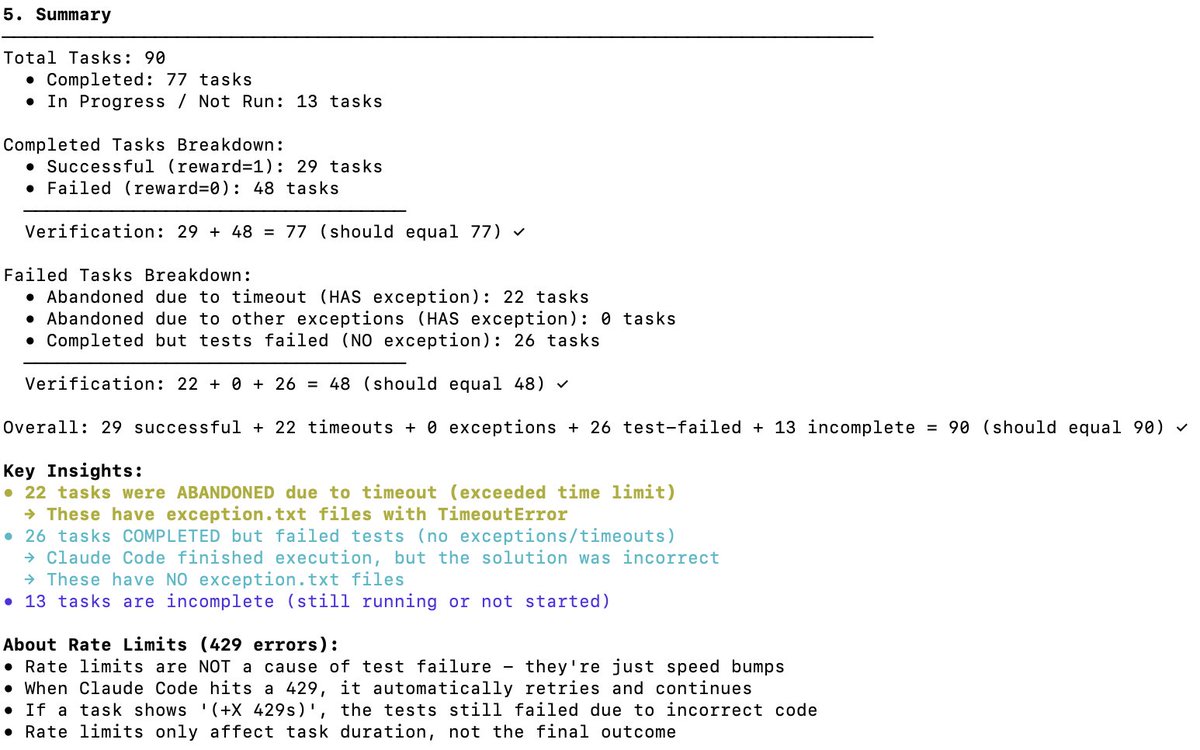
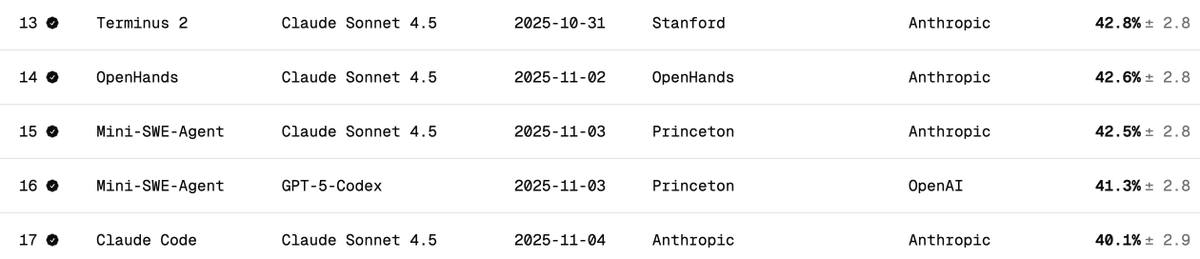
Verificação independente do desempenho do DeepSeek V3.2 no Terminal Bench 2. O Terminal Bench mede como um modelo suportará/executará um agente em um cenário de terminal (por exemplo, Claude Code, Codex CLI, Gemini CLI). Na minha opinião, este é o benchmark LLM mais importante para o desenvolvimento de software de IA. Ele envolve a IA operando sua CLI para baixar software, desenvolver código, testar etc. Qual é o placar oficial? A pontuação oficial do DeepSeek v3.2 é 46,4 (Raciocínio) e 37,1 (Não Raciocínio), conforme mencionado na tabela abaixo. Eles utilizaram o framework Claude Code, como relatado no artigo. Qual o desempenho do Claude Code + Sonnet 4.5 neste teste de benchmark? Abaixo estão os resultados dos testes de desempenho do Claude Sonnet 4.5 em diferentes configurações. Observe que o resultado para a configuração Claude Code é de aproximadamente 40%. Quais foram as minhas pontuações no DeepSeek V3.2 com o Claude Code Harness? Realizei testes com o DeepSeek-Reasoner (Thinking). De quase 90 testes, 77 foram executados antes que o Harbor (orquestrador) parasse de funcionar. 77 é um bom número para se ter uma ideia, assumindo que sejam amostras não enviesadas. - 29 - Obtido com sucesso - 48 - Falha (22 tempos limite + 26 códigos incorretos gerados) Isso eleva a pontuação para 38% (bastante impressionante, e já próxima de Claude Code + Sonnet 4.5, com 40%). Mas o que é certo é que, se o modelo DeepSeek v3.2 tivesse mais tempo, certamente conseguiria concluir mais tarefas que expiraram, ficando bem acima de 38% — eu diria que poderia chegar a 50%. Mas aí a comparação deixaria de ser justa (os criadores do teste desaconselham alterar as configurações de tempo limite). Comparação com outros modelos de código aberto: Os modelos abaixo utilizam o chicote Terminus 2. 1. Kimi K2 Thinking - 35,7% 2. MiniMax M2 - 30% 3. Qwen 3 Coder 480B - 23,9% Conclusão: O desempenho é de última geração para um modelo de código aberto, e é incrível que quase se iguale ao Claude 4.5; no entanto, minha pontuação foi inferior à da equipe DeepSeek: 46,4 (novamente, os últimos 13 testes não foram executados). Suspeito que eles possam ter modificado o comportamento do código Claude. O código Claude envia lembretes ao modelo de maneiras específicas (por exemplo, como ) com as quais o DeepSeek v3.2 pode não estar familiarizado ou não lidar tão bem. Foi ótimo saber que o DeepSeek possui um endpoint de API antropomórfica; isso facilitou bastante os testes com o Claude Code. Eu só precisei colocar o arquivo settings.json no Docker. A DeepSeek (@deepseek_ai) deveria compartilhar de forma transparente como alcançou essas pontuações. Custo e acessos ao cache: Esta é a parte mais incrível. Custou-me apenas 6 dólares para executar os 77 testes (o Harbor desistiu dos últimos 13 por algum motivo). Quase 120 milhões de tokens foram processados, mas como a maioria dos tokens estava na entrada e depois teve acessos ao cache (o DeepSeek implementa o cache baseado em disco automaticamente), os custos foram bastante baixos. Solicitações à equipe do Terminal Bench: Por favor, facilitem a retomada de trabalhos que foram encerrados antes da conclusão de todas as tarefas. Agradecemos por este excelente parâmetro. @terminalbench @teortaxesTex @Mike_A_Merrill @alexgshaw @deepseek_ai