grande número de ferramentas, especialmente em cenários de pesquisa com agentes, talvez queira experimentar a série de modelos MiroThinker.